blogs
 blogs copied to clipboard
blogs copied to clipboard
Event loop 机制简介
堆、栈、队列
堆
-
堆通常是一个可以被看做一棵树的数组对象。堆总是满足下列性质:
- 堆中某个节点的值总是不大于或不小于其父节点的值;
- 堆总是一棵完全二叉树。将根节点最大的堆叫做最大堆或大根堆,根节点最小的堆叫做最小堆或小根堆。常见的堆有二叉堆、斐波那契堆等。
-
堆是在程序运行时,而不是在程序编译时,申请某个大小的内存空间。即动态分配内存,对其访问和对一般内存的访问没有区别。
-
堆是应用程序在运行的时候请求操作系统分配给自己内存,一般是申请/给予的过程。
-
堆是指程序运行时申请的动态内存,而栈只是指一种使用堆的方法(即先进后出)。
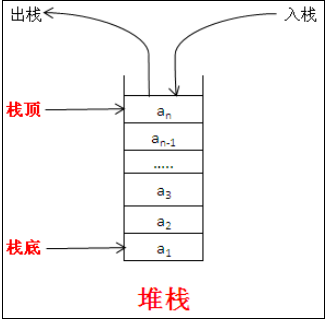
栈
- 栈(stack)又名堆栈,一个数据集合,可以理解为只能在一端进行插入或删除操作的列表。其限制是仅允许在表的一端进行插入和删除运算。这一端被称为栈顶,相对地,把另一端称为栈底。
- 栈就是一个桶,后放进去的先拿出来,它下面本来有的东西要等它出来之后才能出来(先进后出),对应js数组操作里的
push(入栈)和pop(出栈) - 栈(Stack)是操作系统在建立某个进程时或者线程(在支持多线程的操作系统中是线程)为这个线程建立的存储区域,该区域具有FIFO的特性,在编译的时候可以指定需要的Stack的大小。
队列
是一种支持先进先出(FIFO)的集合,即先被插入的数据,先被取出!

执行栈
当javascript代码执行的时候会将不同的变量存于内存中的不同位置:堆(heap)和栈(stack)中来加以区分。其中,堆里存放着一些对象。而栈中则存放着一些基础类型变量以及对象的指针。 但是我们这里说的执行栈和上面这个栈的意义却有些不同。
js 在执行可执行的脚本时,首先会创建一个全局可执行上下文globalContext,每当执行到一个函数调用时都会创建一个可执行上下文(execution context)EC。当然可执行程序可能会存在很多函数调用,那么就会创建很多EC,所以 JavaScript 引擎创建了执行上下文栈(Execution context stack,ECS)来管理执行上下文。当函数调用完成,js会退出这个执行环境并把这个执行环境销毁,回到上一个方法的执行环境... 这个过程反复进行,直到执行栈中的代码全部执行完毕:
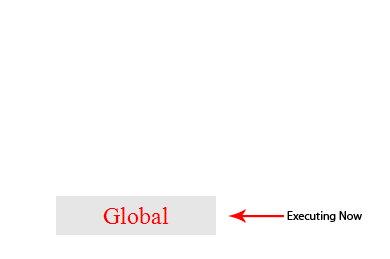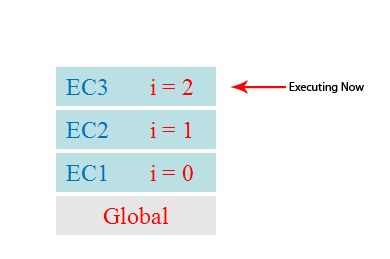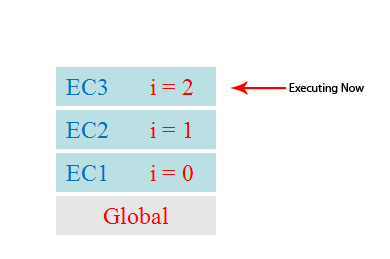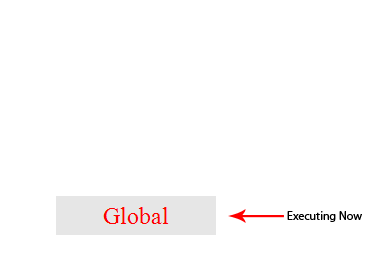
下面来看个简单的例子:
function fun3() {
console.log('fun3')
}
function fun2() {
fun3();
}
function fun1() {
fun2();
}
fun1();
当执行一个函数的时候,就会创建一个执行上下文,并且压入执行上下文栈,当函数执行完毕的时候,就会将函数的执行上下文从栈中弹出。知道了这样的工作原理,让我们来看看如何处理上面这段代码:
1.执行全局代码,创建全局执行上下文,全局上下文被压入执行上下文栈
ECStack = [
globalContext
];
2.全局上下文初始化
globalContext = {
VO: [global],
Scope: [globalContext.VO],
this: globalContext.VO
}
3.初始化的同时,fun1 函数被创建,保存作用域链到函数的内部属性[[scope]]
fun1.[[scope]] = [
globalContext.VO
];
4.执行 fun1 函数,创建 fun1 函数执行上下文,fun1 函数执行上下文被压入执行上下文栈
ECStack = [
fun1,
globalContext
];
5.fun1函数执行上下文初始化:
- 复制函数 [[scope]] 属性创建作用域链,
- 用 arguments 创建活动对象,
- 初始化活动对象,即加入形参、函数声明、变量声明,
- 将活动对象压入
fun1作用域链顶端。 同时 f 函数被创建,保存作用域链到 f 函数的内部属性[[scope]]
checkscopeContext = {
