text-generation-webui
 text-generation-webui copied to clipboard
text-generation-webui copied to clipboard
Out of Memory, 64gb RAM RTX 3090 30b 4-bit LLaMa
Describe the bug
I can load the 13b model just fine. For some reason, when I try to load the 30b model, I run out of CPU memory.
I have 64 gigs, so that shouldn't be a problem.
Happy to provide whatever info possible, but I suspect my env is not set up properly, even though the 13b functions.
I seem to be having issues with bitsandbytes, no matter how I run the installer. I think I had a corrupt install at some point and I can't seem to fresh start. Not sure if it's an issue with the installer, or if something else is at play.
Is there an existing issue for this?
- [X] I have searched the existing issues
Reproduction
call python server.py --auto-devices --chat --wbits 4 --groupsize 128 --model_type opt --listen
Screenshot
My textgen env
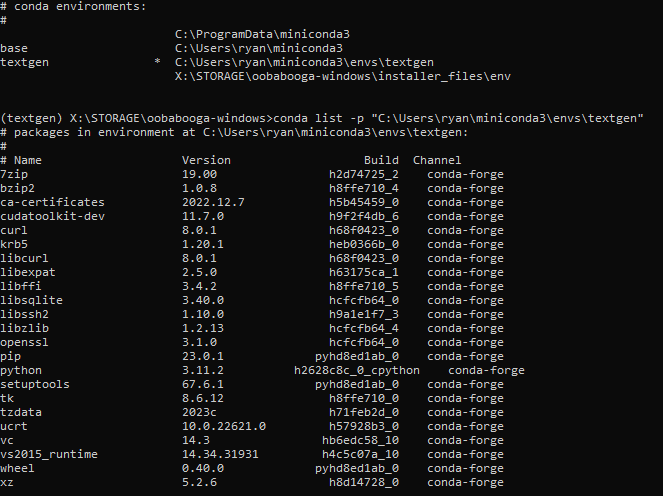
My base env

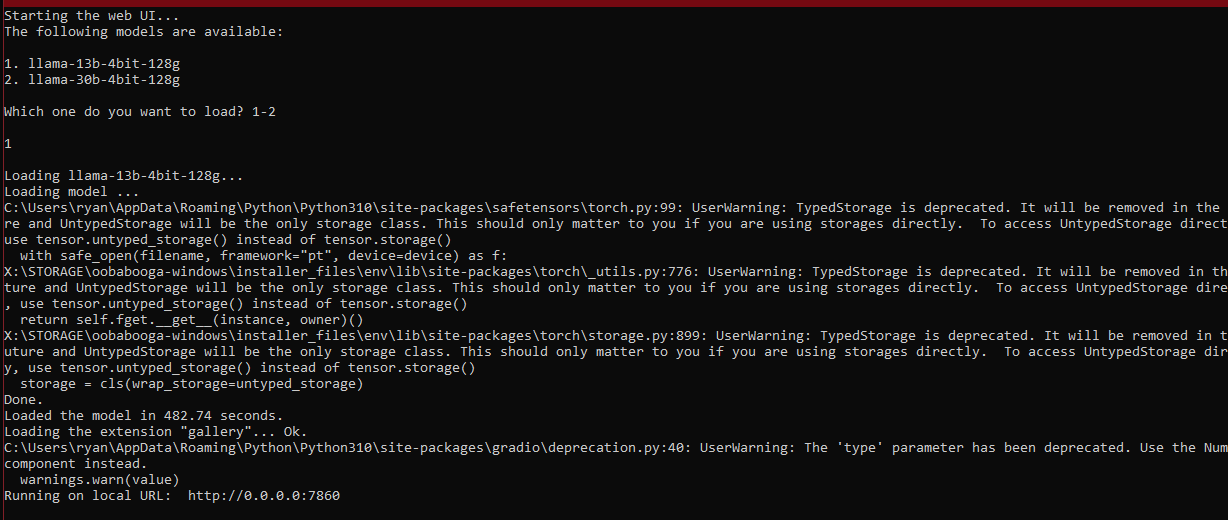
13b working
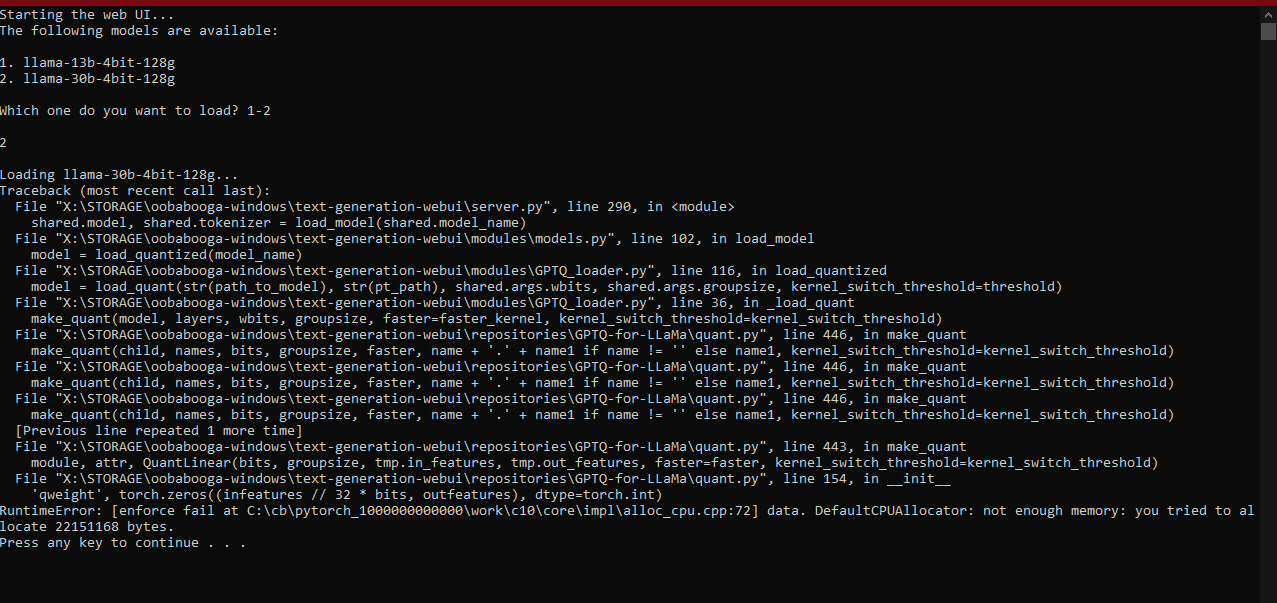
30b failing
Random install errors
Logs
No specific logs outside of screenshots
System Info
RTX 3090
10900kf
64gb RAM
Python 3.10
first of all model type should be llama
30b 4bit need way more spaces then 13b, try to use --pre_layer PRE_LAYER to offload
first of all model type should be llama
30b 4bit need way more spaces then 13b, try to use
