ONNX Runtime benchmark does not obey `-ncores` when `-s async`
Describe the bug
As in the title, setting -ncores with -s async uses more cores than set with -ncores.
For example, with deepsparse.benchmark oBERT-MobileBERT_14layer_50sparse_block4_qat.onnx -e onnxruntime -ncores 8 -s async (num_streams=4), we have the following usage during the multistream benchmark usage:
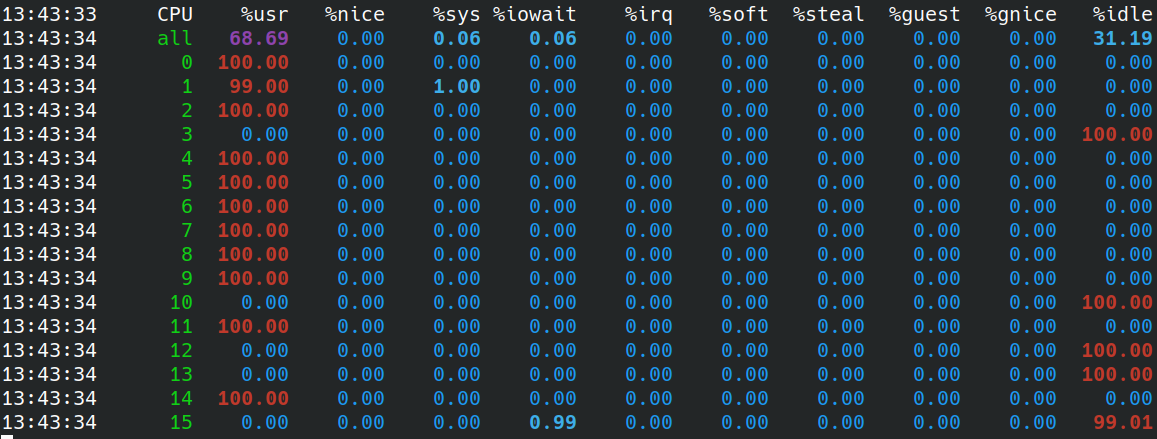
Using taskset -c 0-7 indeed pins the benchmark to the physical cores 0-7, but the throughput decreases in this case. It surprises me a bit as I would think that using more cores than the number of physical cores (=8, numbered 0-7 according to /proc/cpuinfo) would not help to speed up.
Interestingly, deepsparse.benchmark oBERT-MobileBERT_14layer_50sparse_block4_qat.onnx -e deepsparse -ncores 8 -s async uses only the CPU cores 0-7. So I think the comparison between the two backends is not 100% fair in the current state as different cores are used.
Expected behavior
We should always use the number of cores set by ncores, should we?
Environment Include all relevant environment information:
- OS: Ubuntu 22.04 LTS
- Python version: 3.9.12
- DeepSparse version or commit hash : f4e9c127ce38cc2bf59f343f6c71ad3bcaee8a31
- ML framework version(s) : onnxruntime 1.12.0
- Other Python package versions: onnx 1.12.0, numpy 1.23.1
- CPU info (AWS EC2 C6i instance):
{'L1_data_cache_size': 49152,
'L1_instruction_cache_size': 32768,
'L2_cache_size': 1310720,
'L3_cache_size': 56623104,
'architecture': 'x86_64',
'available_cores_per_socket': 8,
'available_num_cores': 8,
'available_num_hw_threads': 16,
'available_num_numa': 1,
'available_num_sockets': 1,
'available_sockets': 1,
'available_threads_per_core': 2,
'bf16': False,
'cores_per_socket': 8,
'dotprod': False,
'isa': 'avx512',
'num_cores': 8,
'num_hw_threads': 16,
'num_numa': 1,
'num_sockets': 1,
'threads_per_core': 2,
'vendor': 'GenuineIntel',
'vendor_id': 'Intel',
'vendor_model': 'Intel(R) Xeon(R) Platinum 8375C CPU @ 2.90GHz',
'vnni': True}
Hi @fxmarty, really interesting find, thanks for investigating this. Quantized MobileBERT at batch size=1 is pretty lightweight in compute so it's possible using hyperthreads might pay off in multistream benchmarking. We'll investigate this but it might be something we can control about ONNX Runtime as an external user.
Using taskset (or we use numactl -C 0-7) is your best bet for ensuring the hardware you want used will be.