BUG with chatbot-ui: model does not exist
llama: model does not exist gpt: model does not exist gpt2: model does not exist stableLM: model does not exist
The UI interface cannot be used, and the page cannot select a local model. I am using 'ggml gpt4all j' locally


I think it is due to the following configuration not being added in the image. https://github.com/mckaywrigley/chatbot-ui/blob/main/types/openai.ts
Here: export const fallbackModelID = OpenAIModelID.GPT_3_5;
Maybe it's another problem

This is the file I referenced and build in MacOS: https://github.com/go-skynet/LocalAI/tree/master/examples/chatbot-ui
@chenbt-hz can you share your chatbot-ui docker file ? or how your UI is interacting with APIs ? would like to review that
After I pulled the latest version and modified the configuration as follows, the error prompt on the web no longer appears, but new errors still appear。
examples/chatbot-ui/docker-compose.yaml: `version: '3.6'
services: api: image: quay.io/go-skynet/local-ai:latest build: context: ../../ dockerfile: Dockerfile.dev ports: - 8080:8080 environment: - DEBUG=true - MODELS_PATH=/models volumes: - ./models:/models:cached command: ["/usr/bin/local-ai" ]
chatgpt:
image: ghcr.io/mckaywrigley/chatbot-ui:main
ports:
- 3000:3000
environment:
- 'OPENAI_API_KEY=sk-XXXXXXXXXXXXXXXXXXXX'
- 'OPENAI_API_HOST=http://
examples/chatbot-ui/models/gpt-3.5-turbo.yaml: `name: gpt-3.5-turbo parameters: model: ggml-gpt4all-j top_k: 80 temperature: 0.2 top_p: 0.7 context_size: 1024 threads: 4 backend: gptj stopwords:
- "HUMAN:"
- "GPT:"
- "### Response:" roles: user: "HUMAN:" system: "GPT:" template: completion: completion chat: ggml-gpt4all-j`
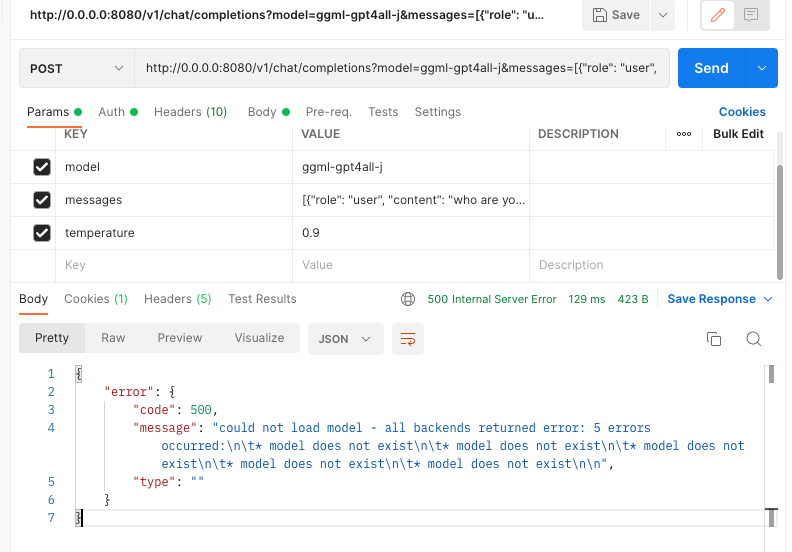
I tried to start the model in Docker, but got the problem that computation crashing when asked. Eventually, I used a local build and successfully started the service `./local-ai --models-path ./models/ --debug Starting LocalAI using 4 threads, with models path: ./models/
┌───────────────────────────────────────────────────┐ │ Fiber v2.44.0 │ │ http://127.0.0.1:8080 │ │ (bound on host 0.0.0.0 and port 8080) │ │ │ │ Handlers ............ 12 Processes ........... 1 │ │ Prefork ....... Disabled PID ............. 72719 │ └───────────────────────────────────────────────────┘
11:35AM DBG Request received: {"model":"","prompt":null,"instruction":"","input":"","stop":null,"messages":null,"stream":false,"echo":false,"top_p":0,"top_k":0,"temperature":0,"max_tokens":0,"n":0,"batch":0,"f16":false,"ignore_eos":false,"repeat_penalty":0,"n_keep":0,"seed":0}
11:35AM DBG No model specified, using: ggml-gpt4all-j
11:35AM DBG Parameter Config: &{OpenAIRequest:{Model:ggml-gpt4all-j Prompt:
Prompt:
Response:
`