ASRT_SpeechRecognition
 ASRT_SpeechRecognition copied to clipboard
ASRT_SpeechRecognition copied to clipboard
A Deep-Learning-Based Chinese Speech Recognition System 基于深度学习的中文语音识别系统
环境搭建,改成了 最新的cuda11.1 代码改成兼容 tensorflow 2.5.0-dev20201109, 运行了几个小时后,出现了 MemoryError: bad allocation 环境搭建过程: https://zhuanlan.zhihu.com/p/277569990 报错: Traceback (most recent call last): File "train_mspeech.py", line 53, in ms.TrainModel(datapath, epoch = 50, batch_size = 16, save_step...
模型训练好了,也能够测试,在自己test自己录的语音的时候,显示dataset无dict.txt文件 请问这个文件是什么?在哪儿下载? [*Info] Create Model Successful, Compiles Model Successful. Traceback (most recent call last): File "/home/gong/zyb1/ASRT/ASRT_SpeechRecognition/test.py", line 35, in r = ms.RecognizeSpeech_FromFile('dataset_test/20170001P00023A0007.wav') File "/home/gong/zyb1/ASRT/ASRT_SpeechRecognition/SpeechModel251.py", line 372, in RecognizeSpeech_FromFile r =...
您好,我已经训练了3万条语音,然后使用了您的test.py对自己的语音进行测试。出现的问题如下: 有的语音能够正常的既识别出拼音也能输出对应的文字。 然而有的语音只能输出拼音,然而程序就一直卡在了输出拼音之后,不能输出对应的文字,但也没有报错,只是程序一直在运行,如图。 (每一条语音都只有6s,是按照正常语速录音的) 想请问这是什么原因呢?应该怎么解决呢? 
测试问题

 卡在decode这个函数这边,一直在这个循环里面,有些音频会,有的音频不会,每个音频都有处理,不太清楚啥子问题 
语音片段长度
测试的时候输入的语音片段长度时固定的吗?我使用test.py测试一个十几分钟的语音文件显示格式大小不匹配。 `Traceback (most recent call last): File "test.py", line 34, in r = ms.RecognizeSpeech_FromFile('/home/user/XiJing/XiJing (1)/音频1.wav') File "/home/user/ASRT_v0.6.1/SpeechModel251.py", line 382, in RecognizeSpeech_FromFile r = self.RecognizeSpeech(wavsignal, fs) File "/home/user/ASRT_v0.6.1/SpeechModel251.py", line 362, in...
测试问题
运行test_mspeech.py 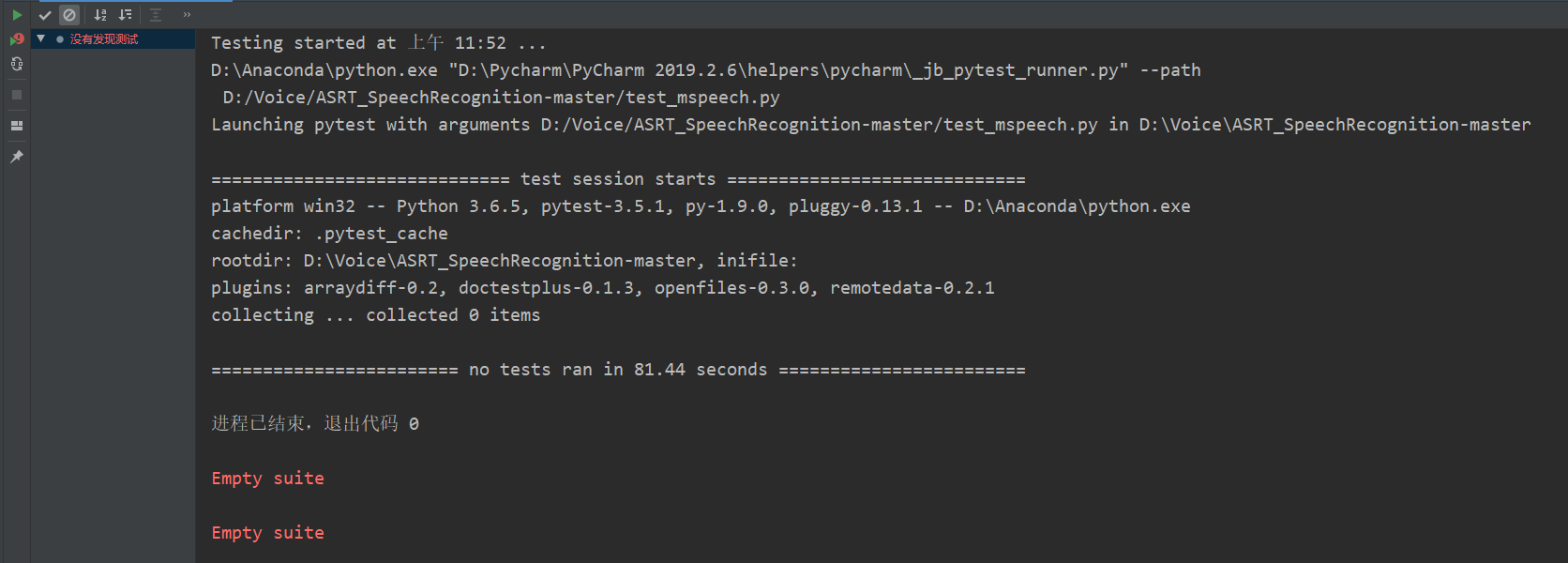 有童鞋遇见这种嘛
E:\Anaconda3\envs\nlp\python.exe F:/99_projects/codes/ASRT_v0.6.1/SpeechModel251.py Using TensorFlow backend. E:\Anaconda3\envs\nlp\lib\site-packages\tensorflow\python\framework\dtypes.py:516: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as...