text-generation-webui
 text-generation-webui copied to clipboard
text-generation-webui copied to clipboard
RuntimeError: CUDA error: CUBLAS_STATUS_NOT_INITIALIZED when calling `cublasCreate(handle)`
Hi guys,
First of all thank you for your work.
I had tried to setup webui and its starts fine. But any request to generate ends with the same error.
Any ideas how to fix it?


Those are two different errors. I don't know what the first is, but the second means that your GPU ran out of memory.
I'm receiving what looks like the same error:
bash start-webui.sh Loading the extension "gallery"... Ok. The following models are available:
- gpt-j-6B
- gpt4chan_model_float16
- opt-1.3b
- opt-2.7b
- pygmalion-6b
Which one do you want to load? 1-5
2
Loading gpt4chan_model_float16... Auto-assiging --gpu-memory 11 for your GPU to try to prevent out-of-memory errors. You can manually set other values. Loaded the model in 41.19 seconds. Running on local URL: http://127.0.0.1:7860
To create a public link, set share=True in launch().
Exception in thread Thread-3 (gentask):
Traceback (most recent call last):
File "/home/robert/one-click-installers-oobabooga-linux/installer_files/env/lib/python3.10/threading.py", line 1016, in _bootstrap_inner
self.run()
File "/home/robert/one-click-installers-oobabooga-linux/installer_files/env/lib/python3.10/threading.py", line 953, in run
self._target(*self._args, **self._kwargs)
File "/home/robert/one-click-installers-oobabooga-linux/text-generation-webui/modules/callbacks.py", line 64, in gentask
ret = self.mfunc(callback=_callback, **self.kwargs)
File "/home/robert/one-click-installers-oobabooga-linux/text-generation-webui/modules/text_generation.py", line 196, in generate_with_callback
shared.model.generate(**kwargs)
File "/home/robert/one-click-installers-oobabooga-linux/installer_files/env/lib/python3.10/site-packages/torch/autograd/grad_mode.py", line 27, in decorate_context
return func(*args, **kwargs)
File "/home/robert/one-click-installers-oobabooga-linux/installer_files/env/lib/python3.10/site-packages/transformers/generation/utils.py", line 1452, in generate
return self.sample(
File "/home/robert/one-click-installers-oobabooga-linux/installer_files/env/lib/python3.10/site-packages/transformers/generation/utils.py", line 2468, in sample
outputs = self(
File "/home/robert/one-click-installers-oobabooga-linux/installer_files/env/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "/home/robert/one-click-installers-oobabooga-linux/installer_files/env/lib/python3.10/site-packages/accelerate/hooks.py", line 165, in new_forward
output = old_forward(*args, **kwargs)
File "/home/robert/one-click-installers-oobabooga-linux/installer_files/env/lib/python3.10/site-packages/transformers/models/gptj/modeling_gptj.py", line 838, in forward
transformer_outputs = self.transformer(
File "/home/robert/one-click-installers-oobabooga-linux/installer_files/env/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "/home/robert/one-click-installers-oobabooga-linux/installer_files/env/lib/python3.10/site-packages/transformers/models/gptj/modeling_gptj.py", line 671, in forward
outputs = block(
File "/home/robert/one-click-installers-oobabooga-linux/installer_files/env/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "/home/robert/one-click-installers-oobabooga-linux/installer_files/env/lib/python3.10/site-packages/accelerate/hooks.py", line 165, in new_forward
output = old_forward(*args, **kwargs)
File "/home/robert/one-click-installers-oobabooga-linux/installer_files/env/lib/python3.10/site-packages/transformers/models/gptj/modeling_gptj.py", line 301, in forward
attn_outputs = self.attn(
File "/home/robert/one-click-installers-oobabooga-linux/installer_files/env/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "/home/robert/one-click-installers-oobabooga-linux/installer_files/env/lib/python3.10/site-packages/accelerate/hooks.py", line 165, in new_forward
output = old_forward(*args, **kwargs)
File "/home/robert/one-click-installers-oobabooga-linux/installer_files/env/lib/python3.10/site-packages/transformers/models/gptj/modeling_gptj.py", line 202, in forward
query = self.q_proj(hidden_states)
File "/home/robert/one-click-installers-oobabooga-linux/installer_files/env/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "/home/robert/one-click-installers-oobabooga-linux/installer_files/env/lib/python3.10/site-packages/accelerate/hooks.py", line 165, in new_forward
output = old_forward(*args, **kwargs)
File "/home/robert/one-click-installers-oobabooga-linux/installer_files/env/lib/python3.10/site-packages/torch/nn/modules/linear.py", line 114, in forward
return F.linear(input, self.weight, self.bias)
RuntimeError: CUDA error: CUBLAS_STATUS_NOT_INITIALIZED when calling cublasCreate(handle)
Fixed this by reducing the VRAM with the --gpu-memory flag by one gigabyte.
