SDDP.jl
 SDDP.jl copied to clipboard
SDDP.jl copied to clipboard
Stopping rules
Without an upper bound, the question of when to terminate SDDP-type algorithms is an open question in the literature. Thus, we need some heuristic for preemptively terminating the algorithm when the solution is ''good enough.'' We call these heuristics stopping rules. Choosing an appropriate stopping rule depends on the motivation for solving the multistage stochastic optimization problem. In our view, there are three possible motivations:
- to obtain the (risk-adjusted) expected cost of the policy, e.g., in order to compare the operational cost of different investment decisions;
- to obtain a policy in the primal space, e.g., a decision rule at each node for when to release water through a hydro-electric turbine; and
- to obtain a policy in the dual space, e.g., marginal water values in the hydro-thermal scheduling problem.
Currently, there are two main stopping rules in the literature:
- the statistical stopping rule: perform a Monte Carlo simulation and stop when the lower bound is within the confidence interval for the mean of the simulated objectives
- the bound stalling stopping rule: stop once the lower bound fails to improve by more than some epsilon for more than N iterations.
Both of these stopping rules target the first use case. (Although the statistical stopping rule implicitly targets the 2nd and 3rd motivations though the simulation.)
I propose a different stopping rule based on the "stability" of the primal (or dual) policy.
To test for convergence, periodically perform a Monte Carlo simulation of the policy. Then, for select primal or dual variables of interest, compute at each stage some quantiles (e.g. the 10, 25, 50, 75, and 90'th) of the distribution of the value of those variables.
Then, using some appropriate norm, compare those quantiles to the values calculated at the previous test for convergence. Terminate once this distance stabilizes.
