tensorflow-onnx
 tensorflow-onnx copied to clipboard
tensorflow-onnx copied to clipboard
TF Conv2D Grouped Unsupported ops: Counter({'PartitionedCall': 1})
Describe the bug
Error when a model SavedModel in TF 2.10.0/2.11.0 that contain a TF Conv2D grouped is converted in ONNX with the API tf2onnx.convert.from_keras()
01-05-2023_15:50:43][WARNING][load.py:load()::177] No training configuration found in save file, so the model was *not* compiled. Compile it manually.
[01-05-2023_15:50:43][INFO][custom_load.py:load_saved_model()::50] Load the model SaveModel (.pb, variable, assets)
[01-05-2023_15:50:43][INFO][tf_to_onnx.py:convert_savemodel_to_onnx()::75] Convert SavemMdel to ONNX
[01-05-2023_15:50:43][INFO][tfonnx.py:process_tf_graph()::437] Using tensorflow=2.11.0, onnx=1.13.0, tf2onnx=1.13.0/2c1db5
[01-05-2023_15:50:43][INFO][tfonnx.py:process_tf_graph()::439] Using opset <onnx, 17>
[01-05-2023_15:50:43][INFO][tf_utils.py:compute_const_folding_using_tf()::281] Computed 0 values for constant folding
[01-05-2023_15:50:43][INFO][tf_utils.py:compute_const_folding_using_tf()::281] Computed 0 values for constant folding
[01-05-2023_15:50:43][ERROR][tfonnx.py:tensorflow_onnx_mapping()::263] Tensorflow op [dummymodel/dummymodel/conv_1/PartitionedCall: PartitionedCall] is not supported
[01-05-2023_15:50:43][ERROR][tfonnx.py:process_parsed_graph()::625] Unsupported ops: Counter({'PartitionedCall': 1})
[01-05-2023_15:50:43][INFO][__init__.py:optimize_graph()::48] Optimizing ONNX model
[01-05-2023_15:50:43][INFO][__init__.py:optimize_graph()::83] After optimization: Cast -3 (3->0), Const -16 (31->15), Identity -2 (2->0), Reshape -3 (3->0), Transpose -21 (25->4)
[01-05-2023_15:50:43][INFO][tf_to_onnx.py:main()::119] Conversion ONNX succeeded in /tmp/dummymodel/model/inference/dummymodel.onnx
Traceback (most recent call last):
File "tf_to_onnx.py", line 136, in <module>
main(sys.argv[1:])
File "tf_to_onnx.py", line 122, in main
onnx.checker.check_model(model)
File "/usr/local/lib/python3.8/dist-packages/onnx/checker.py", line 119, in check_model
C.check_model(protobuf_string, full_check)
onnx.onnx_cpp2py_export.checker.ValidationError: No Op registered for PartitionedCall with domain_version of 17
==> Context: Bad node spec for node. Name: dummymodel/dummymodel/conv_1/PartitionedCall OpType: PartitionedCall
System information
- OS Platform and Distribution : Ubuntu 20.04
- TensorFlow Version: 2.10.1/2.11.0
- Python version: 3.8
- ONNX version : 1.13.0
- ONNXRuntime version : 1.11.0
- ONNX OPSET: 15/16/17
To Reproduce The dummy model to reproduce the error, the error appears when "conv1" groups!=1:
import tensorflow as tf
def dummymodel(input_shape, num_classes:int, depth_multiplier:int=1, is_dropout:float=0.0):
input_tensor = tf.keras.layers.Input(shape=input_shape, name="input")
input_shape = input_tensor.get_shape().as_list()[1:3]
x = tf.keras.layers.SeparableConv2D(
filters=16,
depth_multiplier=depth_multiplier,
kernel_size=3,
strides=2,
name="convSep1",
)(input_tensor)
x = tf.keras.layers.BatchNormalization(name="batch1")(x)