It is now possible to set fractional --gpu-memory values too like --gpu-memory 3400MiB.
None of the suggestions are working for me, I still get the same error as OP.
Same here. Using LLaMA-7B

and whenever I try to generate anything:
the entire GPU crashes and I get this error:
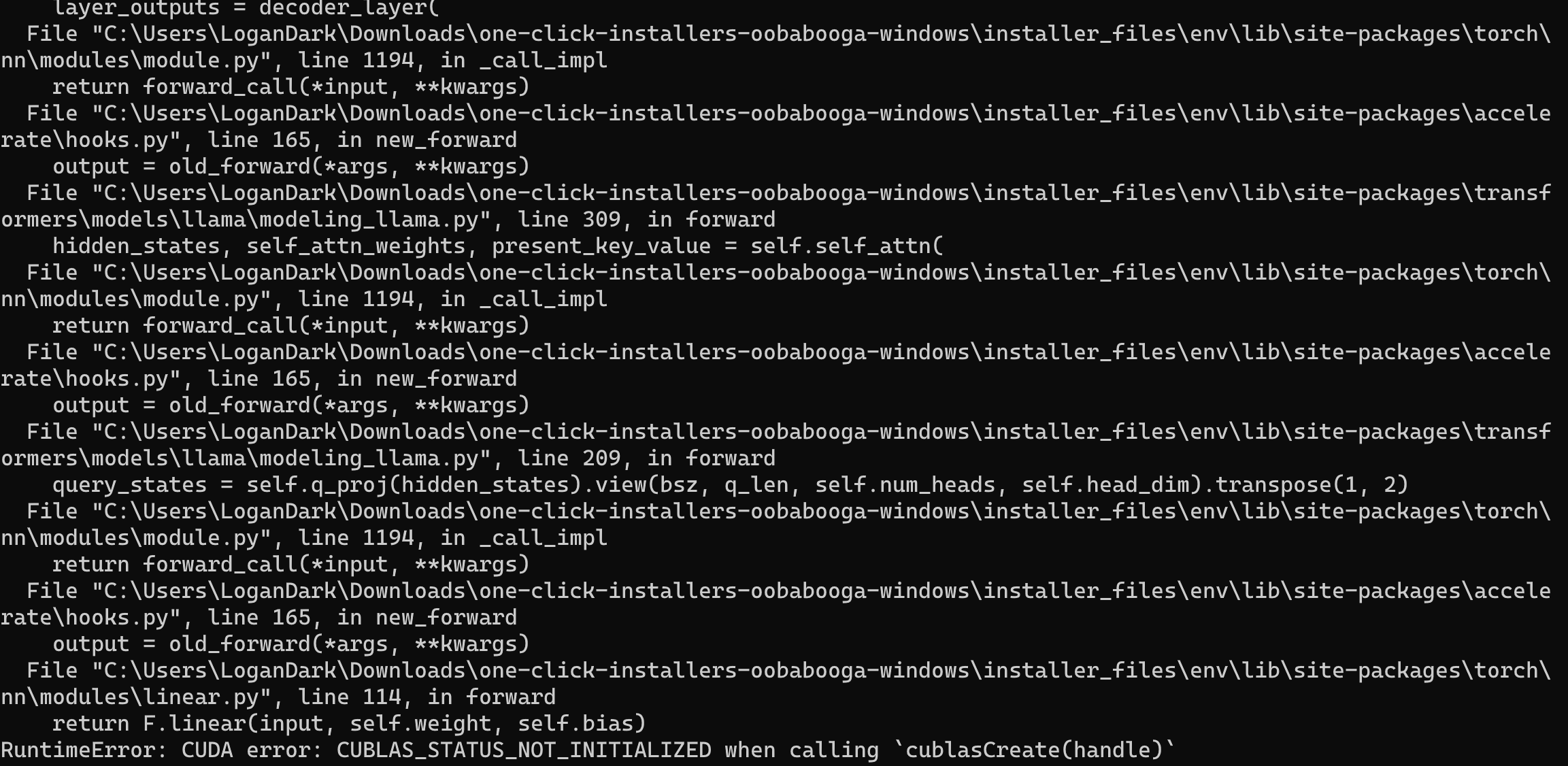
I have --gpu-memory set to 8 with 12GB of VRAM
I had reinstalled new version and now its wont start at all
Starting the web UI...
Warning: --cai-chat is deprecated. Use --chat instead.
Traceback (most recent call last):
File "C:\Distr\oobabooga-windows\text-generation-webui\server.py", line 18, in
Try replacing your install.bat with the updated one and re-running it https://github.com/oobabooga/one-click-installers/
After the update I get
CUDA SETUP: Required library version not found: libsbitsandbytes_cpu.so. Maybe you need to compile it from source?
CUDA SETUP: Defaulting to libbitsandbytes_cpu.so...
argument of type 'WindowsPath' is not iterable
CUDA SETUP: Required library version not found: libsbitsandbytes_cpu.so. Maybe you need to compile it from source?
CUDA SETUP: Defaulting to libbitsandbytes_cpu.so...
argument of type 'WindowsPath' is not iterable
C:\Users\user\Downloads\one-click-installers-oobabooga-windows\installer_files\env\lib\site-packages\bitsandbytes\cextension.py:31: UserWarning: The installed version of bitsandbytes was compiled without GPU support. 8-bit optimizers and GPU quantization are unavailable.
