Extension: Stable Diffusion Api integration
Description:
Lets the bot answer you with a picture!
Load it in the --cai-chat mode with --extension sd_api_pictures alongside send_pictures (it's not really required, but completes the picture).
If enabled, the image generation is triggered either:
- manually through the extension buttons OR
- IF the words
'send | mail | me'are detected simultaneously with'image | pic | picture | photo'
One needs an available instance of Automatic1111's webui running with an --api flag. Ain't tested with a notebook / cloud hosted one but should be possible. I'm running it locally in parallel on the same machine as the textgen-webui. One also needs to specify custom --listen-port if he's gonna run everything locally.
For the record, 12 GB VRAM is barely enough to run NeverEndingDream 512×512 fp16 and LLaMA-7b in 4bit precision. TODO: We should really think about a way to juggle models around RAM and VRAM for this project to work on lower VRAM cards.
Extension interface
 Don't mind the Windranger Arcana key in the Prompt Prefix, that's just the name of an embedding I trained beforehand.
Don't mind the Windranger Arcana key in the Prompt Prefix, that's just the name of an embedding I trained beforehand.
Demonstrations:
Conversation 1
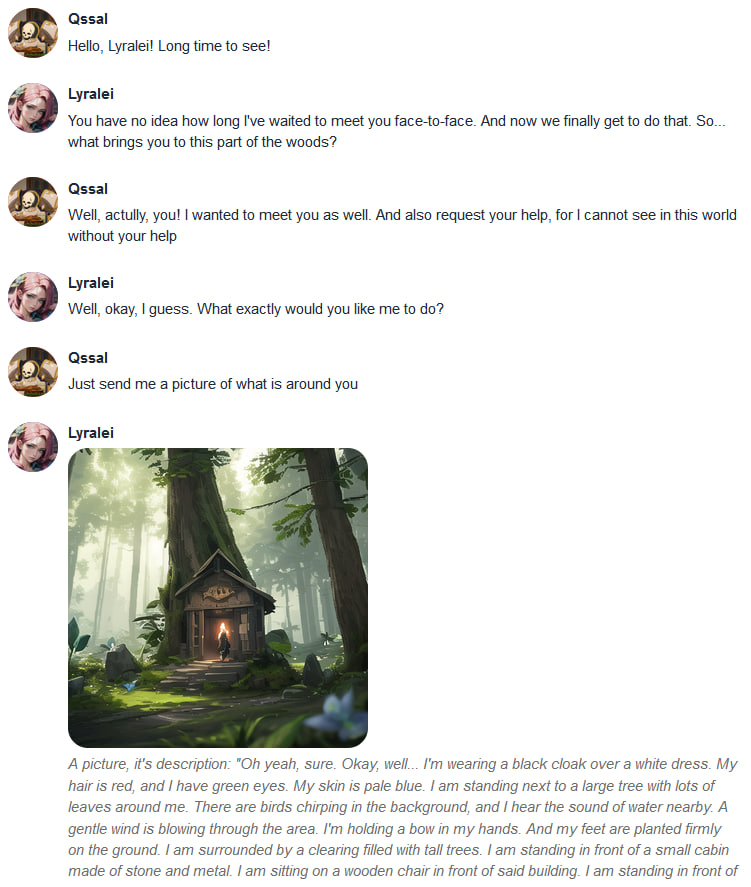
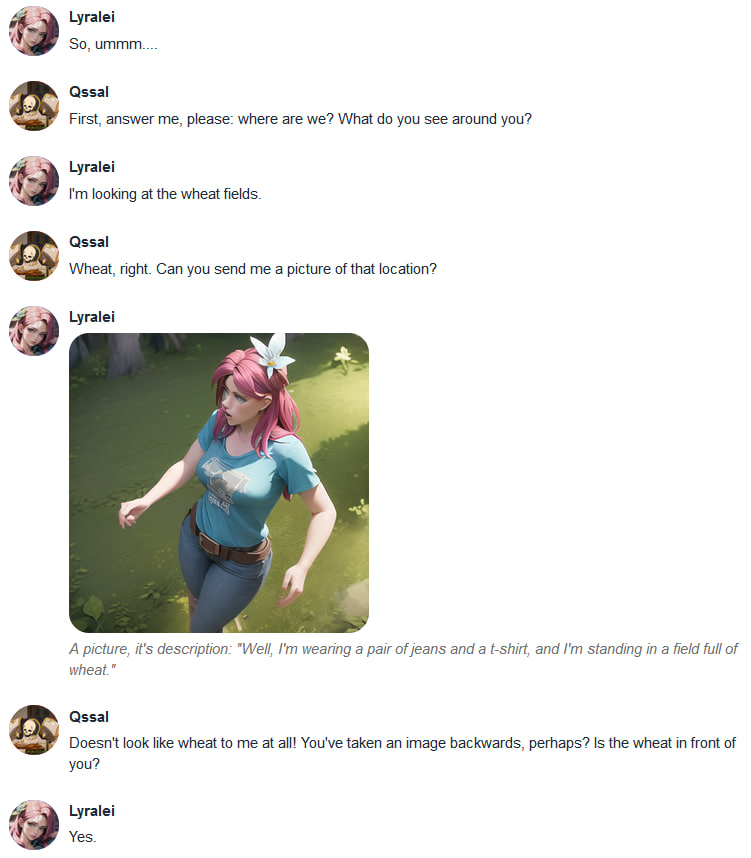
Conversation 2
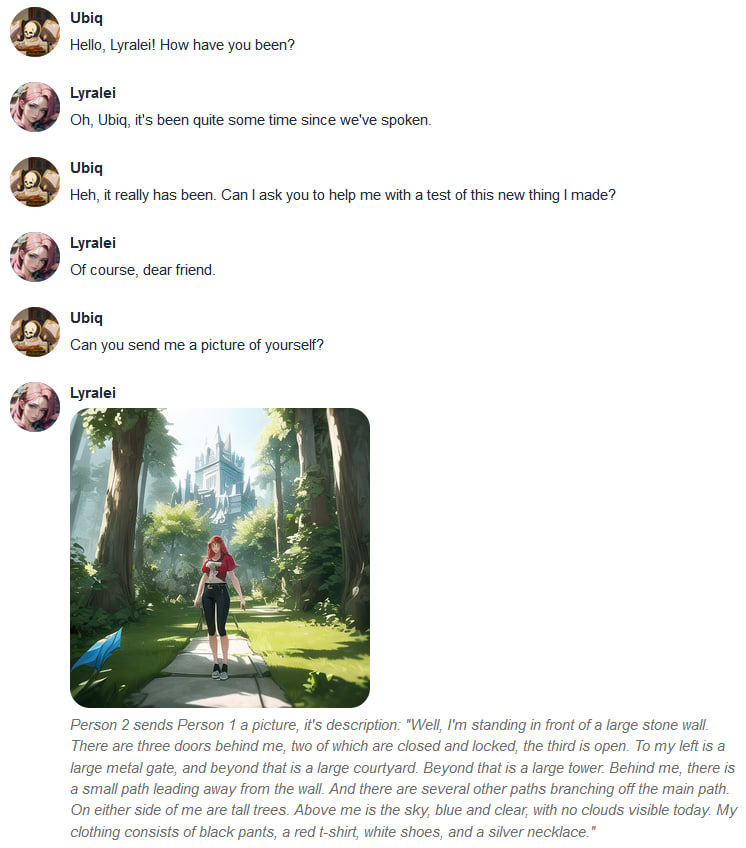
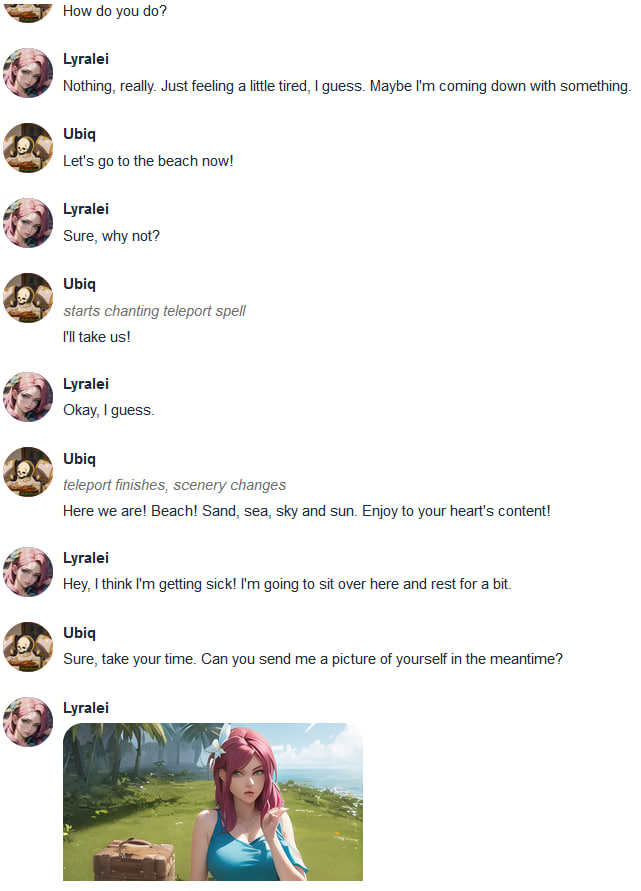
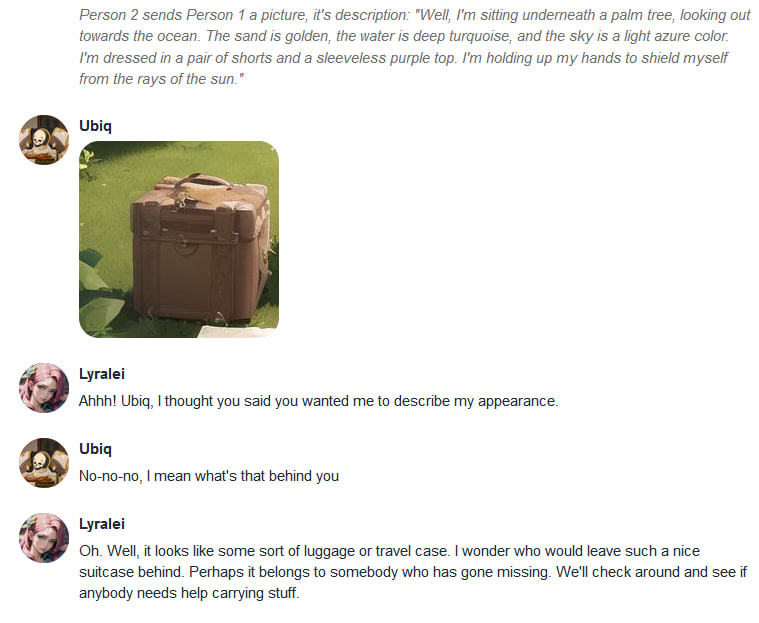
Very nice.
Idea: Can you image to image the profile picture for any detected expression changes?
something like:

I couldn't test the extension so far, probably because I don't have the 'NeverEndingDream' model installed. I will try again later.
I couldn't test the extension so far, probably because I don't have the 'NeverEndingDream' model installed. I will try again later.
:D
It's gonna use the last model something was generated with by default; you don't even need to have any particular one present.
I haven't really even implemented the ability to specify a model because it's a separate API call
This is extremely amusing. It just worked in the end, all I had to do was tick "Activate SD Api integration" and change the host address to http://192.168.0.32:7861 where 192.168.0.32 is the IP of the machine where I am running stable diffusion.


Yeass!! I was able to get this to work, but I had to remove the "modules.py" and "modules-1.0.0.dist-info" folder from my textgen environment for it to work. I'm 'running on windows without wsl.