x_add_1 = tf.keras.layers.Activation("relu", name="relu1")(x)
x = tf.keras.layers.DepthwiseConv2D(
kernel_size=3,
strides=(3, 3),
depth_multiplier=depth_multiplier,
name="convDepth1",
)(x_add_1)
x = tf.keras.layers.AveragePooling2D(pool_size=(2, 2), name="avgPooling")(x)
x_concat_1 = tf.keras.layers.UpSampling2D(size=(2, 2), interpolation="nearest", name="output")(x)
x_concat_2 = tf.keras.layers.Conv2D(
filters=16,
kernel_size=(3, 3),
strides=3,
data_format=None,
groups=4,
activation=None,
use_bias=True,
name="conv_1",
)(x_add_1)
x = tf.keras.layers.Concatenate(axis=-1, name="concat")([x_concat_1, x_concat_2])
x = tf.keras.layers.Lambda(
lambda img: tf.image.resize(
images=img, size=(input_shape[0], input_shape[1]), method="bilinear"
),
name="resizeBilinear",
)(x)
x_add_2 = tf.keras.layers.SeparableConv2D(
filters=16,
depth_multiplier=depth_multiplier,
kernel_size=3,
strides=2,
name="convSep2",
)(x)
x = tf.keras.layers.Add(name="add")([x_add_1, x_add_2])
if is_dropout:
x = tf.keras.layers.Dropout(rate=0.2, name="dropout")(x)
x = tf.keras.layers.Conv2D(filters=num_classes, kernel_size=3, strides=2, name="conv2")(x)
output = tf.keras.layers.UpSampling2D(size=(4, 4), interpolation="bilinear", name="output_")(x)
return tf.keras.Model(
inputs=input_tensor, outputs={"output_": output}, name="dummymodel"
)
if __name__ == "__main__":
import os
model = dummymodel(
input_shape=(1024, 1024, 3),
num_classes=3,
depth_multiplier=1,
is_dropout=0.0,
)
model.summary(line_length=250)
tf.keras.models.save_model(
model, os.path.join("/tmp", "dummymodel"), include_optimizer=False
)
The conversion script :
import onnx
import tensorflow as tf
import tf2onnx
if __name__ == "__main__":
savedmodel_path="/tmp/dummymodel/"
onnx_saved_path = "/tmp/dummymodel.onnx"
model = tf.keras.models.load_model(savedmodel_path, compile=False)
shape = model.input.get_shape()
input_image = tf.keras.layers.Input(shape=(shape[1], shape[2], shape[3]), name="input_")
spec = (tf.TensorSpec(shape, tf.float32, name="input_"),)
print("Convert")
_, _ = tf2onnx.convert.from_keras(
model,
input_signature=spec,
opset=17,
output_path=onnx_saved_path,
)
print("Check")
model = onnx.load(onnx_saved_path)
onnx.checker.check_model(model)
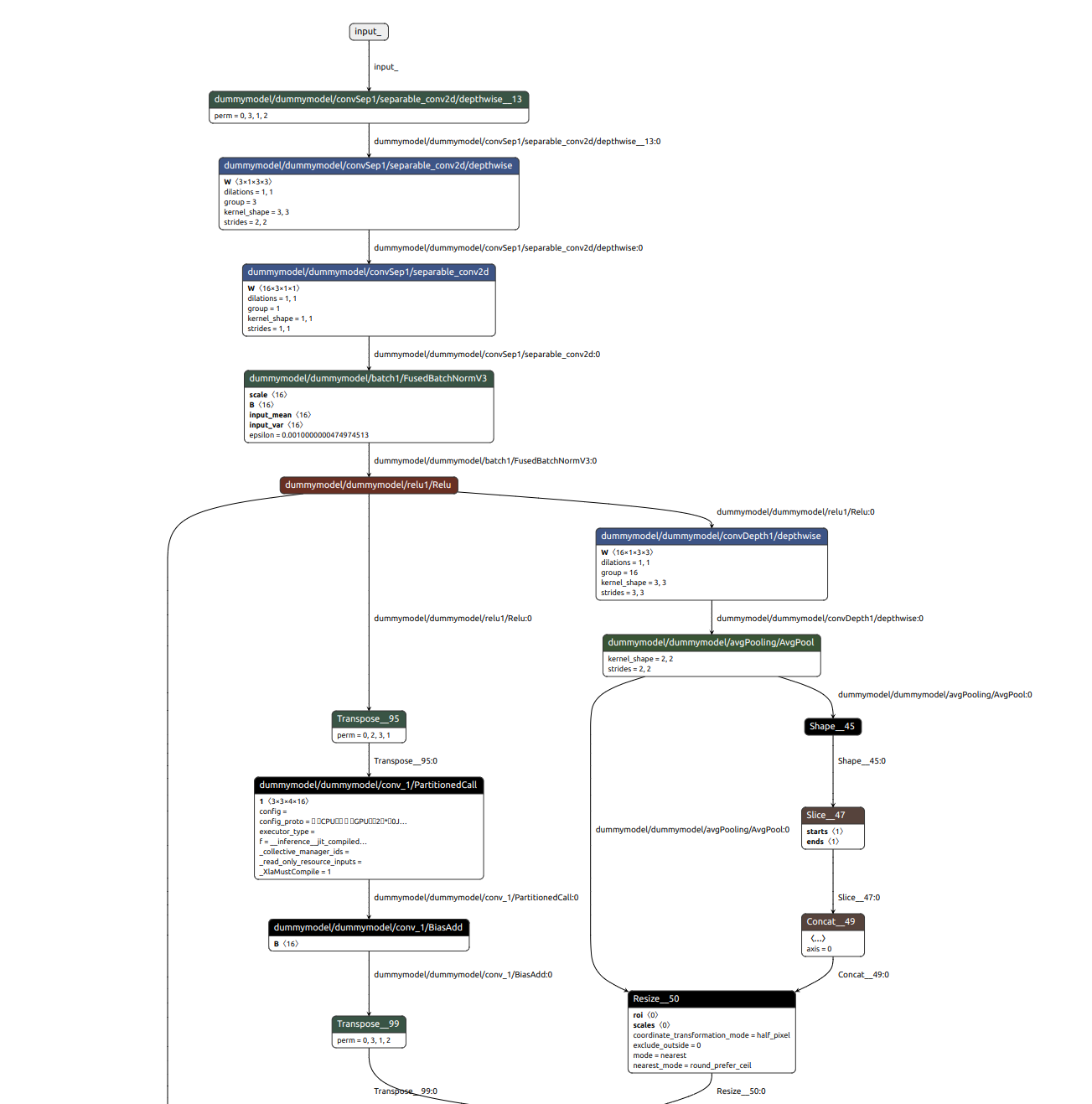
Screenshot
Issue for the conversion of the layer dummymodel/dummymodel/conv_1/PartitionedCall which is the Conv2d grouped
The problem is that grouped convolutions are not fully supported on the CPU and keras wraps them with @tf.function(jit_compile=True), see base_conv.py#L272-L290. I use the following workaround for SegFormer:
for block in segformer.segformer.encoder.block:
for layer in block:
# monkey patch depthwise convolution `_jit_compiled_convolution_op`
# to support onnx conversion.
layer.mlp.depthwise_convolution.depthwise_convolution._jit_compiled_convolution_op = (
layer.mlp.depthwise_convolution.depthwise_convolution.convolution_op
)
I think this can be generalize in tf2onnx to support any model, cause we just need to skip the _jit_compiled_convolution_op block.