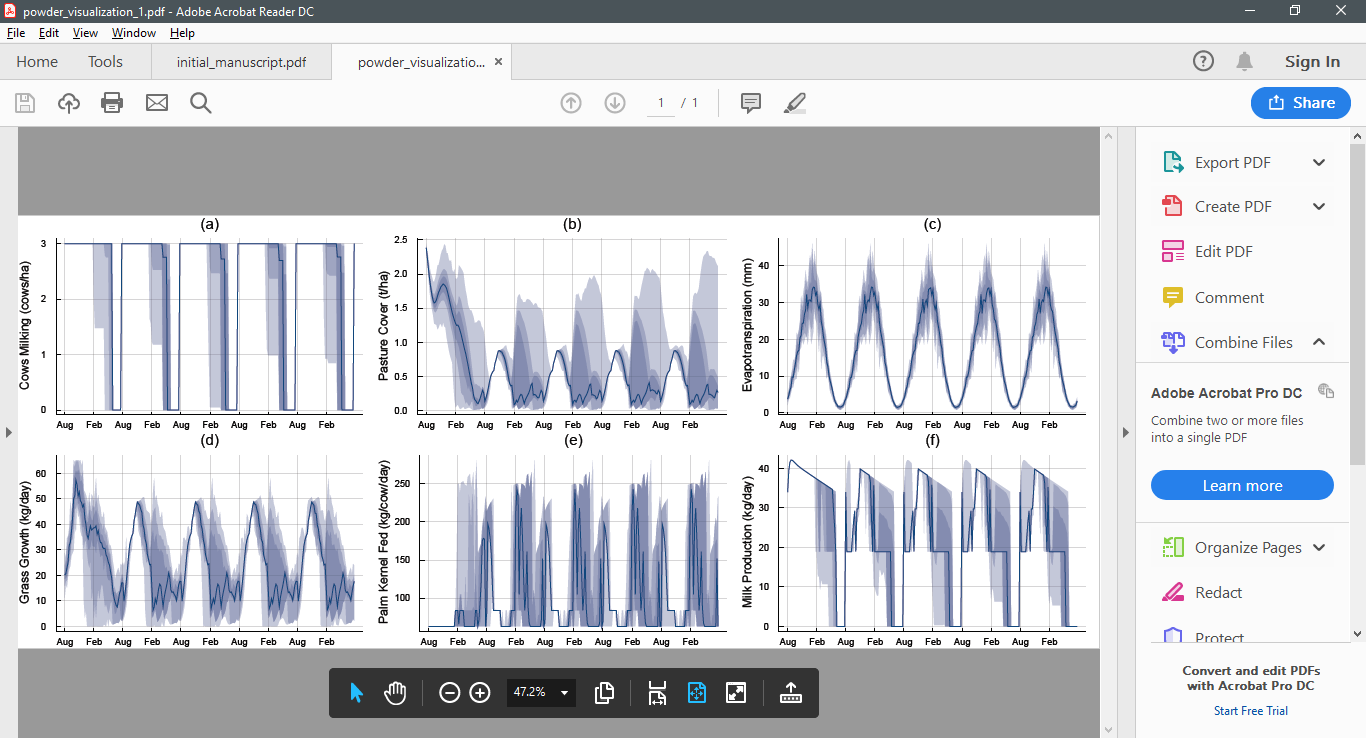
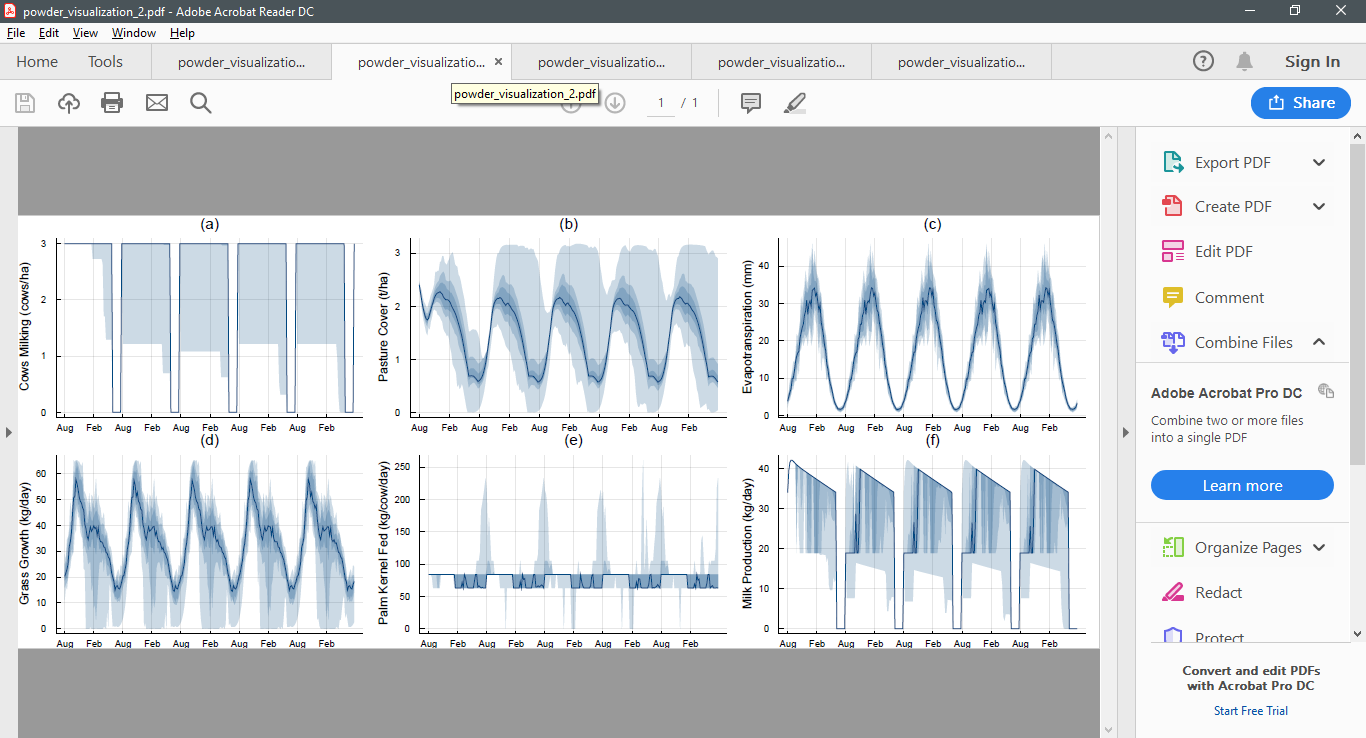
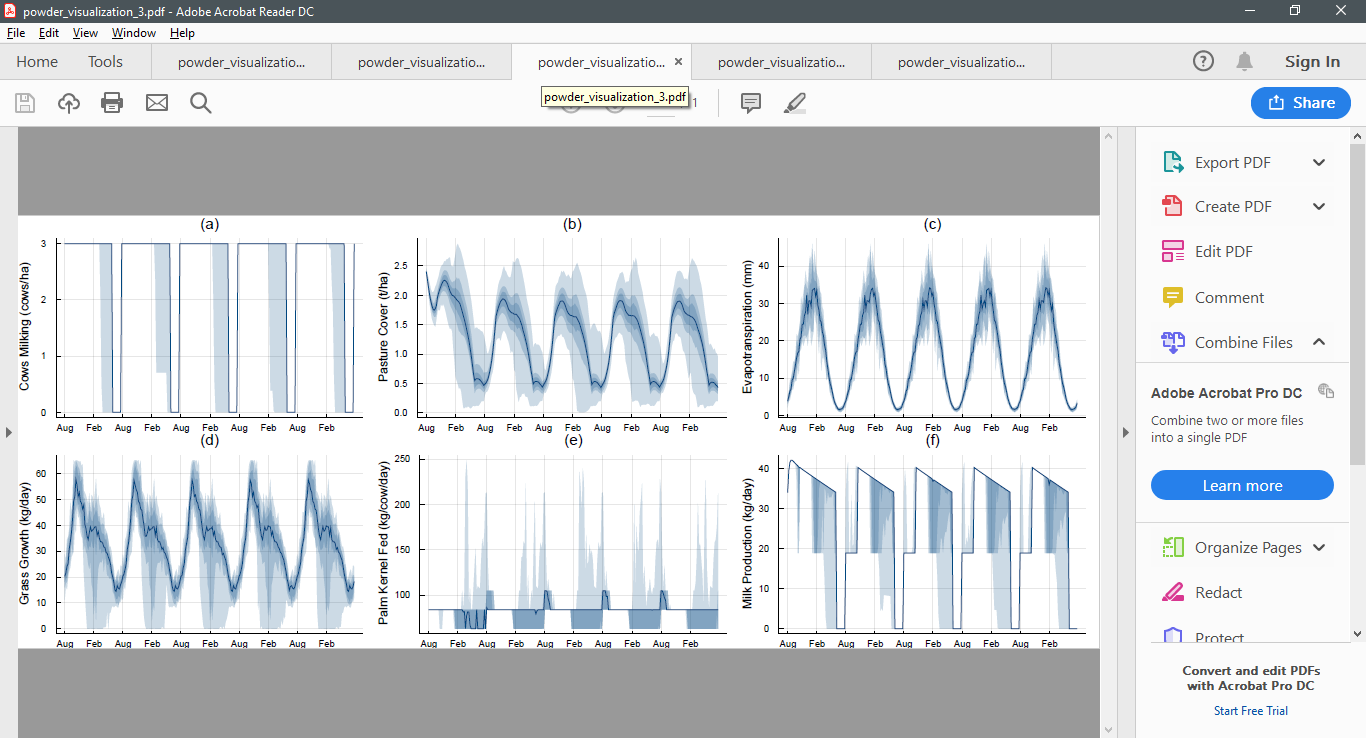
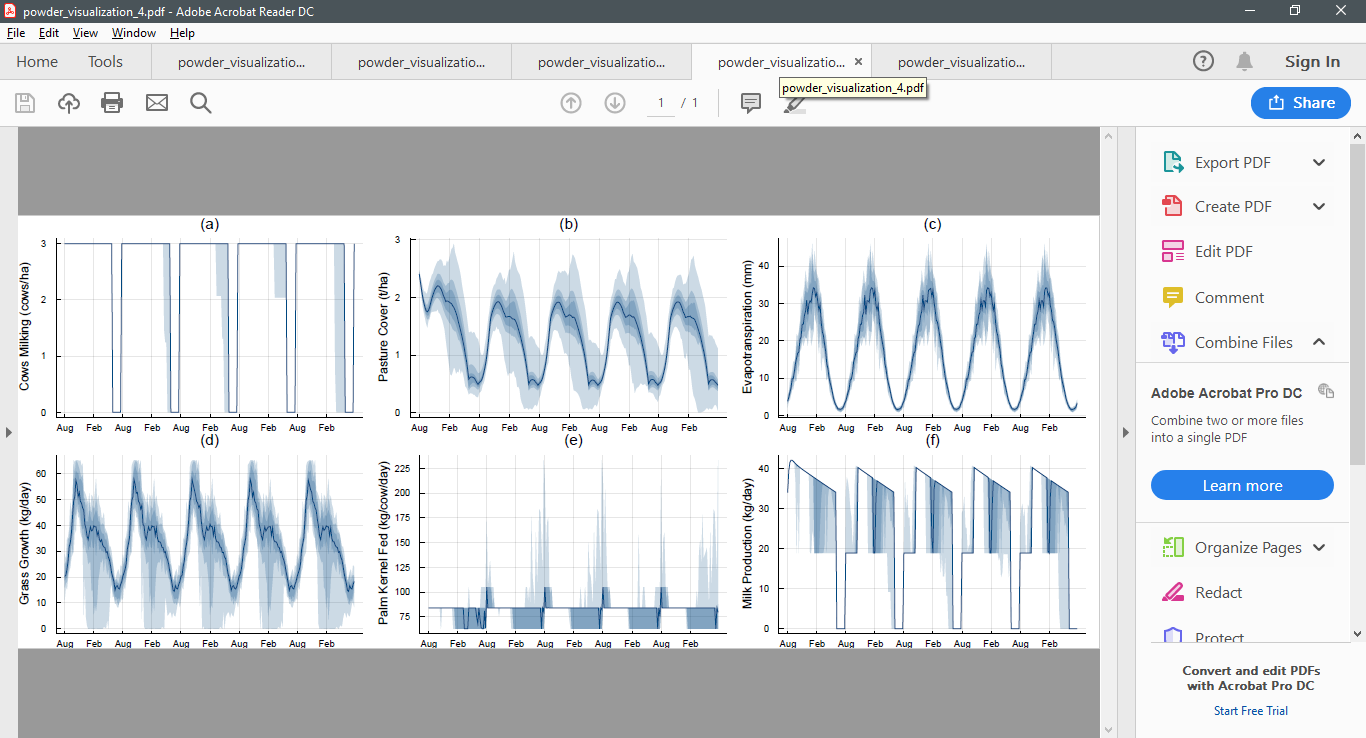
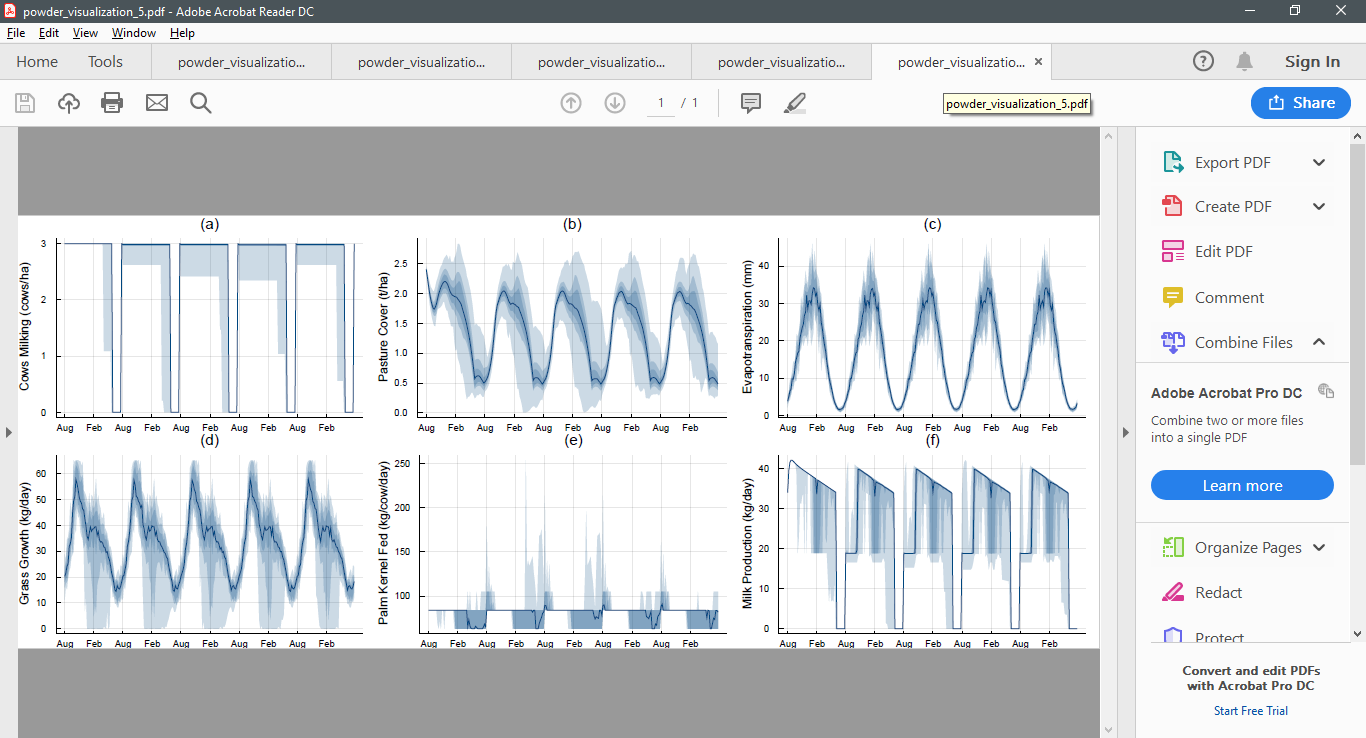
As an example, here are five simulations from the infinite horizon POWDER model conducted after 100, 200, 300, 400, and 500 iterations. Notice how the policy begins to stabilise.
After 100 iterations
After 200 iterations
After 300 iterations
After 400 iterations
After 500 iterations
Existing literature
cc @dukduque potential paper?
This has been discussed before by Alexandre Street and co:
- https://ieeexplore.ieee.org/abstract/document/9521833?casa_token=PBOAn7oG9WwAAAAA:Zv3j9omnA215zYSTux6C5jVD06eG2H3_66-R5rzFYd821X_Uz-b31vBbZqxRtjRjCvsA0La3Xw
- https://ieeexplore.ieee.org/abstract/document/7859406?casa_token=8XclggLzPKoAAAAA:Ux6Gz-Ygmq4DMxkaPppaSdpja1L1GUbuEqtZ-9H7ZHTQPT6uo6bWQXWIGlazDW8XbdymEJhsNQ
- https://ieeexplore.ieee.org/abstract/document/7862252?casa_token=RUQN9mpGEzIAAAAA:u2AeRMzB1sQEivcVoIvw3b5rWKPr4ZOYETpk5PTjasKqWoUMgOzAEvk6KjuJnladBn7N7f3s-Q



Reading the ideas in MSPPY that you mention, and since I already tweaked the Statistical stopping rule, several things come to mind:
-
The MSPPY approach of relative gap makes sense for the statistical stopping rule, i.e. dividing by the current lower (upper) bound.