Yeah modules is listed in the list of requirements for the extension but it will conflict with the modules/ folder in the textgen webui directory. Please consider removing this in a commit.
This sounds great! We just need a little bit more information to avoid guessing at how to get them to communicate.
Here's my Stable Diffusion launch line: ./webui.sh --no-half-vae --listen --port 7032 --api
And here's my Ooba text gen launch: python server.py --model opt-1.3b --cai-chat
I don't think this will make them talk. Both programs are running on the same machine in the same browser in two different tabs. How should those lines read to allow textgen to utilize Stable Diffusion?
And if I need to know my local machine's IP, how do I do that? If you can answer those questions, maybe we could put the answers in the wiki so people don't bug you about it.
Yea, VRAM probably is the problem, you cant really host 2 VRAM eaters in the same consumer machine. That's another reason for moving the chatting AI to CPU (supported by AVX2) like the llama.cpp (https://github.com/ggerganov/llama.cpp) /alpaca.app (https://github.com/antimatter15/alpaca.cpp) projects, so we consume RAM instead of VRAM.
But text-generation-webui seems not supported yet and some people are working on the integration: https://github.com/oobabooga/text-generation-webui/pull/447
If that's done, I guess this extension would be more usable in average consumer machines.
@St33lMouse
And if I need to know my local machine's IP, how do I do that?
You don't; if you're running them on the same machine you can use a special address 127.0.0.1 which basically means 'on this machine' for any network. So in your case, just go to ooba's extension tab, tick the API checkbox to enable and change the address to 127.0.0.1:7032 - it should work out of the box
Ok, so my problem seems to be with Auto having SSL as I am getting a "[SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: self signed certificate" Error, any suggestions?
@JohnWJarrett
What are your launch parameters for both repos and how do you usually open the Auto1111's webUI? Through the https://, I presume?
My TGWI params are (When trying to use SD along side)
python server.py --auto-devices --gpu-memory 5 --cai-chat --listen --listen-port 8888 --extension sd_api_pictures send_pictures
and my WUI params are
--xformers --deepdanbooru --api --listen --listen-port 8880
And yes, i use the SSL addon for WUI so yeah, through https
Thanks! I haven't yet tested if the API works correctly when used through https, and that probably is the root cause of the issue. You could try temporarily disabling SSL for WUI; please report if it works in that state.
I'll try to look for the fix for https in the meantime
I am working on trying integration of some multimodal models like mm-cot or nvidia prismer currently. Maybe it would be possible to have a common interface for picture handling? Both receiving and sending.
@Brawlence, yeah, it get's past the cert error if I disable the SSL, but then I got a different error, one that I actually have a solution for... So, seeing as I am using a different port than WUI's default, I just copied and pasted the new url (http://127.0.0.1:8880/) into the settings on TGW, which I am guessing you might see the issue, or you might not, I didn't for about an hour until I was looking into the log and tried, on a whim, to do "localhost:8880" which gave me this error
requests.exceptions.InvalidSchema: No connection adapters were found for 'localhost:8880//sdapi/v1/txt2img'
which is when I noticed the "8880//sdapi", so I think you should truncate the trailing "/" in the IP if the user accidentally leaves it there, it was a thing I overlooked and I'm sure I wont be the only one, it's a stupid user error, sure, but I'd imagine it'd be an easy fix? I don't know, I hate Python with a passion so I never bothered learning it that much.
But other than that, yeah, it works fine, even on my 8GB GFX, I am not gonna try push it for anything over 256 images, but then again, I don't really need to, it's more just for the extra fun than anything.
EDIT: Also, while playing around, and this is just some general info for anyone who was wondering, you can put a LoRa into the "Prompt Prefix" and it will work, which would be good for getting a very consistent character.
@Brawlence I've made some updates that I'd be happy to share!
Now one can optionally use 'subject' and 'pronoun' that will replace I have and My in the prompt sent to SD. This produces way better results on a wider-array of SD models and/or lets users with embeddings or Dreambooth models to specify their unique token.