warn("The installed version of bitsandbytes was compiled without GPU support. "
and
Warning: torch.cuda.is_available() returned False.
This means that no GPU has been detected.
Falling back to CPU mode.
Try replacing your install.bat with the updated one and re-running it https://github.com/oobabooga/one-click-installers/
for now its new problem) I have conda installed And nothing was changed from my side
but now i Cant runt install

I have the same error (the 1st one) CUBLAS_STATUS_NOT_INITIALIZED when trying to launch a LLama Model.
@ALL I was having this error when launching multiple instances of LLM on GPU. If running textgen alone, I'm fine
Does the project require a certain version of NVIDIA CUDA? I'm running 12.1. I'm getting the error trying a few 13B models, but not TheBloke_vicuna-7B-1.1-GPTQ-4bit-128g
edit: Solved by just not using other similar looking models on huggingface. Using OpenAssistant/oasst-sft-4-pythia-12b-epoch-3.5 with some of the options to reduce and control amount of VRAM used works for me.
This issue has been closed due to inactivity for 6 weeks. If you believe it is still relevant, please leave a comment below. You can tag a developer in your comment.
Fixed this by reducing the VRAM with the
--gpu-memoryflag by one gigabyte.
@RazeLighter777 ,
I'm currently having this same issue and came across this thread while searching for a solution. Exactly how did you reduce the memory with --gpu_memory command? Thanks.