nerfstudio
 nerfstudio copied to clipboard
nerfstudio copied to clipboard
nerfstudio instant ngp not working in linux environment
Describe the bug ns-train instant-ngp not working in linux environment but ns-train nerfacto is working well and there is not issue on google colab
To Reproduce Steps to reproduce the behavior:
- Go to terminal and type ns-train instant-ngp followed by your dataset path
- ns-train will start partitioning your dataset
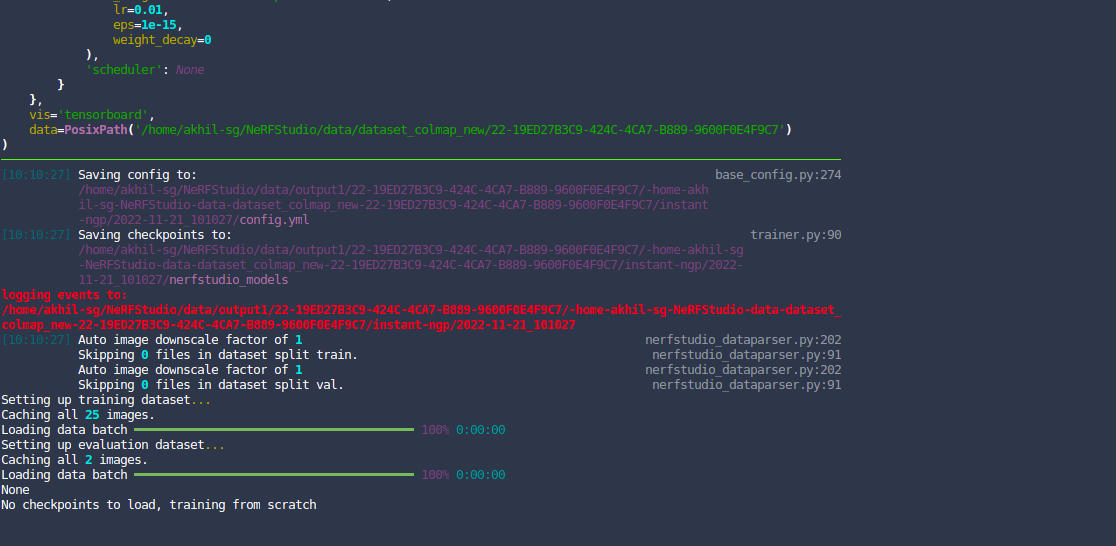
- it says "No checkpoints to load, training from scratch"
- Training won't start
Expected behavior It should start training but training is not started
Screenshots
When using instant-ngp for the first time, it will compile CUDA drivers that will take a few minutes. Try waiting a bit to see if that solves it. If not, delete the nerfacc cache and try again, for me the cache is located in ~/.cache/torch_extensions/py39_cu113/nerfacc_cuda/
well it actually works but it take 1 min to pass 10 steps
my gpu crying in the corner
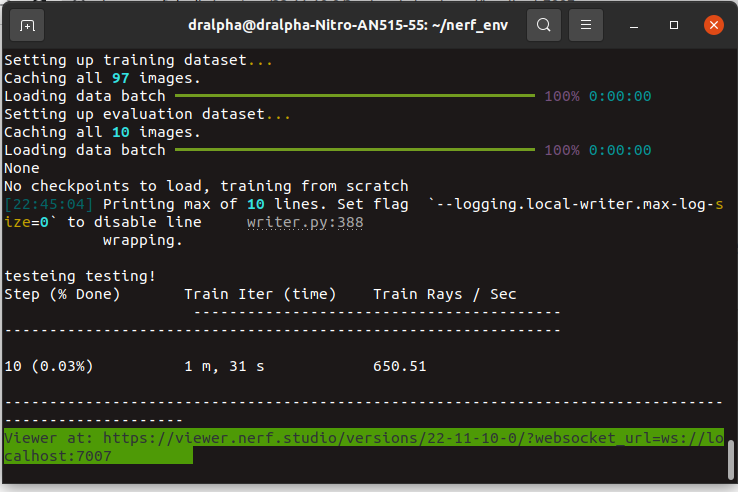
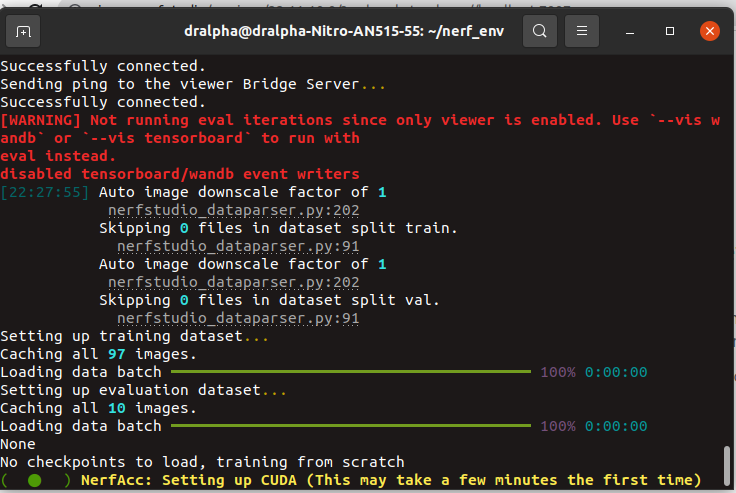
do we need spcify anything before starting the instant-ngp
my specs i5 10th gen rtx 3060 laptop gpu 16gb ram gpu driver 510 cuda 11.6
is any one got these issue while performing ns-train instant-ngp on linux environment
It seems like it is not using the GPU for some reason. The "Train Rays / Sec" should be ~1000x higher. Do the other models work fine (specifically nerfacto)?
