Why get_num_cores() in aarch64 only return 1?
hi sir,
I'm trying to using my own thread_pool to replace the omp_thread_pool.
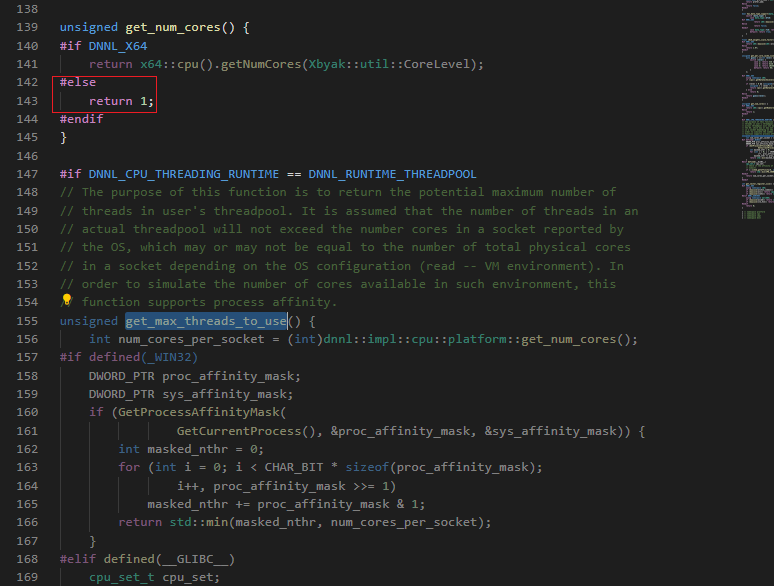
During debug, I find that get_max_threads_to_use() in oneDNN-2.2\src\cpu\platform.cpp always return 1 in aarch64.
Is that any problem if I change the return value of get_num_cores()?
Why did you set it to 1 in the case of aarch64?
Hi @ZJUFangzh, that's a very good question!
I would say that the primary reason is that Aarch64 maintainers committed to support OMP runtime only. It means that any other runtime, threadpool included, is not validated at best level.
This fact aside, I guess, it could be smoothly supported if there's something like this:
// src/cpu/platform.cpp:148
#elif DNNL_AARCH64
return aarch64::cpu().getNumCores();
The problem is there's no such support in aarch64_xbyak yet (at least I struggled to find any) and it doesn't inspect cpuid for available number of cores. If your needs are limited to a specific OS, I may recommend to implement a custom num_cores_count() function that would provide a number of cores on the system.
It may make sense to try with this fixup here (we plan to promote it any way soon):
return tp ? std::max(1, tp->get_num_threads()) : def_max_threads;
This would mean that all primitives you create would assume there's only a single thread (if you keep existing identification of number of threads as one) on a system at creation time but at runtime you may pass as many as you think it's reasonable. This may lead to issues, but I don't know if this would be a case for Aarch64 implementations you are using. So I would go with this simple solution first. If it's not working, then implement a function to identify threads which would utilize the knowledge of your threadpool.
The only thing you may keep in mind is that ACL-based implementations may struggle if your threadpool implementation would be barrier-less since TBB threading causes issues leading to crashes in certain functionality. I don't know if this is the case for jit implementations.
Meanwhile, @kawakami-k, could you, please, guide, if you have getNumCores support for Aarch64 (which I could miss) or have any plans to add one as for x64? If it's not there, it seems that it might be helpful to support threadpool interface. Mention @nSircombe and @diaena JFYI. Thanks.
Hi @ZJUFangzh I can cover what happens for the Compute Library kernels.
Note: for more information on how Compute Library is integrated into oneDNN see this RFC: https://github.com/oneapi-src/oneDNN/pull/795/files#diff-c03394b05656627a041b9bb8ef2e6cd10952058216bb9f0f96bfdf53a5a95b86 and subsequent PR: https://github.com/oneapi-src/oneDNN/pull/820. You’ll find a string of them after that, usually with “cpu:aarch64" in the name. There are also some notes in the docs: https://oneapi-src.github.io/oneDNN/dev_guide_build.html#gcc-with-arm-compute-library-acl-on-aarch64-host and https://oneapi-src.github.io/oneDNN/dev_guide_build_options.html#).
