sparseml
 sparseml copied to clipboard
sparseml copied to clipboard
model size became bigger after pruning model
my code is ..
%run train.py --batch-size 12 --img 640 --multi-scale --cfg ../models/yolov5s.yaml --device 0 --weights "D:\sparseml\integrations\ultralytics-yolov5\yolov5\runs\train\exp21\weights\last.pt" \ --data ./data/custom.yaml --hyp data/hyp.scratch_2.yaml --recipe ../recipes/yolov5s.pruned.md
It became a larger yolov5s model from 14 MB to 43 MB.
I can not figure out what is wrong..
Can you give some suggestions for me?
Hi @kuonumber, the final checkpoint should definitely not be growing in size for a pruned model. I do want to note, though, that the sparse quantized recipes will grow in size since they are storing the quantization aware training graph.
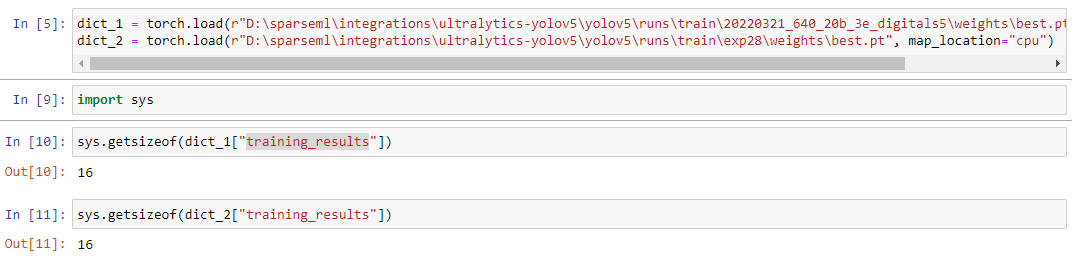
Could you run the following code on both those files and share back over the dictionary keys that are contained between those two files?
dict = torch.load(FILE_PATH, map_location="CPU")
@markurtz I want to check one thing. Does pruned model must be trainned with cpu?
I run the code you provided, and return :
RuntimeError: don't know how to restore data location of torch.HalfStorage (tagged with CPU)
@kuonumber no, the pruned model can be trained on GPU or CPU. I believe there was an auto-correct issue with the command I sent over where it forced capitalization of CPU and it should have been "cpu". Can you try the following:
dict = torch.load(FILE_PATH, map_location="cpu")
@kuonumber "training_results" is the one field in the model dict that's expected to grow over time. In my experience I've seen it grow by ~.2MB per epoch. Which doesn't fully account for your memory increase, but you may be saving more extensive training results. After loading in the dictionary as @markurtz suggested, try running sys.getsizeof(dict["training_results"]). Do this for both of your models and see if the difference in size there accounts for the difference in size between your saved .pt files.
Note that training_results and other configs are dropped when exporting the model for inference and shouldn't impact the size of your .onnx file
@markurtz I give you the all raw outputs.