well its using the gpu when i the gpu memory in nvidia-smi it shows the process which is using 2.8gb memory
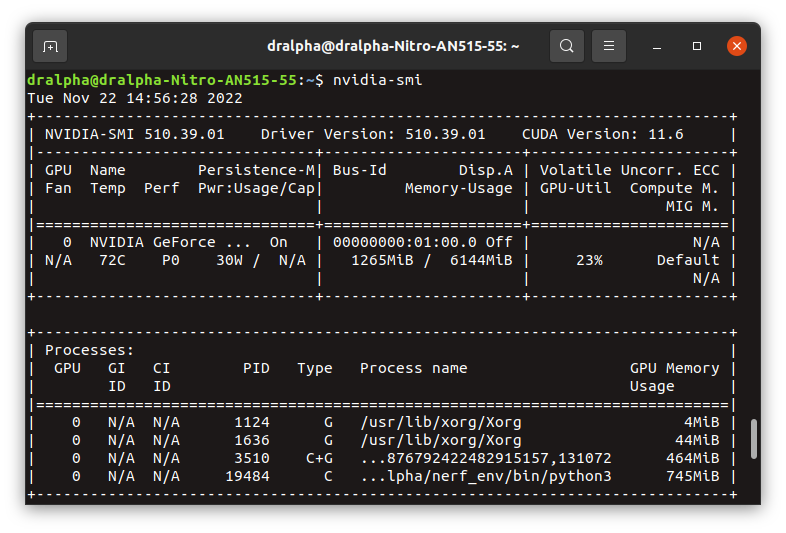
Odd. I don't have a great answer for you then. It seems like the issue may lie in nerfacc. You could take a look at the repo and associated issues to see if anyone else has had similar issues.
hmmm well it didn't work on my personal pc also in my workstation pc (which have tesla t4 graphics) that's why i posted this issue. i don't know what's happening, i post here if i found any.
Config(
output_dir=PosixPath('outputs'),
method_name='instant-ngp',
experiment_name=None,
timestamp='2022-11-27_173520',
machine=MachineConfig(seed=42, num_gpus=1, num_machines=1, machine_rank=0, dist_url='auto'),
logging=LoggingConfig(
relative_log_dir=PosixPath('.'),
steps_per_log=10,
max_buffer_size=20,
local_writer=LocalWriterConfig(
_target=<class 'nerfstudio.utils.writer.LocalWriter'>,
enable=True,
stats_to_track=(
<EventName.ITER_TRAIN_TIME: 'Train Iter (time)'>,
<EventName.TRAIN_RAYS_PER_SEC: 'Train Rays / Sec'>,
<EventName.CURR_TEST_PSNR: 'Test PSNR'>,
<EventName.VIS_RAYS_PER_SEC: 'Vis Rays / Sec'>,
<EventName.TEST_RAYS_PER_SEC: 'Test Rays / Sec'>
),
max_log_size=10
),
enable_profiler=True
),
viewer=ViewerConfig(
relative_log_filename='viewer_log_filename.txt',
start_train=True,
zmq_port=None,
launch_bridge_server=True,
websocket_port=7007,
ip_address='127.0.0.1',
num_rays_per_chunk=64000,
max_num_display_images=512,
quit_on_train_completion=False
),
trainer=TrainerConfig(
steps_per_save=500,
steps_per_eval_batch=500,
steps_per_eval_image=500,
steps_per_eval_all_images=25000,
max_num_iterations=30000,
mixed_precision=True,
relative_model_dir=PosixPath('nerfstudio_models'),
save_only_latest_checkpoint=True,
load_dir=None,
load_step=None,
load_config=None
),
pipeline=DynamicBatchPipelineConfig(
_target=<class 'nerfstudio.pipelines.dynamic_batch.DynamicBatchPipeline'>,
datamanager=VanillaDataManagerConfig(
_target=<class 'nerfstudio.data.datamanagers.base_datamanager.VanillaDataManager'>,
dataparser=NerfstudioDataParserConfig(
_target=<class 'nerfstudio.data.dataparsers.nerfstudio_dataparser.Nerfstudio'>,
data=PosixPath('data/dataset_colmap/Elephant-14-183E759FA6-739A-4425-A164-016E73469BC8'),
scale_factor=1.0,
downscale_factor=None,
scene_scale=1.0,
orientation_method='up',
center_poses=True,
auto_scale_poses=True,
train_split_percentage=0.9
),
train_num_rays_per_batch=8192,
train_num_images_to_sample_from=-1,
train_num_times_to_repeat_images=-1,
eval_num_rays_per_batch=512,
eval_num_images_to_sample_from=-1,