-
Also, the one sided confidence interval is also relevant. With the current default value of
z_score=1.96the one sided confidence interval is 2.5% confident, one can relax that toz_score=1.64(5% confidence) since now the rule is one-sided in SDDP.jl too (#204) -
As for the stopping rule outlined above, I don't know how they compute that. They seem to perform M simulations and compare two policies. For this one has to have the older policy somewhat saved at the last convergence testing point in the algorithm, and then use it with the new simulations. It seems much more reasonable to only store the mean and std. deviation of the previous simulation step, and when testing, perform a new simulation step of M realizations with the current policy. If the confidence intervals overlap (or some similar criteria), then stop. This only requires storing only two values and not the whole policy between testing steps.
-
Thinking about this maybe a more reasonable approach would be to use Wasserstein distance (aka "earth mover" distance), which is more related to what you outlined above. Perform M simulations at evaluation point a and store the values V_1,...V_M. Then continue the algorithm and at testing point b perform another round of simulations getting V'_1,...V'_M and compute the Wasserstein metric (a simple LP). I'm using Wasserstein here but a quantile related metric may also be useful.
Hi, is that possible to add a deterministic upper bound? The intuition is that, since the lower bound is the outer approximation of the value function, the upper bound can be calculated by the inner approximation (naturally). This paper discussed this approach. https://doi.org/10.1137/19M1258876
to add a deterministic upper bound?
I have no plans to do so. Note that the formulation SDDP.jl uses is non-standard in the literature. We can handle integer variables, non-convex subproblems, and we have objective and belief state variables.
A much more problematic issue is that the inner approximation requires significantly more computational effort. So it doesn't really make sense to use it. I think the stopping rule outlined above more closely matches what people expect.
p.s. I see you have https://github.com/zidanessf/RDDP.jl. I opened a couple of issues. Happy to chat about anything in more detail
I think the inner approximation in this form has little computational effort. min f_t(x) + Σλ_kV_k + penalty * (x⁺ + x⁻) s.t x ∈ X Σλ_kx_k + x⁺ - x⁻ = x where (x_k,V_k) are sample points Besides, the inner approximation should converge to the lagrangian relaxation of an nonconvex function, so it's probably suitable for the SDDiP, but not sure for the case with objective and belief state variables. However, in my experiment with the upper bound set as inner approximation and the lower bound generated by lagrangian cut, the bounds converges very slowly. Maybe it's the lagrangian cut's fault xD.
A few points on the computational effort:
- You're right that we could apply the upper bound in a limited subset of cases. But my experience is that leads to confusion when people implement models and things don't work.
- There's a trade off: should I compute more lower bounding cuts or an upper bound? For every minute spent on the upper bound, you could have a better policy
- If you have a good upper bound, what would you do with it? Most people just want a good policy.
- Does a small gap translate into a good policy?
The last point is pretty subtle: it often happens that the gap can be very small, but if you look at simulations of the policy the performance is great for 98% of the simulation runs, and terrible in the 2% (i.e., you haven't added cuts along those trajectories).
Because those bad trajectories only account for 2% of the total, and they might not be very terrible, their total contribution to the objective function may be very small. Thus, you can have a small gap even with visibly poor trajectories!
The stopping rule about attempts to quantify this: you want to stop when things "look" good, regardless of the exact quantitative performance of the policy.
Maybe it's the lagrangian cut's fault
O boy yes, the Lagrangian cuts are tricky to get right. I've had a few goes with little progress.
Maybe I need to revisit the upper bounds. I know @frapac did the original experiments here: https://github.com/frapac/DualSDDP.jl
@zidanessf: I just spoke to some folks how are hoping to have a postdoc work on SDDP.jl. They mentioned the same upper bound :) I now understand how it works much better.
If they get the funding, we should have more to report on this front.
They also had some good ideas for how to use the upper bound in sampling.