The first 14 MB model
{'epoch': -1, 'model': Model( (model): Sequential( (0): Focus( (conv): Conv( (conv): Conv2d(12, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn): BatchNorm2d(32, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) ) (1): Conv( (conv): Conv2d(32, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False) (bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (2): C3( (cv1): Conv( (conv): Conv2d(64, 32, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(32, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (cv2): Conv( (conv): Conv2d(64, 32, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(32, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (cv3): Conv( (conv): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (m): Sequential( (0): Bottleneck( (cv1): Conv( (conv): Conv2d(32, 32, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(32, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (cv2): Conv( (conv): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn): BatchNorm2d(32, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) ) ) ) (3): Conv( (conv): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False) (bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (4): C3( (cv1): Conv( (conv): Conv2d(128, 64, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (cv2): Conv( (conv): Conv2d(128, 64, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (cv3): Conv( (conv): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (m): Sequential( (0): Bottleneck( (cv1): Conv( (conv): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (cv2): Conv( (conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) ) (1): Bottleneck( (cv1): Conv( (conv): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (cv2): Conv( (conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) ) (2): Bottleneck( (cv1): Conv( (conv): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (cv2): Conv( (conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) ) ) ) (5): Conv( (conv): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False) (bn): BatchNorm2d(256, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (6): C3( (cv1): Conv( (conv): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (cv2): Conv( (conv): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (cv3): Conv( (conv): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(256, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (m): Sequential( (0): Bottleneck( (cv1): Conv( (conv): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (cv2): Conv( (conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) ) (1): Bottleneck( (cv1): Conv( (conv): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (cv2): Conv( (conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) ) (2): Bottleneck( (cv1): Conv( (conv): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (cv2): Conv( (conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) ) ) ) (7): Conv( (conv): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False) (bn): BatchNorm2d(512, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (8): SPP( (cv1): Conv( (conv): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(256, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (cv2): Conv( (conv): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(512, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (m): ModuleList( (0): MaxPool2d(kernel_size=5, stride=1, padding=2, dilation=1, ceil_mode=False) (1): MaxPool2d(kernel_size=9, stride=1, padding=4, dilation=1, ceil_mode=False) (2): MaxPool2d(kernel_size=13, stride=1, padding=6, dilation=1, ceil_mode=False) ) ) (9): C3( (cv1): Conv( (conv): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(256, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (cv2): Conv( (conv): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(256, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (cv3): Conv( (conv): Conv2d(512, 512, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(512, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (m): Sequential( (0): Bottleneck( (cv1): Conv( (conv): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(256, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (cv2): Conv( (conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn): BatchNorm2d(256, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) ) ) ) (10): Conv( (conv): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(256, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (11): Upsample(scale_factor=2.0, mode=nearest) (12): Concat() (13): C3( (cv1): Conv( (conv): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (cv2): Conv( (conv): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (cv3): Conv( (conv): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(256, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (m): Sequential( (0): Bottleneck( (cv1): Conv( (conv): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (cv2): Conv( (conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) ) ) ) (14): Conv( (conv): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (15): Upsample(scale_factor=2.0, mode=nearest) (16): Concat() (17): C3( (cv1): Conv( (conv): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (cv2): Conv( (conv): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (cv3): Conv( (conv): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (m): Sequential( (0): Bottleneck( (cv1): Conv( (conv): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (cv2): Conv( (conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) ) ) ) (18): Conv( (conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False) (bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (19): Concat() (20): C3( (cv1): Conv( (conv): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (cv2): Conv( (conv): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (cv3): Conv( (conv): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(256, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (m): Sequential( (0): Bottleneck( (cv1): Conv( (conv): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (cv2): Conv( (conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) ) ) ) (21): Conv( (conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False) (bn): BatchNorm2d(256, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (22): Concat() (23): C3( (cv1): Conv( (conv): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(256, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (cv2): Conv( (conv): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(256, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (cv3): Conv( (conv): Conv2d(512, 512, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(512, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (m): Sequential( (0): Bottleneck( (cv1): Conv( (conv): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(256, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (cv2): Conv( (conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn): BatchNorm2d(256, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) ) ) ) (24): Detect( (m): ModuleList( (0): Conv2d(128, 123, kernel_size=(1, 1), stride=(1, 1)) (1): Conv2d(256, 123, kernel_size=(1, 1), stride=(1, 1)) (2): Conv2d(512, 123, kernel_size=(1, 1), stride=(1, 1)) ) ) ) ), 'optimizer': None, 'yaml': {'nc': 36, 'depth_multiple': 0.33, 'width_multiple': 0.5, 'act': 'Hardswish', 'anchors': [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]], 'backbone': [[-1, 1, 'Focus', [64, 3]], [-1, 1, 'Conv', [128, 3, 2]], [-1, 3, 'C3', [128]], [-1, 1, 'Conv', [256, 3, 2]], [-1, 9, 'C3', [256]], [-1, 1, 'Conv', [512, 3, 2]], [-1, 9, 'C3', [512]], [-1, 1, 'Conv', [1024, 3, 2]], [-1, 1, 'SPP', [1024, [5, 9, 13]]], [-1, 3, 'C3', [1024, False]]], 'head': [[-1, 1, 'Conv', [512, 1, 1]], [-1, 1, 'nn.Upsample', ['None', 2, 'nearest']], [[-1, 6], 1, 'Concat', [1]], [-1, 3, 'C3', [512, False]], [-1, 1, 'Conv', [256, 1, 1]], [-1, 1, 'nn.Upsample', ['None', 2, 'nearest']], [[-1, 4], 1, 'Concat', [1]], [-1, 3, 'C3', [256, False]], [-1, 1, 'Conv', [256, 3, 2]], [[-1, 14], 1, 'Concat', [1]], [-1, 3, 'C3', [512, False]], [-1, 1, 'Conv', [512, 3, 2]], [[-1, 10], 1, 'Concat', [1]], [-1, 3, 'C3', [1024, False]], [[17, 20, 23], 1, 'Detect', ['nc', 'anchors']]], 'ch': 3}, 'hyp': {'lr0': 0.01, 'lrf': 0.2, 'momentum': 0.937, 'weight_decay': 0.00046875, 'warmup_epochs': 3.0, 'warmup_momentum': 0.8, 'warmup_bias_lr': 0.1, 'box': 0.05, 'cls': 0.225, 'cls_pw': 1.0, 'obj': 1.0, 'obj_pw': 1.0, 'iou_t': 0.2, 'anchor_t': 4.0, 'fl_gamma': 0.0, 'hsv_h': 0.015, 'hsv_s': 0.7, 'hsv_v': 0.4, 'degrees': 0.3, 'translate': 0.1, 'scale': 0.5, 'shear': 0.0, 'perspective': 0.001, 'flipud': 0.0, 'fliplr': 0.5, 'mosaic': 1.0, 'mixup': 0.0, 'copy_paste': 0.0, 'label_smoothing': 0.0}, 'ema': None, 'updates': None, 'recipe': None, 'nc': 36, 'best_fitness': array([ 0.067075]), 'training_results': None, 'wandb_id': None}
The 43 MB model
