text-generation-webui
 text-generation-webui copied to clipboard
text-generation-webui copied to clipboard
Repeated replies in chat mode with flexgen
I've successfully loaded opt-30b-iml-max via python server.py --model opt-iml-max-30b --flexgen --compress-weight --cai-chat --percent 100 0 100 0 100 0 on a 4090.
Unfortunately, the bot appears to be repeating the same greeting message after I'm 6 messages in.
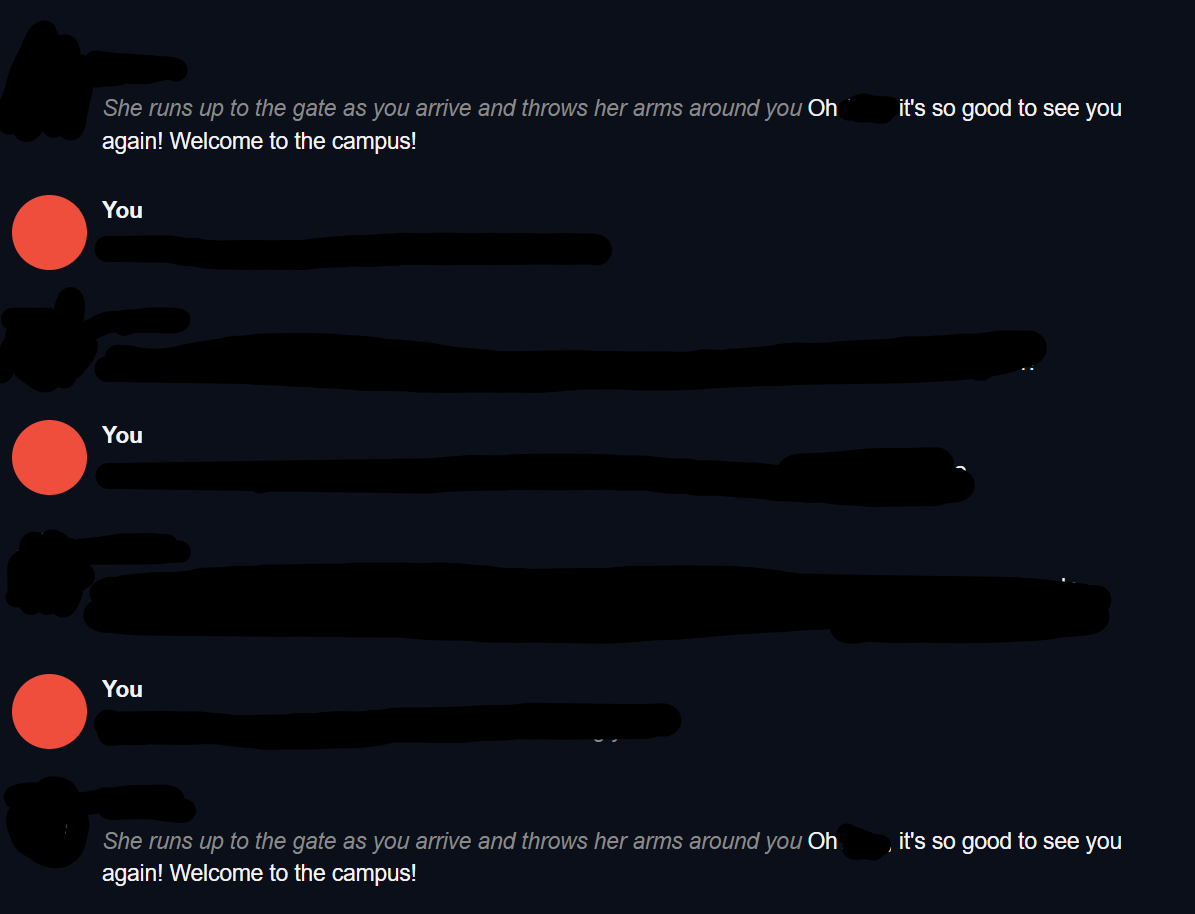
Also, trying to switch bots when this happens gives me a seemingly infinite loading time.
No errors appear on the console.
What could be causing this? Happens with multiple bots.
Is there any reason you used opt-30b-iml-max instead of opt-30b ? I see you get nice speed compared to me (I get 0.09it/s on a 4090...), but I confirm I get a continuation on my current story, no repetition, although the speed is too atrocious for me to test much. I'll try opt-30b-iml-max and tell you if I get the same speed as you.
Oh, my speed problem is related to the no-stream config. I'm not sure I see a huge difference between these 2 models, but my already created conversation seems to continue fine.
I'm just testing behaviors with different models. Honestly, for the 2 messages it managed to answer, it wasn't bad at all. 0.09 there must be something wrong. I'll also test opt-30b soon hopefully I'll get similar speeds to what I have.
Yeah I referenced the problem here : https://github.com/oobabooga/text-generation-webui/issues/105
This looks like a silent CUDA out of memory error. I will make some experiments with 30b models later and will report my findings.
@MetaIX I just got the same message thing, I raised the only parameter I could (temperature) and regenerated the text, and it gave me another one.
@Ph0rk0z it is true that the token limit is being generated 100% of the time in flexgen mode. This is really annoying. I seem to be using the stop parameter exactly as in the official FlexGen chatbot example, but it doesn't do anything.
I think that this fixes the issue of FlexGen not stopping the generation at a new line character
https://github.com/oobabooga/text-generation-webui/commit/6e843a11d64ec0898a1cb6f2cc9a81619038db81
This issue has been closed due to inactivity for 30 days. If you believe it is still relevant, please leave a comment below.
Cargué con éxito opt-30b-iml-max a través de python server.py --model opt-iml-max-30b --flexgen --compress-weight --cai-chat --percent 100 0 100 0 100 0 en un 4090.
Desafortunadamente, el bot parece estar repitiendo el mismo mensaje de saludo después de 6 mensajes.
Además, tratar de cambiar de bots cuando esto sucede me da un tiempo de carga aparentemente infinito.
No aparecen errores en la consola.
¿Qué podría estar causando esto? Ocurre con múltiples bots.
Abierto