eval_num_times_to_repeat_images=-1,
eval_image_indices=(0,),
camera_optimizer=CameraOptimizerConfig(
_target=<class 'nerfstudio.cameras.camera_optimizers.CameraOptimizer'>,
mode='off',
position_noise_std=0.0,
orientation_noise_std=0.0,
optimizer=AdamOptimizerConfig(
_target=<class 'torch.optim.adam.Adam'>,
lr=0.0006,
eps=1e-15,
weight_decay=0
),
scheduler=SchedulerConfig(
_target=<class 'nerfstudio.engine.schedulers.ExponentialDecaySchedule'>,
lr_final=5e-06,
max_steps=10000
),
param_group='camera_opt'
)
),
model=InstantNGPModelConfig(
_target=<class 'nerfstudio.models.instant_ngp.NGPModel'>,
enable_collider=False,
collider_params=None,
loss_coefficients={'rgb_loss_coarse': 1.0, 'rgb_loss_fine': 1.0},
eval_num_rays_per_chunk=4096,
max_num_samples_per_ray=24,
grid_resolution=128,
contraction_type=<ContractionType.UN_BOUNDED_SPHERE: 2>,
cone_angle=0.004,
render_step_size=0.01,
near_plane=0.05,
far_plane=1000.0,
use_appearance_embedding=False,
randomize_background=True
),
target_num_samples=6542,
max_num_samples_per_ray=256
),
optimizers={
'fields': {
'optimizer': AdamOptimizerConfig(
_target=<class 'torch.optim.adam.Adam'>,
lr=0.01,
eps=1e-15,
weight_decay=0
),
'scheduler': None
}
},
vis='tensorboard',
data=PosixPath('data/dataset_colmap/Elephant-14-183E759FA6-739A-4425-A164-016E73469BC8')
)
────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
[17:35:20] Saving config to: base_config.py:274
outputs/data-dataset_colmap-Elephant-14-183E759FA6-739A-4425-A164-016E73469BC8/instant-ngp
/2022-11-27_173520/config.yml
[17:35:20] Saving checkpoints to: trainer.py:90
outputs/data-dataset_colmap-Elephant-14-183E759FA6-739A-4425-A164-016E73469BC8/instant-ngp/2022
-11-27_173520/nerfstudio_models
logging events to:
outputs/data-dataset_colmap-Elephant-14-183E759FA6-739A-4425-A164-016E73469BC8/instant-ngp/2022-11-27_173520
[17:35:20] Auto image downscale factor of 2 nerfstudio_dataparser.py:202
Skipping 0 files in dataset split train. nerfstudio_dataparser.py:91
Auto image downscale factor of 2 nerfstudio_dataparser.py:202
Skipping 0 files in dataset split val. nerfstudio_dataparser.py:91
Setting up training dataset...
Caching all 97 images.
Loading data batch ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 100% 0:00:00
Setting up evaluation dataset...
Caching all 10 images.
Loading data batch ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 100% 0:00:00
None
No checkpoints to load, training from scratch
[17:35:29] Printing max of 10 lines. Set flag --logging.local-writer.max-log-size=0 to disable line writer.py:388
wrapping.
testeing testing!
