knowit-rock
 knowit-rock copied to clipboard
knowit-rock copied to clipboard
ROCK model for Knowledge-Based VQA in Videos
ROCK: Retrieval Over Collected Knowledge
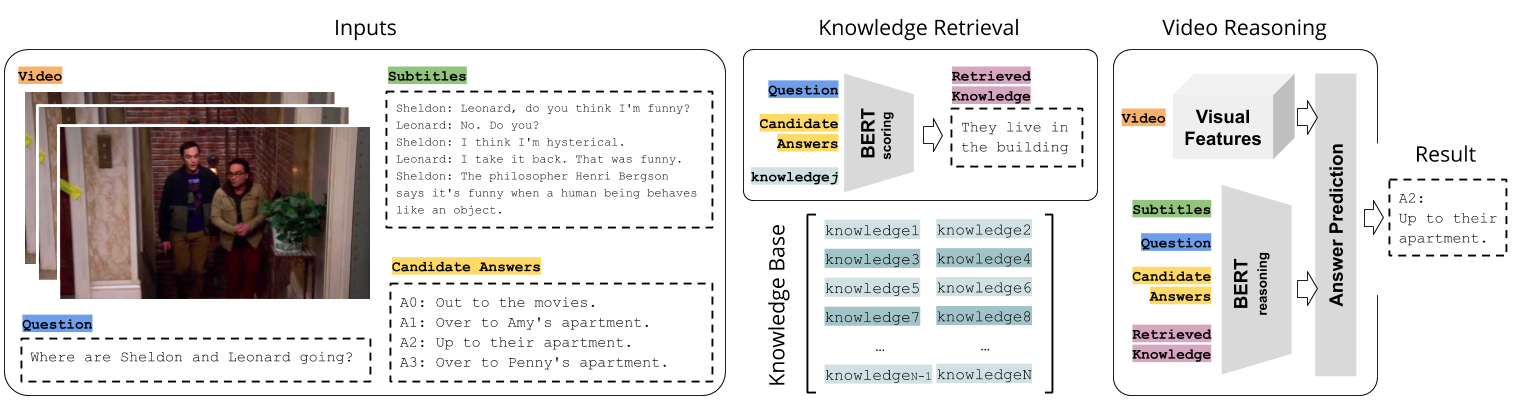
ROCK is a model for Knowledge-Based Visual Question Answering in Videos. It is the first model that incorporates the use of external knowledge to answer questions about video clips. ROCK is based on the availability of language instances representing the knowledge in a certain universe (e.g. a TV show), for which it constructs a knowledge base (KB). The model retrieves instances from the KB and fuses them with language and spatio-temporal video representations for reasoning and answer prediction.
Check the project website here.
Setup
-
Clone the repository:
git clone https://github.com/noagarcia/knowit-rock.git -
Download the KnowIT VQA dataset and save the csv files in
Data/. -
Install dependencies:
- Python 3.6
- numpy (
conda install -c anaconda numpy) - pandas (
conda install -c anaconda pandas) - sklearn (
conda install -c anaconda scikit-learn) - visdom (
conda install -c conda-forge visdom) - pytorch 0.4.1 (
conda install pytorch=0.4.1 cuda90 -c pytorch) - torchvision (
conda install torchvision) - pytorch-pretrained-bert 0.4.0 (
conda install -c conda-forge pytorch-pretrained-bert=0.4.0)
Note: Make sure to install pytorch-pretrained-bert instead of its newest version pytorch-transformers.
ROCK Model
ROCK addresses KBVQA as a multiple choice problem, in which each question is associated with multiple candidate answers, only one of them being correct. The model has 3 main modules:
-
Knowledge Base Construction: creates a knowledge base using the samples from the dataset.
-
Knowledge Retrieval: accesses the knowledge base and finds the best instance for a specific question and answers.
-
Video Reasoning: uses the information from the video, subtitles and retrieved knoweldge to predict the correct answer.
Knowledge Base
To create the knowledge base:
sh KnowledgeBase/run.sh
The files reason_idx_to_kb*.pckl and reason_kb_dict.pckl containing the instances of the knowledge base are saved in Data/KB/.
Knowledge Retrieval
To train the knowledge retrieval module:
sh KnowledgeRetrieval/run.sh
The BertScoring model is saved in Training/KnowledgeRetrieval/.
Note: The matching scores for test and validation sets take a long time to compute.
You can download our pre-computed scores from here and save them in Data/.
Video Reasoning
We proposed 4 different models using different visual features extracted from the video clips: ROCK-image, ROCK-concepts,
ROCK-facial and ROCK-caption.
Data preparation
-
Download the video frames and save them in
Data/Frames/directory. -
Compute language embeddings:
python VideoReasoning/language_embeddings.py -
(For
ROCK-conceptsonly) Download the pre-computed visual concepts (77.2GB) from here and save the file inData/Concepts/. Visual concepts were generated with this code. -
(For
ROCK-facialonly) Download the pre-computed list of faces per frame from here (240.3MB) and save the file inData/Faces/. Character faces were recognized with this code. -
(For
ROCK-captiononly) Download the pre-computed captions per frame from here (21.1MB) and save the file inData/Captions/. Captions were generated with this code.
Model training and evaluation
- For
ROCK-image:
python VideoReasoning/process.py --vision image
- For
ROCK-concepts:
python VideoReasoning/process.py --vision concepts
- For
ROCK-facial:
python VideoReasoning/process.py --vision facial
- For
ROCK-caption:
python VideoReasoning/language_embeddings.py --use_captions
Pretrained weigths
Our pretrained models are available to download from:
-
BertReasoningfrom here. Save the files inTraining/VideoReasoning/BertReasoning_topk5_maxseq256. -
ROCK-imagefrom here. Save the files inTraining/VideoReasoning/AnswerPrediction_image. -
ROCK-conceptsfrom here. Save the files inTraining/VideoReasoning/AnswerPrediction_concepts. -
ROCK-facialfrom here. Save the files inTraining/VideoReasoning/AnswerPrediction_facial. -
ROCK-captionfrom here. Save the files inTraining/VideoReasoning/AnswerPrediction_caption.
Results
Accuracy on the KnowIT VQA dataset:
| Model | Vis. | Text. | Temp. | Know. | All |
|---|---|---|---|---|---|
ROCK-image |
0.658 | 0.703 | 0.628 | 0.644 | 0.654 |
ROCK-concepts |
0.658 | 0.703 | 0.628 | 0.645 | 0.654 |
ROCK-facial |
0.658 | 0.703 | 0.628 | 0.644 | 0.654 |
ROCK-caption |
0.639 | 0.674 | 0.605 | 0.628 | 0.635 |
Citation
If you find this code useful, please cite our work:
@InProceedings{garcia2020knowit,
author = {Noa Garcia and Mayu Otani and Chenhui Chu and Yuta Nakashima},
title = {KnowIT VQA: Answering Knowledge-Based Questions about Videos},
booktitle = {Proceedings of the Thirty-Fourth AAAI Conference on Artificial Intelligence},
year = {2020},
}