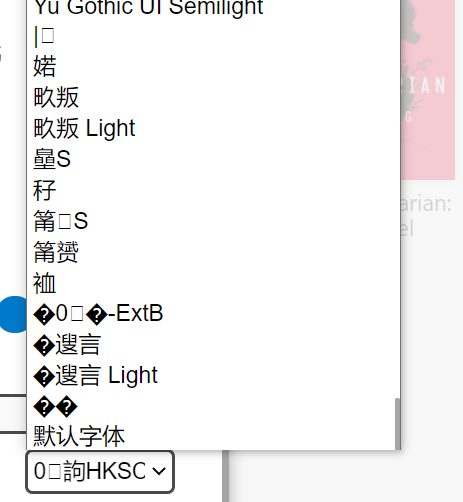
中文乱码
当前版本:1.2.11 当前系统:win10 当前nodejs:12.13.0
#13 中提到的强制使用utf8代码页chcp 65001并不是一个万能的解决方案。在我的电脑中这并不能按照预期工作,还是有乱码:
215: ""Yu Gothic UI Semilight""
216: ""Yu Gothic UI""
217: ""Yu Gothic""
218: "ܛ�����w"
219: ""ܛ�����w Light""
220: "���ź�"
221: ""���ź� Light""
222: "�¼����w-ExtB"
223: "��Բ"
224: "���IJ���"
225: "���ķ���"
在其他项目中也有类似的情况,例如wmic,但都不清楚问题的原因是什么,这里提到的可能是由于控制台使用的是矢量字体的原因,我尝试过切换字体,但一样不能工作。(也许是因为vs code的原因?因为就算我切换字体vs code里终端的字体也没变化)
目前我发现的一个较为可行的解决方案是使用iconv-lite进行编码转换:
const iconv = require("iconv-lite");
exec(cmd, { maxBuffer: 1024 * 1024 * 10, encoding: "binary" }, (err, stdout, stderr) => {
let t = iconv.decode(Buffer.from(stdout, "binary"), "utf8");
// if not include ‘�’
if (!t.includes("\uFFFD")) stdout = t;
else stdout = iconv.decode(Buffer.from(stdout, "binary"), "cp936");
if (err) return reject(err);
resolve(parse(stdout));
});
只判断�是因为Buffer会将无法解析为utf8的字符变成�,参考。
由此得出一个通用的解决方案是通过使用chcp来获取当前活动页码,使用binary方式读取结果,最后使用iconv根据活动页码转换编码。
此外,通过vbs获取字体信息时,也存在乱码现象。但在处理返回结果的时候,把objFont.Name的结果给过滤掉了:
// libs/win32/getByVBS.js : line 21
a = a.map(i => {
i = i
.split('\t')[0]
.split(path.sep)
i = i[i.length - 1]
getByVBS.js这里后续的处理中处理的都是字体路径而非字体名,不知是否符合作者你的预期。
Ps. 通过powershell获取的结果中有空字符串,希望过滤一下。
我在我这边的虚拟机 win10 下没有重现这个问题,中文字体会显示为英文名字,所以暂时没有处理。 @troyeguo 如果你遇到问题,麻烦把有问题的字体名说一下,我安装测试下。
我的电脑上一切正常,中文字体名可以正常显示,但这个issue里有人反馈了乱码问题,这会不会是powershell 版本的问题,https://github.com/troyeguo/koodo-reader/issues/160
按 @qinshou2017 的方案改进了 Windows 下的处理,不过因为我这边一直没有重现问题,所以也不确定那个乱码问题是否解决了。 @troyeguo 你可以试试 v1.3.0 。