ocaml
 ocaml copied to clipboard
ocaml copied to clipboard
Implement quality treatment for asynchronous actions in multicore (3/3?)
Here is for your consideration a simplification of the remaining commits at #11057 (after #11095 and #11190).
This PR includes various fixes for soundness and performance of async actions.
In particular there is a bug whereby caml_enter_blocking_section can loop waiting for another domain to process its signals (since caml_check_pending_signals is shared between all domains). The PR #11057 proposed two different ways to fix this:
- One was to introduce a distinction between "external" and "internal" interrupts (https://github.com/ocaml/ocaml/pull/11057/commits/4fbd1225ec at #11057). (External Interrupts)
- One is to delay the setting of
young_limitin case action are pending until one returns to OCaml code (this PR, https://github.com/ocaml/ocaml/pull/11307/commits/93dd8f28db). (Optimal Polling)
Optimal Polling fixes more things than External Interrupts, and while the resulting implementation is simpler to understand, it is more invasive (e.g. changes to .S files). So I originally intended it for a part 4/4 of this PR series not needed for 5.0.
While rebasing this PR, I realised that the simplifications Optimal Polling brought were greater than thought (also, there might be a bug in the current implementation of External Interrupts, so I would have to look at it again). So I decided in a first time to skip the External Interrupts design, so that you do not have to review two separate designs (where the second one undoes the changes of the first one), and go directly for the "nice" design. (For explanations of the "nice" design, see the lengthy documentation comments and commit logs.)
If you prefer starting with External Interrupts first, then we can delay the review of Optimal Polling until 5.1. If you like the Optimal Polling approach, then I will write a test to ensure that any future architecture implements the necessary code when returning from C to OCaml.
Commit logs have been updated to reflect previous discussions (cc @xavierleroy).
The commits are best reviewed separately. In case of the "Optimal Polling" commit, looking at the resulting implementation (and checking that it matches the description in the comments) might make more sense than looking only at the diff.
(cc @sadiqj, @gasche, @kayceesrk.)
Hey! Thank for this PR. Is it ready for review at the moment? I am willing to take a look at it, at least for the parts I can understand well enough.
Yes, it is ready for review. I consider it in polished state after several rounds of self-review. I have not followed the 5.0 alpha business but given the fixes it brings (and the fact that it is a pre-requisite for #11272), it is intended for 5.0.
Concerning the alpha business, all fixes are still in scope for 5.0 during the alpha and beta release phase. Please don't hesitate to ping me on PRs that should be integrated in 5.0 once reviewed.
I also saw you mention that for this "zero" release, C runtime API can still change, so I can ping you for things like #11272 and things related to #10992, do I understand correctly?
Indeed, those kind of known possible C runtime API changes are one of the reason we have this 0th alpha release with less stability guarantees than an ordinary alpha.
@sadiqj @gasche @kayceesrk This fixes bugs for 5.0 and it is a pre-requisite for #11272. Is anyone planning to have a look?
Is anyone planning to have a look?
Not this week as I am busy with other things.
Regarding review: I was currently attempting to wrap up mine, but it seems Github got lost on your last force push and lost half of my comments. Sorry for the noise, I will wrap it up properly shortly.
Very sorry about this. I was not aware of this effect of force pushes. Are they not accessible from the old branch https://github.com/ocaml/ocaml/commit/d549824d6a4e1026643feaead4b0dceeb99c891b ?
I think it had to do with how the Github UI records comments when you do a review commit by commit, force-push probably messed with this, I know now not to trust this too much. :-)
I could only have a very quick look, but your "optimal" strategy is already making me nervous performance-wise. caml_c_call is a hot path in ocamlopt-generated code, so adding a load and a test there can have significant costs. A round of Sandmark bechmarking is needed before we can go any further in this direction.
Remember that 99% of OCaml programs do not handle signals. I don't want to penalize them to avoid corner cases in the remaining 1%. We've already paid enough with the polling points.
I'll look into having benchmarks for this PR.
The reasoning performance-wise is that the additional check involves a correctly-predicted branch, which can be free, and a load from a cache line that is already accessed in the same code. In addition the check is not needed (and not implemented) after "noalloc" C calls.
(This does not affect this PR, but I do not think that the "1%" figure is a good estimation to have in mind regarding asynchronous callbacks: 1) we have already seen that interrupts are fairly commonly used in some application domains dear to OCaml, and 2) if we keep pathological corner-cases then users of memprof and finalizers are also affected even when those callbacks do not raise.)