{'epoch': -1, 'model': Model( (model): Sequential( (0): Focus( (conv): Conv( (conv): Conv2d(12, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn): BatchNorm2d(32, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) ) (1): Conv( (conv): Conv2d(32, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False) (bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (2): C3( (cv1): Conv( (conv): Conv2d(64, 32, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(32, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (cv2): Conv( (conv): Conv2d(64, 32, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(32, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (cv3): Conv( (conv): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (m): Sequential( (0): Bottleneck( (cv1): Conv( (conv): Conv2d(32, 32, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(32, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (cv2): Conv( (conv): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn): BatchNorm2d(32, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) ) ) ) (3): Conv( (conv): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False) (bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (4): C3( (cv1): Conv( (conv): Conv2d(128, 64, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (cv2): Conv( (conv): Conv2d(128, 64, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (cv3): Conv( (conv): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (m): Sequential( (0): Bottleneck( (cv1): Conv( (conv): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (cv2): Conv( (conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) ) (1): Bottleneck( (cv1): Conv( (conv): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (cv2): Conv( (conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) ) (2): Bottleneck( (cv1): Conv( (conv): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (cv2): Conv( (conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) ) ) ) (5): Conv( (conv): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False) (bn): BatchNorm2d(256, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (6): C3( (cv1): Conv( (conv): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (cv2): Conv( (conv): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (cv3): Conv( (conv): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(256, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (m): Sequential( (0): Bottleneck( (cv1): Conv( (conv): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (cv2): Conv( (conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) ) (1): Bottleneck( (cv1): Conv( (conv): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (cv2): Conv( (conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) ) (2): Bottleneck( (cv1): Conv( (conv): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (cv2): Conv( (conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) ) ) ) (7): Conv( (conv): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False) (bn): BatchNorm2d(512, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (8): SPP( (cv1): Conv( (conv): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(256, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (cv2): Conv( (conv): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(512, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (m): ModuleList( (0): MaxPool2d(kernel_size=5, stride=1, padding=2, dilation=1, ceil_mode=False) (1): MaxPool2d(kernel_size=9, stride=1, padding=4, dilation=1, ceil_mode=False) (2): MaxPool2d(kernel_size=13, stride=1, padding=6, dilation=1, ceil_mode=False) ) ) (9): C3( (cv1): Conv( (conv): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(256, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (cv2): Conv( (conv): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(256, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (cv3): Conv( (conv): Conv2d(512, 512, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(512, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (m): Sequential( (0): Bottleneck( (cv1): Conv( (conv): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(256, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (cv2): Conv( (conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn): BatchNorm2d(256, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) ) ) ) (10): Conv( (conv): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(256, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (11): Upsample(scale_factor=2.0, mode=nearest) (12): Concat() (13): C3( (cv1): Conv( (conv): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (cv2): Conv( (conv): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (cv3): Conv( (conv): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(256, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (m): Sequential( (0): Bottleneck( (cv1): Conv( (conv): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (cv2): Conv( (conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) ) ) ) (14): Conv( (conv): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (15): Upsample(scale_factor=2.0, mode=nearest) (16): Concat() (17): C3( (cv1): Conv( (conv): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (cv2): Conv( (conv): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (cv3): Conv( (conv): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (m): Sequential( (0): Bottleneck( (cv1): Conv( (conv): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (cv2): Conv( (conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) ) ) ) (18): Conv( (conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False) (bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (19): Concat() (20): C3( (cv1): Conv( (conv): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (cv2): Conv( (conv): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (cv3): Conv( (conv): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(256, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (m): Sequential( (0): Bottleneck( (cv1): Conv( (conv): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (cv2): Conv( (conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) ) ) ) (21): Conv( (conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False) (bn): BatchNorm2d(256, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (22): Concat() (23): C3( (cv1): Conv( (conv): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(256, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (cv2): Conv( (conv): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(256, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (cv3): Conv( (conv): Conv2d(512, 512, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(512, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (m): Sequential( (0): Bottleneck( (cv1): Conv( (conv): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(256, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) (cv2): Conv( (conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn): BatchNorm2d(256, eps=0.001, momentum=0.03, affine=True, track_running_stats=True) (act): Hardswish() ) ) ) ) (24): Detect( (m): ModuleList( (0): Conv2d(128, 123, kernel_size=(1, 1), stride=(1, 1)) (1): Conv2d(256, 123, kernel_size=(1, 1), stride=(1, 1)) (2): Conv2d(512, 123, kernel_size=(1, 1), stride=(1, 1)) ) ) ) ), 'optimizer': None, 'yaml': {'nc': 36, 'depth_multiple': 0.33, 'width_multiple': 0.5, 'act': 'Hardswish', 'anchors': [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]], 'backbone': [[-1, 1, 'Focus', [64, 3]], [-1, 1, 'Conv', [128, 3, 2]], [-1, 3, 'C3', [128]], [-1, 1, 'Conv', [256, 3, 2]], [-1, 9, 'C3', [256]], [-1, 1, 'Conv', [512, 3, 2]], [-1, 9, 'C3', [512]], [-1, 1, 'Conv', [1024, 3, 2]], [-1, 1, 'SPP', [1024, [5, 9, 13]]], [-1, 3, 'C3', [1024, False]]], 'head': [[-1, 1, 'Conv', [512, 1, 1]], [-1, 1, 'nn.Upsample', ['None', 2, 'nearest']], [[-1, 6], 1, 'Concat', [1]], [-1, 3, 'C3', [512, False]], [-1, 1, 'Conv', [256, 1, 1]], [-1, 1, 'nn.Upsample', ['None', 2, 'nearest']], [[-1, 4], 1, 'Concat', [1]], [-1, 3, 'C3', [256, False]], [-1, 1, 'Conv', [256, 3, 2]], [[-1, 14], 1, 'Concat', [1]], [-1, 3, 'C3', [512, False]], [-1, 1, 'Conv', [512, 3, 2]], [[-1, 10], 1, 'Concat', [1]], [-1, 3, 'C3', [1024, False]], [[17, 20, 23], 1, 'Detect', ['nc', 'anchors']]], 'ch': 3}, 'hyp': {'lr0': 0.01, 'lrf': 0.2, 'momentum': 0.937, 'weight_decay': 0.00046875, 'warmup_epochs': 3.0, 'warmup_momentum': 0.8, 'warmup_bias_lr': 0.1, 'box': 0.05, 'cls': 0.225, 'cls_pw': 1.0, 'obj': 1.0, 'obj_pw': 1.0, 'iou_t': 0.2, 'anchor_t': 4.0, 'fl_gamma': 0.0, 'hsv_h': 0.015, 'hsv_s': 0.7, 'hsv_v': 0.4, 'degrees': 0.3, 'translate': 0.1, 'scale': 0.5, 'shear': 0.0, 'perspective': 0.001, 'flipud': 0.0, 'fliplr': 0.5, 'mosaic': 1.0, 'mixup': 0.0, 'copy_paste': 0.0, 'label_smoothing': 0.0}, 'ema': None, 'updates': None, 'recipe': "version: 1.1.0\n\nmodifiers:\n - !LearningRateFunctionModifier\n cycle_epochs: 1.0\n end_epoch: 3\n final_lr: 0.01\n init_lr: 0\n log_types: __ALL__\n lr_func: linear\n param_groups: [0, 1]\n start_epoch: 0\n update_frequency: -1.0\n\n - !LearningRateFunctionModifier\n cycle_epochs: 1.0\n end_epoch: 3\n final_lr: 0.01\n init_lr: 0.1\n log_types: __ALL__\n lr_func: linear\n param_groups: [2]\n start_epoch: 0\n update_frequency: -1.0\n\n - !GMPruningModifier\n end_epoch: 100\n final_sparsity: 0.725\n init_sparsity: 0.05\n inter_func: cubic\n leave_enabled: True\n log_types: __ALL__\n mask_type: unstructured\n params: ['model.9.cv3.conv.weight', 'model.6.m.2.cv2.conv.weight', 'model.5.conv.weight', 'model.9.cv1.conv.weight', 'model.6.m.1.cv2.conv.weight', 'model.6.m.0.cv2.conv.weight', 'model.17.m.0.cv2.conv.weight', 'model.9.cv2.conv.weight', 'model.10.conv.weight', 'model.13.cv2.conv.weight', 'model.9.m.0.cv1.conv.weight', 'model.20.m.0.cv1.conv.weight', 'model.13.cv3.conv.weight', 'model.13.cv1.conv.weight', 'model.17.cv3.conv.weight', 'model.14.conv.weight', 'model.4.m.2.cv2.conv.weight', 'model.3.conv.weight', 'model.4.m.1.cv2.conv.weight', 'model.4.m.0.cv2.conv.weight', 'model.17.cv1.conv.weight', 'model.23.m.0.cv1.conv.weight', 'model.20.cv1.conv.weight', 'model.23.cv1.conv.weight']\n start_epoch: 4\n update_frequency: 1.0\n\n - !GMPruningModifier\n end_epoch: 100\n final_sparsity: 0.6\n init_sparsity: 0.05\n inter_func: cubic\n leave_enabled: True\n log_types: __ALL__\n mask_type: unstructured\n params: ['model.6.cv1.conv.weight', 'model.6.cv2.conv.weight', 'model.6.cv3.conv.weight', 'model.13.m.0.cv1.conv.weight', 'model.6.m.0.cv1.conv.weight', 'model.6.m.2.cv1.conv.weight', 'model.6.m.1.cv1.conv.weight', 'model.1.conv.weight', 'model.17.m.0.cv1.conv.weight', 'model.4.cv2.conv.weight', 'model.2.m.0.cv2.conv.weight', 'model.4.cv1.conv.weight', 'model.4.cv3.conv.weight', 'model.4.m.0.cv1.conv.weight', 'model.4.m.2.cv1.conv.weight', 'model.4.m.1.cv1.conv.weight', 'model.8.cv1.conv.weight']\n start_epoch: 4\n update_frequency: 1.0\n\n - !GMPruningModifier\n end_epoch: 100\n final_sparsity: 0.8\n init_sparsity: 0.05\n inter_func: cubic\n leave_enabled: True\n log_types: __ALL__\n mask_type: unstructured\n params: ['model.23.m.0.cv2.conv.weight', 'model.21.conv.weight', 'model.23.cv3.conv.weight', 'model.23.cv2.conv.weight', 'model.20.m.0.cv2.conv.weight', 'model.18.conv.weight', 'model.9.m.0.cv2.conv.weight', 'model.7.conv.weight', 'model.20.cv3.conv.weight', 'model.20.cv2.conv.weight', 'model.8.cv2.conv.weight', 'model.13.m.0.cv2.conv.weight', 'model.17.cv2.conv.weight']\n start_epoch: 4\n update_frequency: 1.0\n\n - !GMPruningModifier\n end_epoch: 100\n final_sparsity: 0.5\n init_sparsity: 0.05\n inter_func: cubic\n leave_enabled: True\n log_types: __ALL__\n mask_type: unstructured\n params: ['model.2.cv2.conv.weight', 'model.2.cv1.conv.weight', 'model.2.cv3.conv.weight', 'model.2.m.0.cv1.conv.weight', 'model.24.m.0.weight', 'model.24.m.1.weight', 'model.24.m.2.weight']\n start_epoch: 4\n update_frequency: 1.0\n\n - !EpochRangeModifier\n end_epoch: 240\n start_epoch: 0\n\n - !LearningRateFunctionModifier\n cycle_epochs: 1.0\n end_epoch: 240\n final_lr: 0.002\n init_lr: 0.01\n log_types: __ALL__\n lr_func: cosine\n start_epoch: 3\n update_frequency: -1.0\n", 'nc': 36, 'best_fitness': array([ 0.80556]), 'training_results': None, 'wandb_id': None}
@kuonumber thanks for checking. It's not obvious from those printouts where the size difference comes from, but it's not the training results. Can you try running the commands below to export both models to an .onnx file
python models/export.py --weights path_to_model1 --dynamic
python models/export.py --weights path_to_model2 --dynamic
Are the sizes of these files the same? If not, we'll need to compare the graphs in Netron. You can attach them here and I'll take a look.
Also, do you need your final trained and pruned model to be in .pt form or do you plan to deploy with .onnx?
Hi @kuonumber Just checking to see if you had a chance to look into this more? Thank you for letting us know! Best, Jeannie / Neural Magic
Hi @kuonumber, we've landed an upgrade of the yolov5 pathways with the 0.12 release and are not seeing any issues on the model sizes with it. Could you try and rerun in the latest version and see if it fixes your issues?
Thanks, Mark
@KSGulin Sorry for the late response. I used your code and got two same size onnx file. In my case, I need .pt format to avoid too much precision reduction. I mean if I sparse my model and then export to onnx, it seems like I lose precision twice? Am I right?
