mining-pool
 mining-pool copied to clipboard
mining-pool copied to clipboard
Add separate read connection for server and batch share inserts
@mar-v-in @sisou @fiaxh @styppo
This PR:
- Adds a config setting to
PoolServerfor a read-only endpoint. This is extremely important for database scalability, because while read endpoints can be duplicated, write endpoints cannot. The current implementation forces using the same endpoint for reading and writing, meaning the pool owner must use the write endpoint for both reading and writing, and therefore must scale vertically (renting larger servers) rather than horizontally (renting more servers). - Batches share insert statements, reducing the amount of queries sent to the write server for better scalability.
- Buffers the last known block ID, saving many unnecessary read requests.
This ran in production today against over 22,000 connected devices pummeling the servers. Here's the CPU graph of my write DB endpoint before applying my update (left) and after (right):
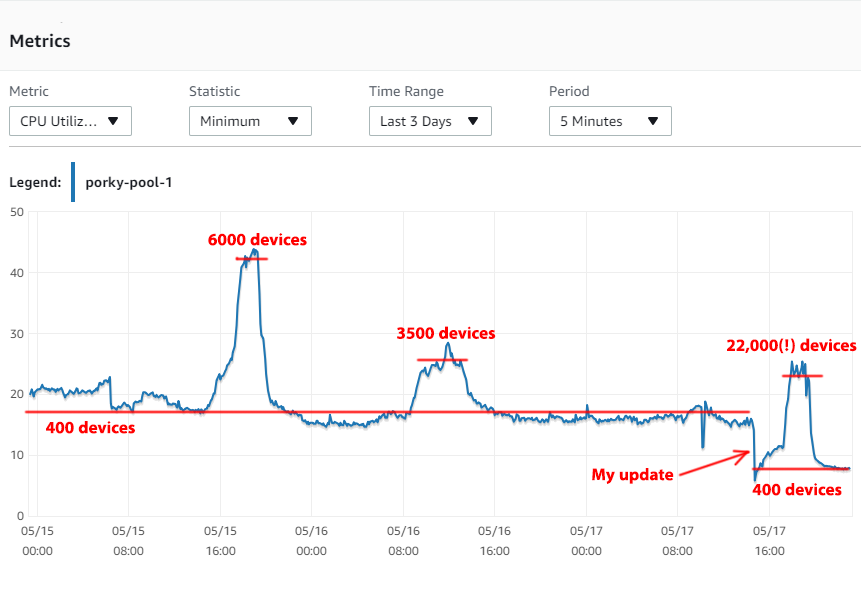
Notice that before the change:
- CPU averaged around 16% at normal load (~400 devices)
- CPU spiked to 45% for 6,000 devices
- CPU spiked to 25% for 3,500 devices
And after the change:
- CPU averages around 8% at normal load (~400 devices)
- CPU spiked to 24% for 22,000 (!) devices
Additionally, here's a snapshot of the databases under the load of 22,000 devices. Note the number of queries/sec for the write endpoint (top) vs the read endpoint (bottom):

I don't have a screenshot, but prior to this patch these numbers were almost reversed: 95% of the queries ran against the write endpoint (the other 5% being my API endpoint which uses pool_info and only calculates stats for the website).
This is an extremely important distinction, again, because if the read endpoints get overloaded they can replicate and split their work, where the write endpoint cannot.