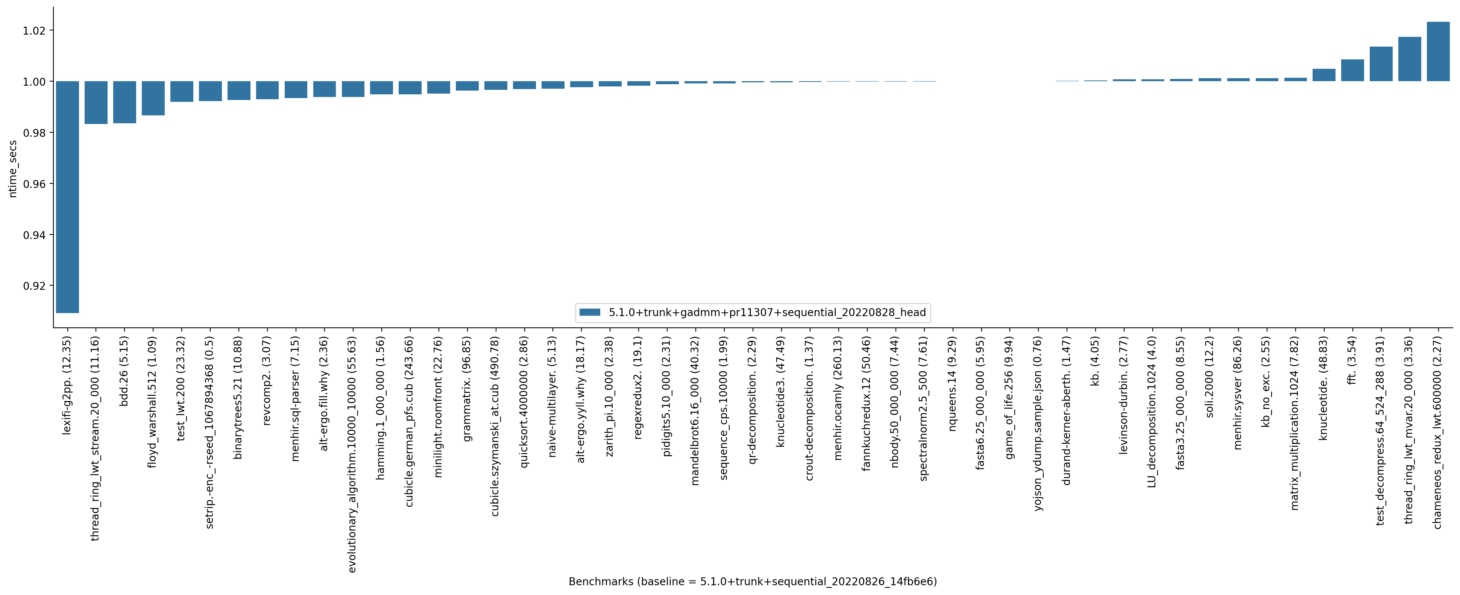
Here are results of sequential benchmarks:
Turing host:
Navajo host:
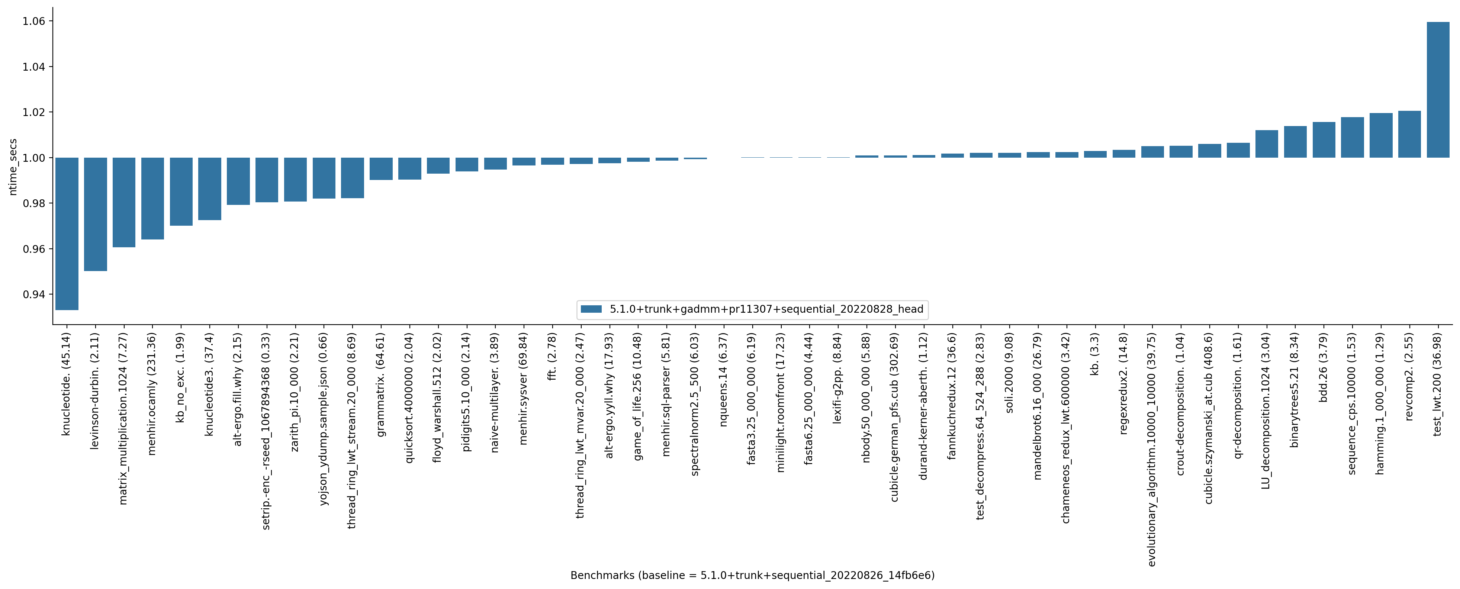
I do not see anything too striking in these results, but I am not very familiar with this benchmark suite. The turing one looks favourable but I do not have an interpretation to offer for the good results.
I am running additional benchmarks to see if the sensitivity of lwt-based benchmarks is related to fd3db5e (new unconditional polling after every blocking section). These lwt benchmarks look like micro-benchmarks, so such a slowdown (if actually caused by this change) might not be representative of real programs.