AO: {
arguments: {
length: 0
},
scope: undefined,
f: reference to function f(){}
},
Scope: [AO, globalContext.VO],
this: undefined
}
- 执行
fun2()函数,重复步骤2。 - 最终形成这样的执行栈:
ECStack = [
fun3
fun2,
fun1,
globalContext
];
8.fun3执行完毕,从执行栈中弹出...一直到fun1
事件队列
以上的过程说的都是同步代码的执行。那么当一个异步代码(如发送ajax请求数据)执行后会如何呢?接下来需要了解的另一个概念就是:事件队列(Task Queue)。 当js引擎遇到一个异步事件后,其实不会说一直等到异步事件的返回,而是先将异步事件进行挂起。等到异步事件执行完毕后,会被加入到事件队列中。(注意,此时只是异步事件执行完成,其中的回调函数并没有去执行。)当执行队列执行完毕,主线程处于闲置状态时,会去异步队列那抽取最先被推入队列中的异步事件,放入执行栈中,执行其中的回调同步代码。如此反复,这样就形成了一个无限的循环。这就是这个过程被称为“事件循环(Event Loop)”的原因。 为了更好的理解,我们来看一张图:(转引自Philip Roberts的演讲《Help, I'm stuck in an event-loop》)
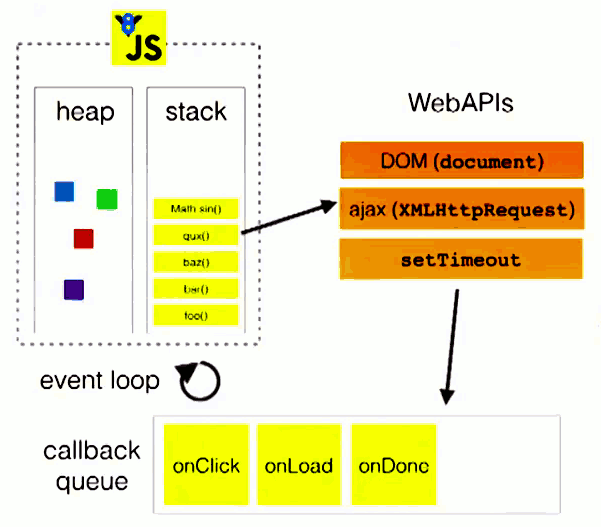
主线程运行的时候,产生堆(heap)和栈(stack),栈中的代码调用各种外部API,它们在"任务队列"中加入各种事件(click,load,done)。只要栈中的代码执行完毕,主线程就会去读取"任务队列",依次执行那些事件所对应的回调函数。
macro task与micro task
在介绍之前,我们先看一段经典的代码执行:
setTimeout(function () {
console.log(1);
});
new Promise(function(resolve,reject){
console.log(2)
resolve(3)
}).then(function(val){
console.log(val);
})
会看到控制台先后分别输出:2、3、1。 先看一下阮老师对setTimeout的一些解释:
setTimeout(fn,0)的含义是,指定某个任务在主线程最早可得的空闲时间执行,也就是说,尽可能早得执行。它在"任务队列"的尾部添加一个事件,因此要等到同步任务和"任务队列"现有的事件都处理完,才会得到执行。需要注意的是,setTimeout()只是将事件插入了"任务队列",必须等到当前代码(执行栈)执行完,主线程才会去执行它指定的回调函数。要是当前代码耗时很长,有可能要等很久,所以并没有办法保证,回调函数一定会在setTimeout()指定的时间执行。 实际上,一般因为异步任务之间并不相同,因此他们的执行优先级也有区别。不同的异步任务被分为两类:微任务(micro task)和宏任务(macro task)。
以下事件属于宏任务:
- setTimeout
- MessageChannel
- postMessage
- setImmediate
以下事件属于微任务
- new Promise()
- new MutaionObserver()
前面我们介绍过,在一个事件循环中,异步事件返回结果后会被放到一个任务队列中。然而,根据这个异步事件的类型,这个事件实际上会被对应的宏任务队列或者微任务队列中去。并且在当前执行栈为空的时候,主线程会 查看微任务队列是否有事件存在。如果不存在,那么再去宏任务队列中取出一个事件并把对应的回到加入当前执行栈;如果存在,则会依次执行队列中事件对应的回调,直到微任务队列为空,然后去宏任务队列中取出最前面的一个事件,把对应的回调加入当前执行栈...如此反复,进入循环。
我们只需记住当当前执行栈执行完毕时会立刻先处理所有微任务队列中的事件,然后再去宏任务队列中取出一个事件。同一次事件循环中,微任务永远在宏任务之前执行。 所以我们就很好解释上面的那段代码了。
参考资料
详解JavaScript中的Event Loop(事件循环)机制
JavaScript 运行机制详解:再谈Event Loop
嗯 windows编程和qt也是采用的单ui线程和消息循环来处理前端 。js算是从语言层面实现了单线程加消息循环。前辈们好聪明啊,如果前端是多线程的,估计程序员要疯了吧,哈哈