--pre_layer PRE_LAYERto offload
Not sure what you mean by "model type should be llama". It is llama?
Secondly, I know it needs way more space than 13b but 3090 with 64gb system ram shouldn't have a problem with the 4bit 30b model should it?
first of all model type should be llama 30b 4bit need way more spaces then 13b, try to use
--pre_layer PRE_LAYERto offloadNot sure what you mean by "model type should be llama". It is llama?
Secondly, I know it needs way more space than 13b but 3090 with 64gb system ram shouldn't have a problem with the 4bit 30b model should it?
you had --model_type opt in the org post, maybe a typo
24G of vram may not be enough?
I also have 64GB of system RAM + a 3090, and I can't load 30B without allocating like 50GB of page file or swap.
I have a 4090 and can load 30B @ 4 bit so a 3090 should be able too I'd think. It should only require around 20gb of vram. What does nvidia-smi say?
It doesn't look like it's even trying to use your GPU, so your CUDA setup might not be working. Make sure that you did everything that needs to be done for WSL to make it work.
With respect to system RAM, WSL has a limit of its own to prevent it from encroaching on the host too much. This can be changed via .wslconfig.
This issue has been closed due to inactivity for 6 weeks. If you believe it is still relevant, please leave a comment below. You can tag a developer in your comment.