I am considering withholding the commit "Check actions unconditionally when leaving a blocking section" for now. There is a chance that it affects the lwt micro-benchmarks and although I do not think there is an issue with it, it is not needed as a bugfix.
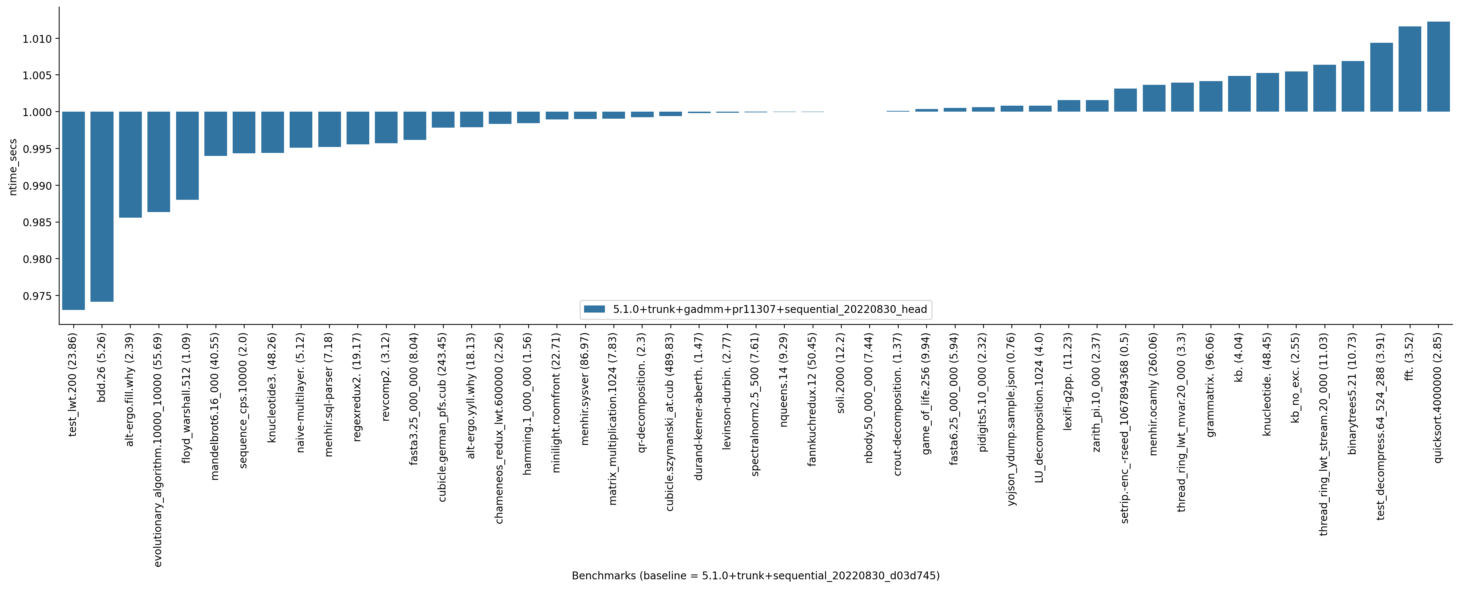
Here are the new results without this commit:
Turing:
 Navajo:
Navajo:
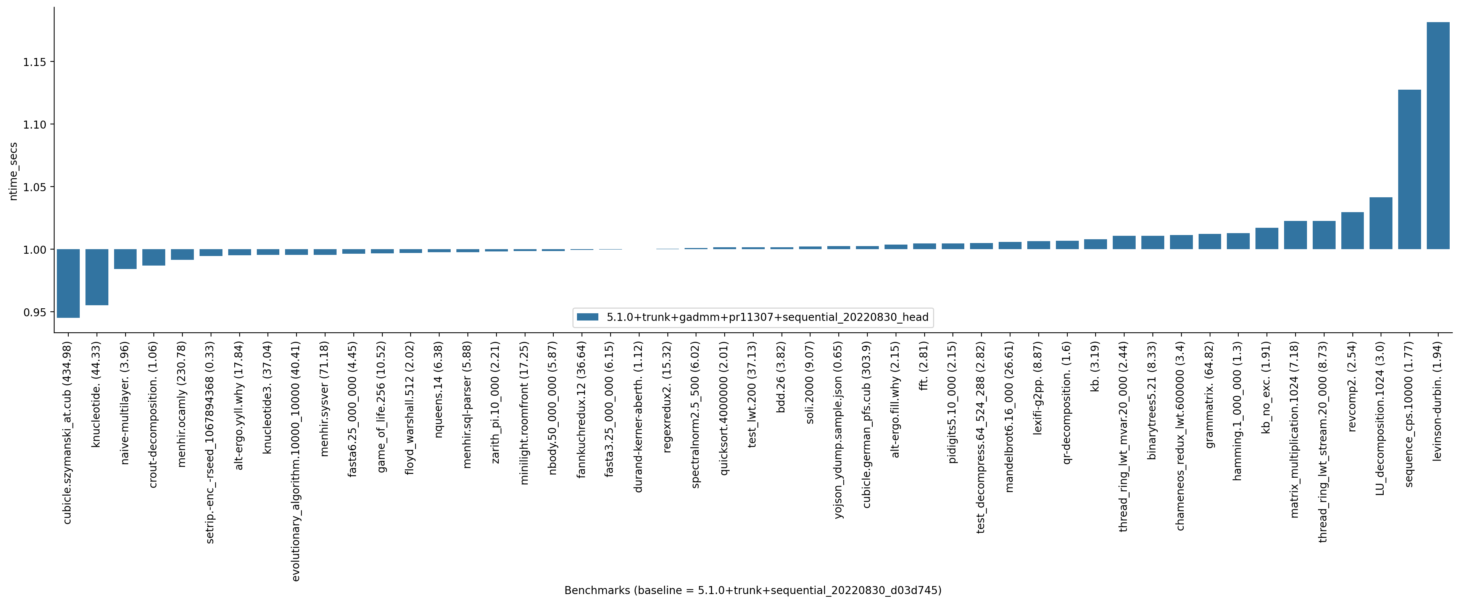 (note that there are similar variations on navajo for levinson_durbin, sequence_cps and other bechmarks when comparing trunk with itself as well; this is not related to this PR)
(note that there are similar variations on navajo for levinson_durbin, sequence_cps and other bechmarks when comparing trunk with itself as well; this is not related to this PR)
Withing the limits of sandmark benchmarks, the results seem favourable.
Since the change is quite invasive, I am very tempted to move this PR to the 5.1 milestone to give more time to the reviewers and alternative designs.
I do not really understand what is blocking this PR. The original PR was split in several PRs after people asked for it, the series of PRs was not designed to be merged in separate releases (except where otherwise indicated). Also I am not aware of alternative designs being proposed at this point, and this is the only one that relies on a well-defined mechanism as opposed to playing poke-a-mole with ill-behaving corner-cases.
Re: benchmarks.
@kayceesrk suggested that I look at the newly added perf output in sandmark nightly. I looked at it a while ago but there was not much to conclude from it. Some benchmarks show a noticeable instruction count increase, e.g. 1% for quicksort. This turned out to be due to calling the generic C comparison function caml_lessthan on integers, and thus making so many short-lived C calls that the 2 instructions added when returning from C calls amounted for this 1% extra instruction count. The conclusion is that this benchmark is far from representative of actual code. Despite this, there does not seem to be a clear measurable slowdown: the current sandmark runs show a slowdown, the earlier runs as well as my own tests show a speedup (for one particular layout of code, etc.).
I think it does not make sense to request sandmark benchmarks for things like adding a well-predicted branch with a short condition in a couple of locations. At the OCaml workshop I showed that one can add a well-predicted branch inside the hottest loop of the runtime and see no significant impact on performance, yet to attest this required far more precise and time-consuming measurements than what sandmark gives us.
Shortly:
-
What is "blocking" the PR. Our reviewer time is limited by human factors and this PR requires more review before being mergeable. On the other hand, Florian's job as our release manager is more or less to get 5.0 out as fast as reasonably possible. In this context, we don't want this PR "blocking" things.
Reviews on this PR are not "blocked", they can happen whenever independently of the release schedule, it just looks like everyone is working on something else right now that they assume has higher priority. Note that in currently the runtime maintainers do not consider "asynchronous actions" a priority. (I believe that it is important at least for statmemprof, but statmemprof support is not expected in 5.0. You fixed bugs in the Threads implementation, and this very nice, but we could possibly live with a couple remaining bugs for 5.0, there will be more releases. Personally I think the most important aspect is that we collectively shared a better understanding of the Threads codebase -- and the fact that several pain points remain there.)
the series of PRs was not designed to be merged in separate releases
What are the risks with having a release in-between?
-
I don't know why you consider that short-lived C calls are "not representative of actual code", to my knowledge they are the only portable way to access C-supported intrisics from OCaml (say popcount, etc.), so they could easily occur in performance-critical loops. It is only representative of some actual code, not of most existing code, but having some benchmarks detecting this in Sandmark sounds reasonable. (I have no opinion over whether this particular benchmark should do this. Did you open an issue against Sandmark to discuss this?)
-
Even when Sandmark is not accurate enough to analyze the performance impact of a change, people get reassured by the pretty pictures showing white noise. Don't laugh! It's worth running Sandmark if only to show that there is no noticeable large performance impact.
Thanks for the reply @gasche. I am aware that OCaml 5.0 is expected to be buggy, I was more worried about the mention of alternative designs, as I am not aware of any.
-
The first commit deals with hard-to-reproduce crashes in corner cases. A large number of packages define signal handlers for various signals (sometimes to raise exceptions, but not always), but it is hard to be sure that any will be affected. I am most worried about signals coming when
domain_stateis not available (e.g. inside a non-ocaml thread spawned by foreign code) but it is hard to tell how serious it is, in part because I am not very familiar with how such situations arise. (This would have been UB even before multicore, but accidentally working in practice, because the previous C signal handler was not thread-safe either. Since this probably used to work in practice, we cannot use this to rule out that the situation exists.)The third commit fixes a situation where it is still possible to have an asynchronous exception arising when allocating from C code. This is contrary to the current bold claims in the documentation, but it was unnecessary to propose a separate fix to the documentation with a better fix in the pipeline.
The second commit is cosmetic and the fourth one addresses a theoretical performance concern about the strategy of the first commit (it is also a step towards a simpler implementation of masking, but this is not important here). I would not have proposed the first commit without the fourth one, but the fourth can be omitted for 5.0.
I can propose the first commit and the third commit for 5.0, which should be seen as less invasive than the whole PR. (In hindsight, I could have proposed this a while ago, given better communication about the release schedule of OCaml 5.0 and its expected state when released.)
-
Note that
noallocC calls are not affected by the change (so this excludespopcnt, etc.).* Anyway the lesson is that with an unrealistic proportion of instructions taken by OCaml-to-C switching, we could still not distinguish a significant impact.(*unrelated: IIUC,
caml_compareis non-noalloc because it needs to raise exceptions sometimes, and this gave me the idea that, if performance is important in this particular case (with or without this PR), it would be possible to letnoalloccalls raise exceptions in a new calling convention where any exception raised is returned encoded; in other words making anoalloccall to somecaml_compare_exnfunction.) -
It is fine and natural to ask a benchmark for the PR as a whole to see if there is not an impact as you describe (we have such results, and they show no such large impact, so far so good). This is missing my point. Sandmark cannot let you see if there is an impact of adding a well-predicted branch in a hot location in the code. It is like trying to use a magnifying glass to study bacteria. In this case, sandmark might randomly be slightly skewed one way or another in a repeatable way (because it goes out of its way to repeat the same random spot in the possible outcomes). As for instruction count, a large increase then turns out to be due to the micro nature of the benchmarks (and is not a good measure when the argument for good performance is increased IPC). This has none of the reassuring effect you seek and wastes a lot of time in trying to interpret non-existent effects; it also incites to be overly cautious (as I think I was for #11506 due to sandmark).
This is now rebased.
The commits descriptions have been updated and clarified, hoping this helps. Nothing has changed in the code.
The first commit (interrupt all domains inside the C signal handler) fixes the following testcase. This is an example where the domain receiving the signal is not the most able to handle it.
let break_trap s =
(try while true do () done
with Sys.Break -> print_endline "[Sys.Break caught]" ) ;
print_endline s
let () =
Sys.catch_break true ;
let d = Domain.spawn (fun () -> break_trap "Still alive") in
break_trap "There is research to be done." ;
Domain.join d ;
break_trap "We do what we must because we can." ;
print_endline "I'm making a note here: Huge success."
In trunk, Ctrl-C will interrupt the first call to break_trap. It will hang on the second call to Ctrl-C: SIGINT is received by domain 0, which is stuck on Domain.join, whilst domain 1 is stuck in a loop and is never interrupted no matter how many times you press Ctrl-C. (You need to kill -9 the program.)
(You can remove Sys.catch_break true and try it in the toplevel, it also "works" in bytecode.)
With the present PR, you get an interaction like the following:
^C[Sys.Break caught]
Still alive
^C[Sys.Break caught]
There is research to be done.
^C[Sys.Break caught]
We do what we must because we can.
I'm making a note here: Huge success.
The theory says that someone using threads and signals together will use masks to direct the signal to the right thread/domain. However, beyond the toplevel, one can imagine that for simple script-like usage the programmer will simply call Sys.catch_break true and be happy to interrupt the program by pressing Ctrl-C enough times. Incidentally, it is not a fabricated example: I found it by chance while working on another issue.
I am adding a test to the suite inspired by this example.
After all this time, it's still not clear to me what the performance impact of these changes are on programs that do not handle signals, which I still think as the overwhelming majority. Could you recapitulate this for me? I'm not asking for more measurements yet, just a recap of your intuitions on what could be a performance impact / very likely has no performance impact. Thanks.
Assuming a program either does not set up OCaml signal handlers, or does not receive signals (but maybe uses other async callbacks: finalisers, memprof callbacks):
- "Do not access the TLS from signal handlers":
- No impact (e.g. replace a plain read by a relaxed atomic read)
- "Simplify spawning of threads and domains":
- No impact (remove code that was only useful for users of signals)
- "Do not raise from caml_thread_yield":
- ~Correctness issue: fixes a bug whereby other kinds of callbacks could raise in those locations, but should not.~ Edit: no impact.
- "Optimal polling in C code based on masking"
- Potential negative impact: add a load+test+branch in two locations (the end of
caml_c_callandcaml_c_call_stack_args): ruled negligible (cache-local data & statically well-predicted branch) - Potential negative impact: add calls to
caml_update_young_limit_after_c_callinside callback.c: idem; in addition, the rest of function bodies looks comparatively expensive, so it did not seem worth it to make the function call inlinable - Potential negative impact: add calls to
caml_update_young_limit_after_c_callin interp.c: idem; in addition the cost looks even more negligible inside the interpreter - Positive impact: avoids taking the slow allocation path in C code if other kinds of callbacks than signal handlers are pending (or are believed to be pending: OCaml forces the examination of all callbacks twice per minor cycle, which will also cause these repeated slow paths)
- Potential positive impact: guard the function call to
caml_process_pending_signals_exninside ofcaml_enter_blocking_section(negligible)
- Potential negative impact: add a load+test+branch in two locations (the end of
triage meeting: @kayceesrk to review PR and look for a minimal change for 5.1 to fix #12253, with the remainder of fixes targetted at trunk.
Thanks @kayceesrk for having a look. I have seen your question about a minimal fix for 5.1; I'll answer shortly.
Thanks @kayceesrk for having a look. I have seen your question about a minimal fix for 5.1; I'll answer shortly.
Thanks a minimal fix would be incredibly useful.