Also added a Suffix field so that someone can better dial in other details of the scene if they want.
What I'd like to do next is actually read this information out of the Character json schema so that all a person has to do is load up their Character and the correct class and subject tokens are set. Heck, could even provide for model hash in that too...
I'm also able to get SD models working, but unfortunately I can't find where in the SD API that allows you to set the model.

@JohnWJarrett
I think you should truncate the trailing "/" in the IP if the user accidentally leaves it there, it was a thing I overlooked and I'm sure I wont be the only one, it's a stupid user error, sure, but I'd imagine it'd be an easy fix?
Thanks for your feedback! Here's a preview for the upcoming change:

It's gonna strip the http(s):// part and the trailing / if present and also return the status when pressing Enter in that field
@karlwancl
you cant really host 2 VRAM eaters in the same consumer machine
But yes one can! I have already tested the memory juggling feature (see #471 and AUTOMATIC1111/stable-diffusion-webui/pull/8780) and if both of those patches are accepted then it would be possible to:
- unload LLM to RAM,
- load Stable Diffusion checkpoint,
- generate the image and pass it to oobabooga UI,
- unload the SD checkpoint,
- load LLM back into VRAM
— all at the cost of ~20 additional seconds spent on shuffling models around. I've already tested it on my machine and it works.
Demo
 As you can see, it successfully performs all the above steps, at least on my local rig with all the fixes implemented.
As you can see, it successfully performs all the above steps, at least on my local rig with all the fixes implemented.
Of course, I'd be more than happy to have llama.cpp implemented as well, more options are always better
My current opinion: while llama.cpp uses CPU and RAM, and SD uses GPU and VRAM. These two will not conflict with each other. For now, llama cares more about the size of the RAM/VRAM and GPU acceleration is not obvious, and in most PCs RAM is much larger than VRAM.
Hi, I am having some trouble in getting this extension to work. I always get the same error.
File "C:\Users\user\text-generation-webui\extensions\sd_api_pictures\script.py", line 85, in get_SD_pictures for img_str in r['images']: KeyError: 'images'
Now, it seems that the key "Images" in the directory r is not existing. How can I fix this? (I am new to github, sorry if I posted this in the wrong place. I don't find the same issue under issues.
Thank you for your answer.
@Andy-Goodheart it looks like the SD API is not responding to your requests. Make sure that the IP and port under "Stable Diffusion host address" are correct and that SD is started with the --api flag.
@oobabooga Thanks a lot! =) That solved it for me. I didn't have the --api Argument in the webui-user.bat file.
 Any idea why i always recieve such creepy pics? ^^
Any idea why i always recieve such creepy pics? ^^
@DerAlo Hmmmmm. What SD model do you use? Try generating the description verbatim in Auto1111's interface, what do you get there?
For me, such pictures are usually generated either when the model tries to do something it was not trained on OR when CFG_scale is set too high
@DerAlo Hmmmmm. What SD model do you use? Try generating the description verbatim in Auto1111's interface, what do you get there?
For me, such pictures are usually generated either when the model tries to do something it was not trained on OR when CFG_scale is set too high
Its strange - in 1111's interface everythin' is fine.. Model is 'SD_model': 'sd-v1-4' and cfg is at 7.... i really dont get it^^ but thx 4 ur reply :)
anyone could write a tutorial for this extension, i can't strat this without error (rtx 3070) :(
@francoisatt what's the error, what's the parameters on the launch, what models do you use and how much VRAM you got?
I have this extension running and it seems like it is working as intended- -The bot types something -SD using that as a prompt to generate an image -The image appears in the chat, and also in the /sd_api_pictures/outputs directory.
However, the output .PNG images do not have any Stable Diffusion metadata., which is very unfortunate.
Hello,
I use the one click installer,my .bat:

on the web interface, when i Activate SD Api integration, and i click "generate an image reponse", i obtain this error:

My configuration is: i7-11800H ram 16go and rtx3070 vram 8go .
thanks for your help.