We are currently setting the number of cores used for Compute Library primitives based on dnnl_get_max_threads() (https://github.com/oneapi-src/oneDNN/blob/26a7c19e15dee8988cd35bd3c5db52c37aa9bd3c/src/cpu/aarch64/acl_utils.cpp#L108).
As @dzarukin mentioned, there’s currently no support for TBB or THREADPOOL, we assume oneDNN is built with the OMP runtime. In this case dnnl_get_max_threads() just returns OMP_NUM_THREADS.
I’m sure @kawakami-k will be able to cover thread management in the xbyak_aarch64 based primitives, although I believe this also assumes an OMP runtime (I may be wrong).
Could I ask what target you’re building for @ZJUFangzh? The Xbyak_aarch64 primitives are vector length specific and largely target HW with support for SVE512, i.e. the A64FX. The Compute Library primitives are vector length agnostic, and will support any SVE vector length, as well as NEON, of course.
Hope that helps.
Thanks you very much.
I do not know much about aarch64_xbyak .But It seems work with this code return tp ? std::max(1, tp->get_num_threads()) : def_max_threads; @dzarukin
In our usage scenario, we make different primitives to be run concurrently if they have no executive relationship, in order to get a better performance of the whole network. we use onednn's api to implement some of our kernels such as matmul、conv2d which used omp_thread_pool default, and some kernels we implement by ourselves which use our thread_pool base on std. So, it confused us for a long time that we can't mix the omp_thread_pool and std_thread_pool togather. Furthermore, it seems the thread num will increase when we concurrently run many onednn kernels, because of the omp_thread_pool, maybe like this one
That's the reason why we trying to change the thread_pool in onednn. By reading code, I found that it will raise fault if threadpool_utils::activate_threadpool(tp) called twice at the same time. But it seems noting error when I passing my thread_pool ptr to dnnl_threadpool_interop_sgemm or cpu_stream_t as the same time, they may be called concurrently in runtime. Did I understand the logic of code wrong?
The second problem is, when we run Resnet on AARCH64, the memory continues to grow, and when I set OMP_NUM_THREAD=1, the memory remains stable. It seems that the omp_thread affects the memory.Therefore, we want to use our own thread_pool to see if there will be memory growth in this way.
Thanks for your reply. @nSircombe @dzarukin
Hi @ZJUFangzh,
The second problem is, when we run Resnet on AARCH64, the memory continues to grow, and when I set OMP_NUM_THREAD=1, the memory remains stable.
...that's interesting. Would you be able to provide details of how you're building oneDNN, and steps to reproduce the memory issue you've seen with ResNet50.
Sorry for inconvenience. I'll check the issue at this week end. If you can provide additional information, as nSircombe points out, could you please give me.
Sorry for inconvenience. I'll check the issue at this week end. If you can provide additional information, as nSircombe points out, could you please give me.
