sparseml
 sparseml copied to clipboard
sparseml copied to clipboard
Libraries for applying sparsification recipes to neural networks with a few lines of code, enabling faster and smaller models

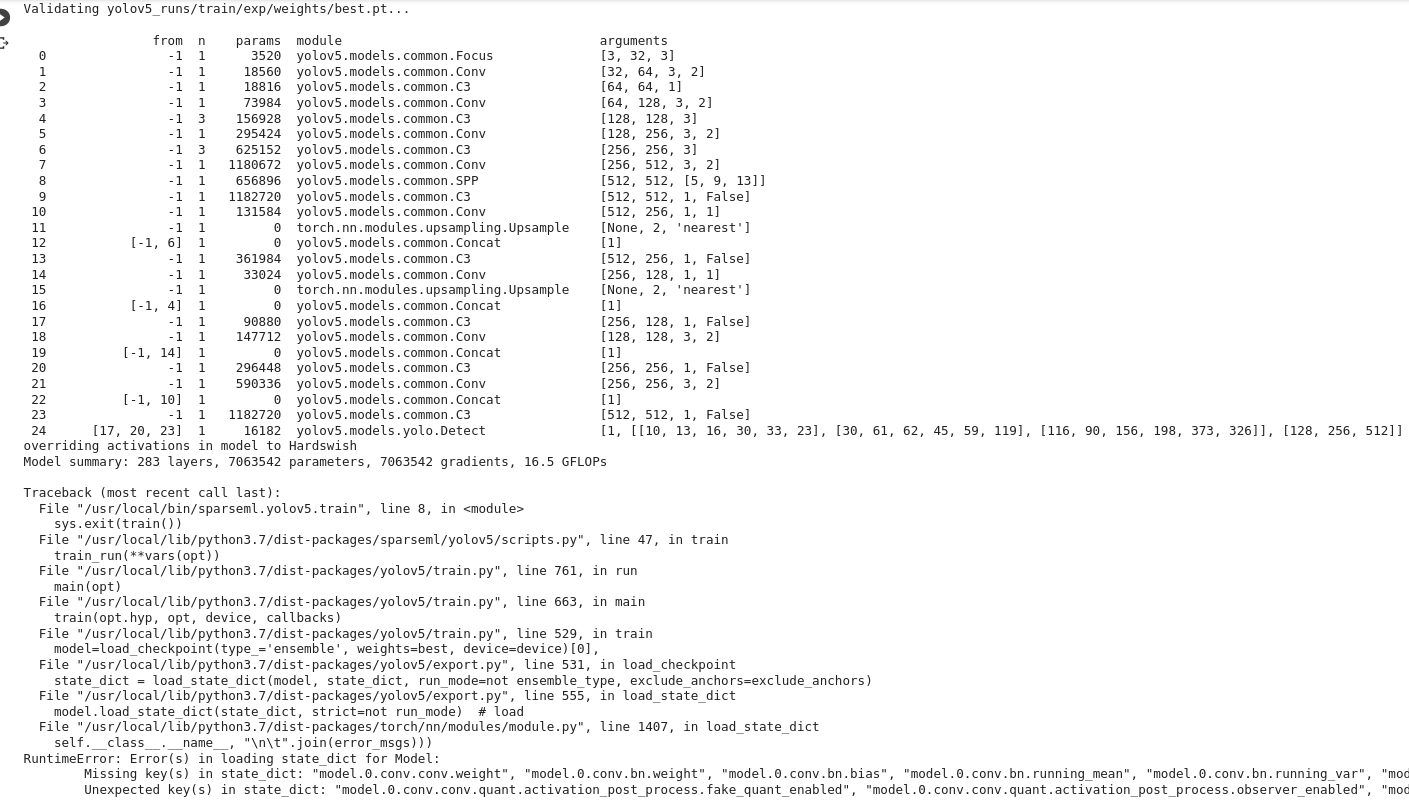 Hi, After training, the trained weights didn't load to model in validating process as you see in picture. This action accrued in export_onnx process too. thanks to neuralmagic team.
Fixes https://github.com/neuralmagic/sparseml/issues/676
**Describe the bug** In the case of masked-language-modeling experiment, inputs to the model (outputs from the tokenizer) are instances of the `BatchEncoding` class ([HF source code](https://github.com/huggingface/transformers/blob/198c335d219a5eb4d3f124fdd1ce1a9cd9f78a9b/src/transformers/tokenization_utils_base.py#L167)) which is a subclass...
Hi thanks to neuralmagic team for great repo i was using this repo for Sparse Transfer Learning With YOLOv5 in google colab but after installation ddint workout any commands including...
Fixes https://github.com/neuralmagic/sparseml/issues/1032 by ensuring `start_epoch`/`end_epoch` are always floats.
**Describe the bug** Saving a transformers model that has been trained with a modifier that has for example `start_epoch: 0.000001` breaks with the following exception: `TypeError: '
All layers in GPT-style models are implemented as custom `Conv1D` layers (see https://github.com/huggingface/transformers/blob/c60dd98e87373e7f0f5af29f3d49411c2e81fb69/src/transformers/pytorch_utils.py#L92) and thus are missed when checking for instances of `nn.Linear` or `nn.ConvNd`
**Describe the bug** I prepare a QAT only for training a roberta-large model. The output of the PyTorch saved model is not returning the values correctly. Although, I convert the...
Bumps [nbconvert](https://github.com/jupyter/nbconvert) from 6.0.7 to 6.5.1. Release notes Sourced from nbconvert's releases. Release 6.5.1 No release notes provided. 6.5.0 What's Changed Drop dependency on testpath. by @anntzer in jupyter/nbconvert#1723 Adopt...
Metadata
Owner
Metadata
Libraries for applying sparsification recipes to neural networks with a few lines of code, enabling faster and smaller models