Step (% Done) Train Iter (time) Train Rays / Sec
400 (1.33%) 14.701 ms 586.61 K
410 (1.37%) 13.495 ms 613.83 K
420 (1.40%) 13.495 ms 613.52 K
430 (1.43%) 13.473 ms 614.59 K
440 (1.47%) 13.467 ms 614.85 K
450 (1.50%) 13.835 ms 602.76 K
460 (1.53%) 13.519 ms 612.68 K
470 (1.57%) 13.490 ms 613.93 K
480 (1.60%) 13.888 ms 600.57 K
490 (1.63%) 13.683 ms 605.08 K
Printing profiling stats, from longest to shortest duration in seconds
Trainer.train_iteration: 0.0272
VanillaPipeline.get_train_loss_dict: 0.0236
VanillaPipeline.get_eval_loss_dict: 0.0229
Trainer.eval_iteration: 0.0000
Traceback (most recent call last):
File "/home/dralpha/nerf_env/bin/ns-train", line 8, in
import torch torch.backends.cuda.matmul.allow_tf32 = False torch.backends.cudnn.benchmark = True torch.backends.cudnn.deterministic = False torch.backends.cudnn.allow_tf32 = True data = torch.randn([1, 3, 720, 960], dtype=torch.float, device='cuda', requires_grad=True) net = torch.nn.Conv2d(3, 64, kernel_size=[11, 11], padding=[2, 2], stride=[4, 4], dilation=[1, 1], groups=1) net = net.cuda().float() out = net(data) out.backward(torch.randn_like(out)) torch.cuda.synchronize()
ConvolutionParams memory_format = Contiguous data_type = CUDNN_DATA_FLOAT padding = [2, 2, 0] stride = [4, 4, 0] dilation = [1, 1, 0] groups = 1 deterministic = false allow_tf32 = true input: TensorDescriptor 0x7af61c00 type = CUDNN_DATA_FLOAT nbDims = 4 dimA = 1, 3, 720, 960, strideA = 2073600, 691200, 960, 1, output: TensorDescriptor 0x7ad470c0 type = CUDNN_DATA_FLOAT nbDims = 4 dimA = 1, 64, 179, 239, strideA = 2737984, 42781, 239, 1, weight: FilterDescriptor 0x83239b50 type = CUDNN_DATA_FLOAT tensor_format = CUDNN_TENSOR_NCHW nbDims = 4 dimA = 64, 3, 11, 11, Pointer addresses: input: 0x7fc6bf7bb000 output: 0x7fc690000000 weight: 0x7fc71520f400
well nerfstudio instant-ngp actually works and training started and when it tries to save the ckpt at a particular step it shows out of memory is there any way to reduce the batch size
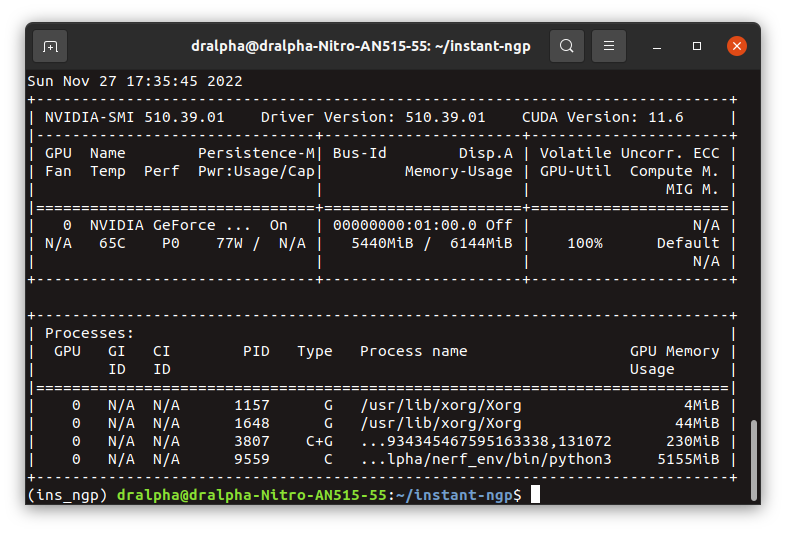
its using 5.2 Gb out of 6 is there any way to reduce the memory size
RuntimeError: CUDA out of memory. Tried to allocate 840.00 MiB (GPU 0; 5.81 GiB total capacity; 2.06 GiB already allocated; 746.25 MiB free; 3.36 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF