Allow iteration blocks to have an optional extra index parameter (alternative to `-n` flags)
Description
This implements my solution to https://github.com/nushell/nushell/issues/4605#issuecomment-1296243929. Alters all, any, each while, each, insert, par-each, reduce, update, upsert and where so that their blocks take an optional extra parameter containing the index. This is meant to be a replacement for -n (which is agreed to be unnecessarily verbose by me and the issue creator) for those commands that support it (only each while, each, par-each and where) and adds this index-accessing functionality to the others.
reduce, as a result, may take 3 parameters (element, accumulator, index) as well as 2, 1 or 0. The others now may take 2 parameters, 1 or 0.
I did NOT change for, even though it also uses -n, because I ran into some difficulties (involving duplicate var_ids) and decided to leave it to the experts.
This also adjusts various help strings and adds examples for the new functionality.
-n is now listed as deprecated in the help for the aforementioned commands (negotiable).
NO FUNCTIONALITY HAS BEEN REMOVED YET.
Any remarks or recommendations for coding/implementation are welcome.
Tests + Formatting
Make sure you've done the following, if applicable:
- Add tests that cover your changes (either in the command examples, the crate/tests folder, or in the /tests folder)
- Try to think about corner cases and various ways how your changes could break. Cover those in the tests
Make sure you've run and fixed any issues with these commands:
cargo fmt --all -- --checkto check standard code formatting (cargo fmt --allapplies these changes)cargo clippy --workspace --features=extra -- -D warnings -D clippy::unwrap_used -A clippy::needless_collectto check that you're using the standard code stylecargo test --workspace --features=extrato check that all tests pass
User-Facing Changes
If you're making changes that will affect the user experience of Nushell (ex: adding/removing a command, changing an input/output type, adding a new flag):
- Get another regular contributor to review the PR before merging
- Make sure that there is an entry in the documentation (https://github.com/nushell/nushell.github.io) for the feature, and update it if necessary
Definitively an interesting enhancement! You really get a hang of the code base!
Do you have some before and after code samples for the PR description to make it easier for others to quickly get a sense of it?
I personally are not so sure if I like it to be implicit:
Assuming we get a first class match expression, I think it is not inconceivable that there is the desire to be able to destructure the closure or command arguments. This would conflict with automagical behavior at the call site in the each etc. implementation if you have a command that internally takes variadic arguments.
I think in this area I probably would favor a more explicit solution like a enumerate iterator adaptor as found in Rust, Python etc.
Do you have some before and after code samples for the PR description to make it easier for others to quickly get a sense of it?
Before:
[1 2 3] | each -n { if $in.item == 2 { echo $"found 2 at ($in.index)!"} }
After:
[1 2 3] | each {|e i| if $e == 2 { echo $"found 2 at ($i)!"} }
Before:
each -n {|elem| mv $elem.item ($elem.index + 1 | into string | $in+ '.jpg')}
After:
each {|name num| mv $name ($num + 1 | into string | $in + '.jpg')}
Assuming we get a first class match expression, I think it is not inconceivable that there is the desire to be able to destructure the closure or command arguments. This would conflict with automagical behavior at the call site in the each etc. implementation if you have a command that internally takes variadic arguments.**
Would it really cause a conflict? I imagine destructuring syntax would resemble JS: turn {|e| ... } into {|{index, item}| ... } if the input is a {index, item} record (such as for -n) and {|[e]| ... } if the input is a list (such as from a list-of-lists). It's still clear there that it's destructuring just the first argument of the block.
I think in this area I probably would favor a more explicit solution like a
enumerateiterator adaptor as found in Rust, Python etc.
This sounds like another good idea, but I sense a problem: an enumerate command (used like ls | enumerate | where ...) would be worse than the current -n behaviour, as it would explicitly change the input into something like
[[a b]; [foo 1] [bar 4]] -> [{item:{a:foo b:1}, index:0}, {item:{a:bar b:4}, index:1}], which A) would be output by the where instead of the original table rows, and B) is just as verbose as -n (without destructuring syntax to help).
to my eye, i love this change and how it has an optional index. great work @webbedspace!
Quick thing I just noticed: the CI runs test::test_examples (the examples embedded in the fn examples(&self) calls) but cargo test --workspace --features=extra seemingly doesn't. What gives?
an
enumeratecommand (used likels | enumerate | where ...) would be worse than the current-nbehaviour, as it would explicitly change the input into something like[[a b]; [foo 1] [bar 4]]->[{item:{a:foo b:1}, index:0}, {item:{a:bar b:4}, index:1}], which A) would be output by thewhereinstead of the original table rows, and B) is just as verbose as-n(without destructuring syntax to help
I agree, as we don't have something like tuples and don't support destructuring lists at the moment that would be unergonomic. So no convenient enumerate at the moment.
Q: How would this behave on a command that declares only a ...rest signature.
I imagine destructuring syntax would resemble JS: turn
{|e| ... }into{|{index, item}| ... }if the input is a{index, item}record (such as for-n) and{|[e]| ... }if the input is a list (such as from a list-of-lists). It's still clear there that it's destructuring just the first argument of the block.
In this solution it is certainly ergonomic at the moment, but overloads the implementation of the caller based on the signature of the callee. I think in most languages you would expect that the implementation of the callee is overloaded and the variant is chosen based on (run-time) known input. (imagine you want to have something taking a List or a scalar, this would coerce to the "list" of value and index)
Defining syntax and semantics for callee overloading is easy but I don't know if caller overloading is as easy to replicate in nu code (well if you do reflection on the signature yeah kinda.)