@markurtz
I upgrade to 0.12,
And try to train again
But I got
RuntimeError: All supplied parameter names or regex patterns not found.No match for model.9.cv3.conv.weight in found parameters ['model.3.conv.weight', 'model.4.m.0.cv2.conv.weight', 'model.4.m.1.cv2.conv.weight', 'model.5.conv.weight', 'model.6.m.0.cv2.conv.weight', 'model.6.m.1.cv2.conv.weight', 'model.6.m.2.cv2.conv.weight', 'model.9.cv1.conv.weight', 'model.9.cv2.conv.weight', 'model.10.conv.weight', 'model.13.cv1.conv.weight', 'model.13.cv2.conv.weight', 'model.13.cv3.conv.weight', 'model.14.conv.weight', 'model.17.cv1.conv.weight', 'model.17.cv3.conv.weight', 'model.17.m.0.cv2.conv.weight', 'model.20.cv1.conv.weight', 'model.20.m.0.cv1.conv.weight', 'model.23.cv1.conv.weight', 'model.23.m.0.cv1.conv.weight']. Supplied ['model.9.cv3.conv.weight', 'model.6.m.2.cv2.conv.weight', 'model.5.conv.weight', 'model.9.cv1.conv.weight', 'model.6.m.1.cv2.conv.weight', 'model.6.m.0.cv2.conv.weight', 'model.17.m.0.cv2.conv.weight', 'model.9.cv2.conv.weight', 'model.10.conv.weight', 'model.13.cv2.conv.weight', 'model.9.m.0.cv1.conv.weight', 'model.20.m.0.cv1.conv.weight', 'model.13.cv3.conv.weight', 'model.13.cv1.conv.weight', 'model.17.cv3.conv.weight', 'model.14.conv.weight', 'model.4.m.2.cv2.conv.weight', 'model.3.conv.weight', 'model.4.m.1.cv2.conv.weight', 'model.4.m.0.cv2.conv.weight', 'model.17.cv1.conv.weight', 'model.23.m.0.cv1.conv.weight', 'model.20.cv1.conv.weight', 'model.23.cv1.conv.weight']
@markurtz @KSGulin Hello, I used my data set for quantitative sparse transfer learning. Instead of waiting for the end of all epochs, I just trained 30 epochs and terminated it manually. But I found that the model I got was much larger than the original model. Here are my training instructions: python train.py --data ./data/data.yaml --cfg ../models_v5.0/yolov5l.yaml --weights zoo:cv/detection/yolov5-l/pytorch/ultralytics/coco/pruned_quant-aggressive_95?recipe_type=transfer --hyp data/hyps/hyp.finetune.yaml --name 0630_watermark --batch 140 --img 640 --recipe ../recipes/yolov5.transfer_learn_pruned_quantized.md The new model is 713M, compared with 353M for the original model that did not use pre-training weights. Also I would like to ask, can I use the model I trained from scratch with YoloV5 (I can't remember which branch) and specify --recipe parameter for sparse and quantization transfer learning? That is, I specify my previous model at --weights. I would appreciate your reply.
Hello, I used my data set for quantitative sparse transfer learning. Instead of waiting for the end of all epochs, I just trained 30 epochs and terminated it manually. But I found that the model I got was much larger than the original model. Here are my training instructions: python train.py --data ./data/data.yaml --cfg ../models_v5.0/yolov5l.yaml --weights zoo:cv/detection/yolov5-l/pytorch/ultralytics/coco/pruned_quant-aggressive_95?recipe_type=transfer --hyp data/hyps/hyp.finetune.yaml --name 0630_watermark --batch 140 --img 640 --recipe ../recipes/yolov5.transfer_learn_pruned_quantized.md The new model is 713M, compared with 353M for the original model that did not use pre-training weights. Also I would like to ask, can I use the model I trained from scratch with YoloV5 (I can't remember which branch) and specify --recipe parameter for sparse and quantization transfer learning? That is, I specify my previous model at --weights. I would appreciate your reply.
As a side note, I had a problem with #915 before, so my branch is now release/1.0

Closing out as this is a stale issue and the YOLOv5 integration has been heavily reworked since. If a similar issue comes up, please feel free to open a new issue.