mmcv
 mmcv copied to clipboard
mmcv copied to clipboard
auto_fp16 goes through torch.no_grad(), and the gradient used outside torch.no_grad() also disappears
 在no grad外面使用梯度也会消失
在no grad外面使用梯度也会消失
We recommend using English or English & Chinese for issues so that we could have broader discussion.
It looks strange. Could you provide some codes that are easy to reproduce?
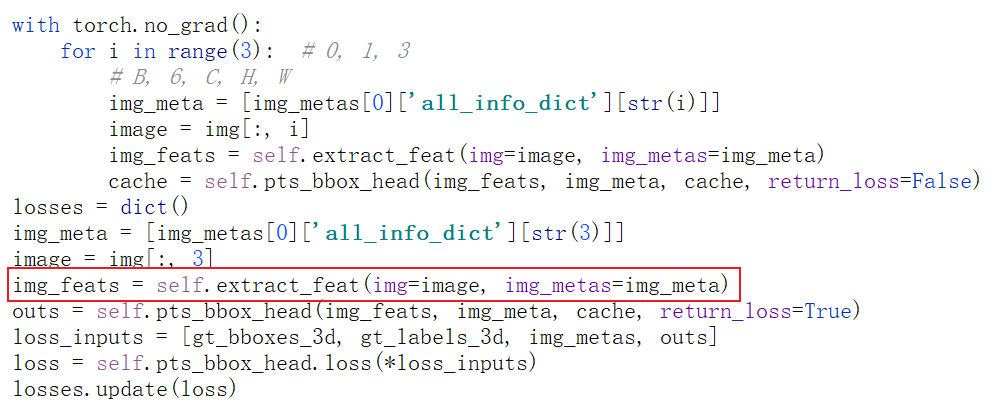
I rewrote create_data, so my dataset does not apply the official generated pkl. I think you can rewrite the dataset, input 4 frames of pictures and related information at a time, the detector part is as shown in my picture.
I tried a simple case
class MyModule1(nn.Module):
def __init__(self):
super().__init__()
self.model = nn.Sequential(*list(resnet50().children())[:-2])
@auto_fp16(apply_to=('img'), out_fp32=True)
def extract_img_feat(self, img, img_metas):
return self.model(img)
def forward(self, img, img_metas):
with torch.no_grad():
feat1 = self.extract_img_feat(img, img_metas)
feat2 = self.extract_img_feat(img, img_metas)
print('feat1.requires_grad: ', feat1.requires_grad)
print('feat2.requires_grad: ', feat2.requires_grad)
return feat2
input = torch.rand(1, 3, 224, 224)
img_metas = {}
model = MyModule1()
_ = model(input, img_metas)
And I got:
feat1.requires_grad: False
feat2.requires_grad: True
It indicates that auto_fp16 does not affect gradient calculation.
Sorry, I didn't make it clearer, this is the case with distributed training.