I certainly see the ergonomics of this and nu should have nice things, and I don't want to necessarily force nu in either a Python or Haskell direction, so please overrule me if this concern is too hypothetical.
I like this change. I found a place where I think you accidentally disabled some tests.
One thing your change highlighted we should probably also fix. In examples, whenever we have more than one param, we should give them names. Something like this isn't going to be readable by most folks:
r#"[18 19 20] | reduce -f 0 {|e a i| $a + $i } | to nuon"#
what's e, a, i? No idea.
For the two param form, I think we should use:
{|item index| $item + $index}
and the example above could be:
r#"[18 19 20] | reduce -f 0 {|item accum index| $accum + $index } | to nuon"#
It makes the examples a little longer, but I think quite a bit easier to read.
what's
e,a,i? No idea.
Those are standards I use when writing one-liner iteration loops using JS's .reduce(). They are: element, accumulator, index. I consider them roughly equivalent to i = 0 in for-loops, but I don't actually know whether this is even that common among devs. (I admit I tend to use .reduce() a bit more than the average human…)
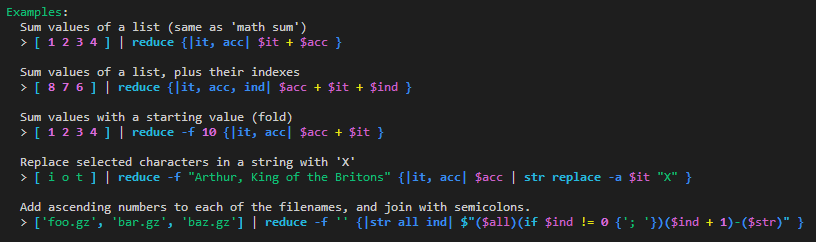
By the way, [18 19 20] | reduce -f 0 {|e a i| $a + $i } | to nuon is not a user-facing example, but part of the test suite. So, I won't change that specifically. The actual user-facing examples are these:
@webbedspace - the feedback is more about general readability of the code. So a test example should be readable by developers who come after you and help keep the code working. Best to change the test as well as the user-facing examples.
I haven't looked at the code changes yet but this feature change sounds pretty good to me.
I think that the following builtins may be replaceable by using more basic iteration utilities together with an index available during the iteration:
drop ntheverygroup(we could introduce new commandgroup-bytaking a closure, and use modulo operator with that for what wasgroup)
Oh you're right I missed group-by in category default. Do you think it should be modified to (also?) accept a block/closure, with the optional index parameter?
The thing about your example is that group does something entirely different to group-by. group-by is already commonly known in other libraries like lodash, and returns a record of lists. group simply produces a list of lists, and doesn't really have a common name (being called "chunk" in lodash and "splitEvery" in ramdaJS, and packages using each of those names exist for Haskell).
Yes you're right. I would personally go for chunk or chunks or chunked based on lodash and Python libraries, and leave "group*" to refer to groupings without an implied ordering.
The code generally looks good to me and this seems like a solid improvement, thank you!
I agree with JT on the e, a, i variable naming. Also probably worth removing the "Q: Does this have to use a match expression..." comments, as explained in https://github.com/nushell/nushell/pull/6994#discussion_r1024635708
The thing is, though, at the bottom of those match blocks is a match for PipelineData::Value(x, ..), meaning that it accepts non-iterators anyway. So, the difference between this and any/all is currently negligible.
You're right, it's so far down that I missed that. Operating on single values feels wrong to me but maybe we should discuss that more widely to confirm.
(commenting here because GitHub's glitching out and not letting me reply in the actual thread)
@webbedspace I'm sorry to be a stickler on this but I think one of the things we're waiting on is for |e i| to be changed to |elem idx| or something other than just two letters. I think it's fine when there is only one like |e| and you've already fixed the |e a i| ones. We just prefer the more readable and verbose version. After this change, I'll vote to land because I love this functionality!
Also, I labeled as a breaking-change because I believe it removes the -n params.
The thing is, though, at the bottom of those match blocks is a match for PipelineData::Value(x, ..), meaning that it accepts non-iterators anyway. So, the difference between this and any/all is currently negligible.
You're right, it's so far down that I missed that. Operating on single values feels wrong to me but maybe we should discuss that more widely to confirm.
Strong vote from me that non-iterable values such as int/decimal/bool/datetime/filesize etc should not be accepted by iteration interfaces such as all, each etc. (Sorry if I misunderstood the conversation; I haven't been able to follow closely here)
I agree (especially regarding plain records and each), but that isn't in the scope of this PR.
@webbedspace I think this look good. If you can fix the conflicts I'll sign off on it. Thanks for all your effort here.
Mhh the par-each test failed with a different result order? Has the behavior with regards to ordering enforcement changed or was this test added with this change and somehow flew under the thread radar.
IIRC, there is a rayon option to retain ordering. I assumed we were using that but maybe not? I can't remember exactly what that feature is in rayon though. :(
It seems that par_bridge may not support it? https://docs.rs/rayon/latest/rayon/iter/trait.ParallelBridge.html
The resulting iterator is not guaranteed to keep the order of the original iterator.
https://github.com/rayon-rs/rayon/issues/551 https://github.com/rayon-rs/rayon/issues/669
That was a mistake - there are actually two versions of that test, and the other one is in par_each.rs and only uses list<int> as a check instead of an ordering.