Well, we make some simple examples to reproduce our problems, we test on OneDNN2.2
Problem 1
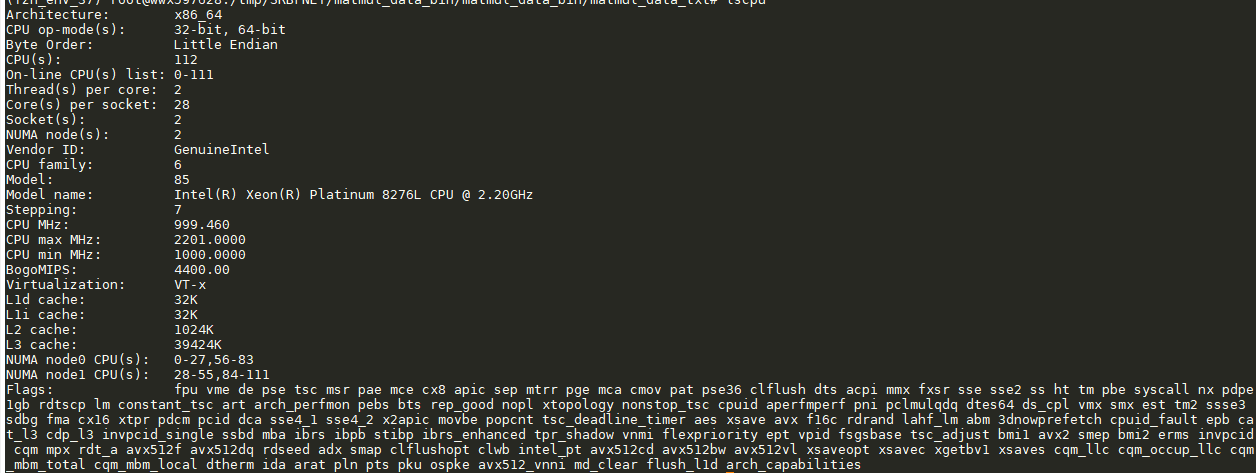
For problem1, when we use dnnl_segmm to compute something in x86_64,it seems like the input data will have much effect of the performance. We will upload the code and test data below. When we run the funtion test_slow(), it may get the result
step: 1
run time first: 2.80881 ms, second: 43.7171 ms
step: 2
run time first: 2.79498 ms, second: 43.6878 ms
step: 3
run time first: 2.78401 ms, second: 43.7009 ms
step: 4
run time first: 2.77305 ms, second: 43.725 ms
step: 5
run time first: 2.774 ms, second: 43.6969 ms
step: 6
run time first: 2.76303 ms, second: 43.679 ms
The performences are quiet different, which is 20x times, but the shape of input data are same.(for single thread)
the platform of our machine is:
Problem 2
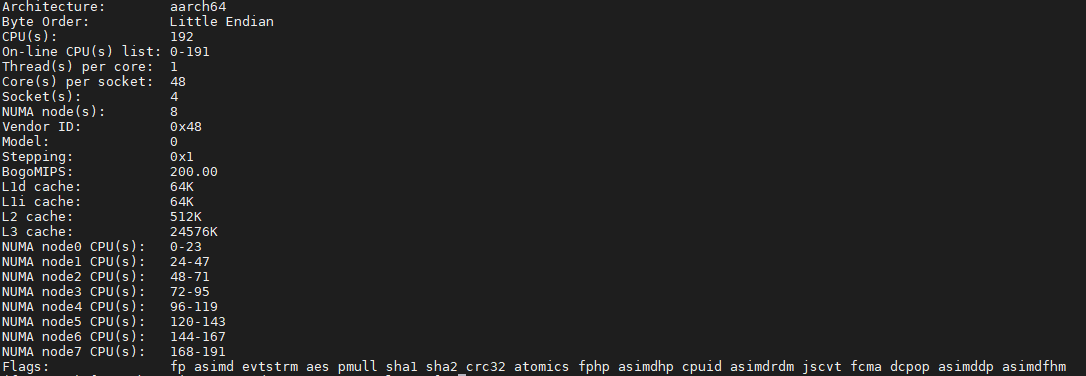
For the problem2, When we run the funtion test_memory(), under the aarch64 environment and without set OMP_NUM_THREADS, the memory will continue to grow,but the same condition does not be a problem on x86, or export OMP_NUM_THREADS=1 on aarch64, the memory can also remain stable.
Here, I'm just using the simple mamtmul case, but when we run the neural network, we found that there are other operators that had the same situation, such as conv2D ans it's backward.
I switched to the THREADPOOL, and it seems to solve the memory problem on aarch64. So I wonder if the omp thread caused the memory growth.
it may get the result, the RES is growing quickly:
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
51028 root 20 0 96.2g 13792 4924 R 237.0 0.0 0:11.56 test_bk
51028 root 20 0 96.2g 29600 4924 R 215.1 0.0 0:38.50 test_bk
51028 root 20 0 96.2g 31764 4924 R 216.3 0.0 0:51.78 test_bk
51028 root 20 0 96.2g 40616 4924 R 215.7 0.0 1:11.57 test_bk
51028 root 20 0 96.2g 50668 4924 R 216.0 0.0 1:31.42 test_bk
51028 root 20 0 96.2g 59444 4924 R 217.0 0.0 1:51.35 test_bk
the platform of our machine is:
Thank you very much! @kawakami-k @dzarukin @nSircombe
Hi @ZJUFangzh, I can comment on problem 1. This is rather an effect of not quite honest comparison rather than data influence. First call would initialize and generate all the kernels and this process is time consuming. Also, each consecutive call make cache prepared for data. To check that, just use same data set in the comparison you do and, I bet, you'll see the same effect. That's why we recommend doing several cold-run loops and benchmark consequent loops only coming after those cold-run loops to have an "honest" comparison when only execution comes into play.
Data may affect performance, but I'm aware only about two cases:
- Denormal values are among the data. It takes additional cost to process denormal values on x86-64 (not sure about aarch64). That's why we usually recommend to set flush-to-zero fp mode since those values hardly affect accuracy of models.
- Most or all zeros among the data. x86-64 hardware has some advantage of processing zeros, skipping an instruction (at least FMAs), thus, improving latency overall.
Our recommendation is to avoid both cases when trying to benchmark kernels since it leads to tentative results in both cases.
As for Problem 2, I don't know if Aarch64 team is looking into it right now, but my minor suggestion would be to start with valgrind or Address clang sanitizer and make sure the problem is in oneDNN and not in other place, since leaks are harder to track than crashes and verifying the specific spot helps a lot to debug the issue. Thanks.
Denormal values are among the data. It takes additional cost to process denormal values on x86-64 (not sure about aarch64). That's why we usually recommend to set flush-to-zero fp mode since those values hardly affect accuracy of models.
@dzarukin thanks, it seems like there are actualy denormal values among the data. I set like this to solve the problem.
_MM_SET_FLUSH_ZERO_MODE(_MM_FLUSH_ZERO_ON);
_MM_SET_DENORMALS_ZERO_MODE(_MM_DENORMALS_ZERO_ON);
And for a more question, as I ask in this issue above , if I use my THREADPOOL to replace omp_thread_pool, can I concurrently execute different streams which init with the same THREADPOOL ptr? I have this question because I view the funtion that threadpool_utils::activate_threadpool(tp) may assert (!activate_threadpool). And if the streams execute concurrently, will it activate twice and assert false? I haven't verify this.
@dzarukin @nSircombe
hi sir, I'm trying to using my own thread_pool to replace the omp_thread_pool. During debug, I find that
get_max_threads_to_use()inoneDNN-2.2\src\cpu\platform.cppalways return 1 in aarch64. Is that any problem if I change the return value ofget_num_cores()? Why did you set it to 1 in the case of aarch64?
HI, @ZJUFangzh
The reason why it always returned 1 was because getNumCores() was not implemented in Xbyak_aarch64 then, and still is not. I'll add getNumCores() to Xbyak_aarch64 and fix it to get the correct number of cores from oneDNN.
Hi @ZJUFangzh,
if I use my THREADPOOL to replace omp_thread_pool, can I concurrently execute different streams which init with the same THREADPOOL ptr?
As long as you would like to run a threadpool in parallel, it should identify itself so through get_in_parallel() call when configuring threadpool. It would make each primitive to run on a single thread since oneDNN doesn't support nested parallelism. Rest should be fine. Disclaimer: we don't have tests to validate this as of now.
Thank you.
I am aware that this Issue has been assigned to me. Please give me some more time so I can add the feature.
I'm so sorry for slow response. Some experimental APIs are added to Xbyak_aarch64 to get the number of CPU cores, cache hiearchy information and cache sizes. These interfaces are as same as Xbyak for x86_64. https://github.com/oneapi-src/oneDNN/pull/1484
These information are described in the CPU's system registers. However, it's not possible to read them directly from the user application programs in AArch64 based systems. Linux provides these information in /sys/devices/system/cpu/* and the kernel APIs. However, the correct information may not always be available depending on the kernel version or CPU support status. Currently, Xbyak_aarch64 can return correct values for limited combinations of kernel verasions and CPUs.
If Xbyak_aarch64 doesn't return correct values in your systems, I would appreciate your feedback to Xbyak_aarch64.
As already discussed in this issue, the number of cores can be obtained using OpenMP functions or by using ACL functions. For now, I recommend using them.
Thank you for the discussion!