GraphQL 中 resolver 的两种写法
GraphQL 中 resolver 的两种写法
基础知识略过,直接进入正题,下面要介绍的resolver的两种写法直接关系到性能问题。
先来看下示例的GraphQL SDL的ERD:
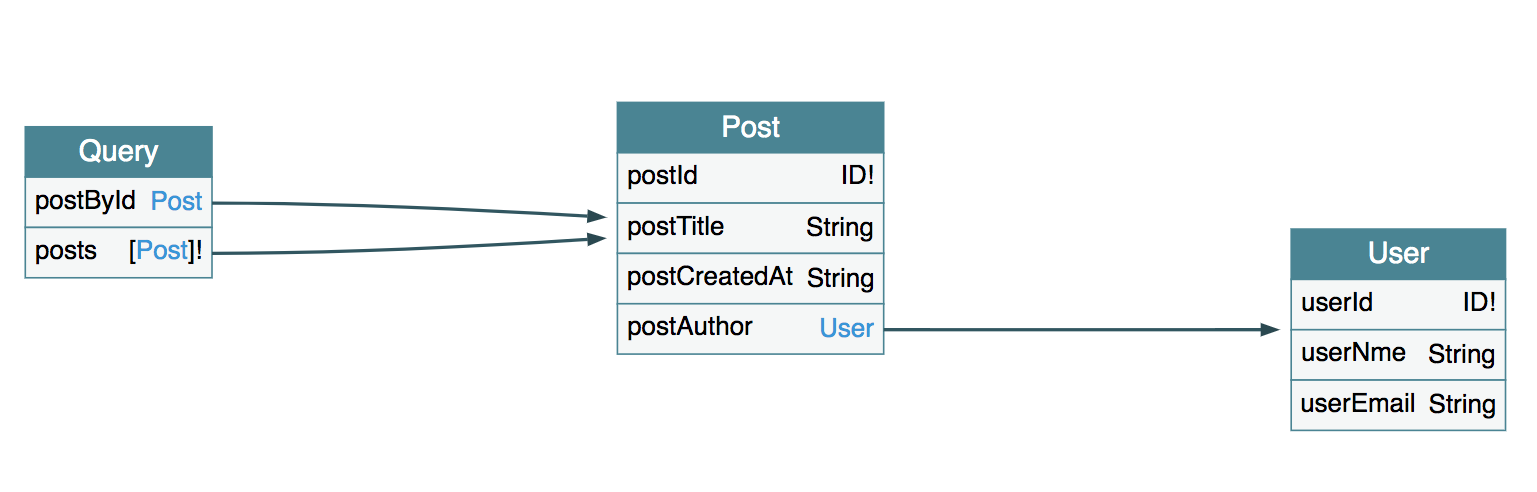
很常见的数据关系模型,User和Post是一对多的关系,数据库表ERD如下:

GraphQL SDL如下:
type User {
userId: ID!
userNme: String
userEmail: String
}
type Post {
postId: ID!
postTitle: String
postCreatedAt: String
postAuthor: User
}
type Query {
postById(id: ID!): Post
posts: [Post]!
}
示例使用memoryDB内存数据库模拟RDBMS:
import faker from 'faker';
const userPK1 = '1';
const userPK2 = '2';
const memoryDB = {
users: [
{ userId: userPK1, userNme: faker.name.findName(), userEmail: faker.internet.email() },
{ userId: userPK2, userNme: faker.name.findName(), userEmail: faker.internet.email() },
],
posts: [
{
postId: '1',
postTitle: faker.lorem.sentence(),
postCreatedAt: new Date().toUTCString(),
postAuthorId: userPK1,
},
{
postId: '2',
postTitle: faker.lorem.sentence(),
postCreatedAt: new Date().toUTCString(),
postAuthorId: userPK1,
},
],
};
export { memoryDB };
接下来编写resolver,有两种写法,我们来对比和分析一下。
在一个resolver中解析所有SDL定义的字段
resolver如下:
import { IResolvers } from 'graphql-tools';
const resolvers: IResolvers = {
Query: {
async postById(_, { id }, { memoryDB }) {
const postFound = memoryDB.posts.find((post) => post.postId === id);
if (postFound) {
const postAuthor = memoryDB.users.find((user) => user.userId === postFound.postAuthorId);
postFound.postAuthor = postAuthor;
}
console.log(`postFound: ${JSON.stringify(postFound)}`);
return postFound;
},
async posts(_, __, { memoryDB }) {
return memoryDB.posts.map((post) => {
post.postAuthor = memoryDB.users.find((user) => user.userId === post.postAuthorId);
return post;
});
},
},
};
export { resolvers };
可以看到,postById这个resolver在数据库中根据id去posts表中查询post,查询出post后,还根据post实体上的postAuthorId这个外键去users表中查询相应的user。同理,posts这个resolver查询出所有的post实体后,遍历所有post实体,根据postAuthorId外键去users表中查询每个post实体对应的user。
接下来我们在GraphQL Playground中编写GraphQL客户端查询
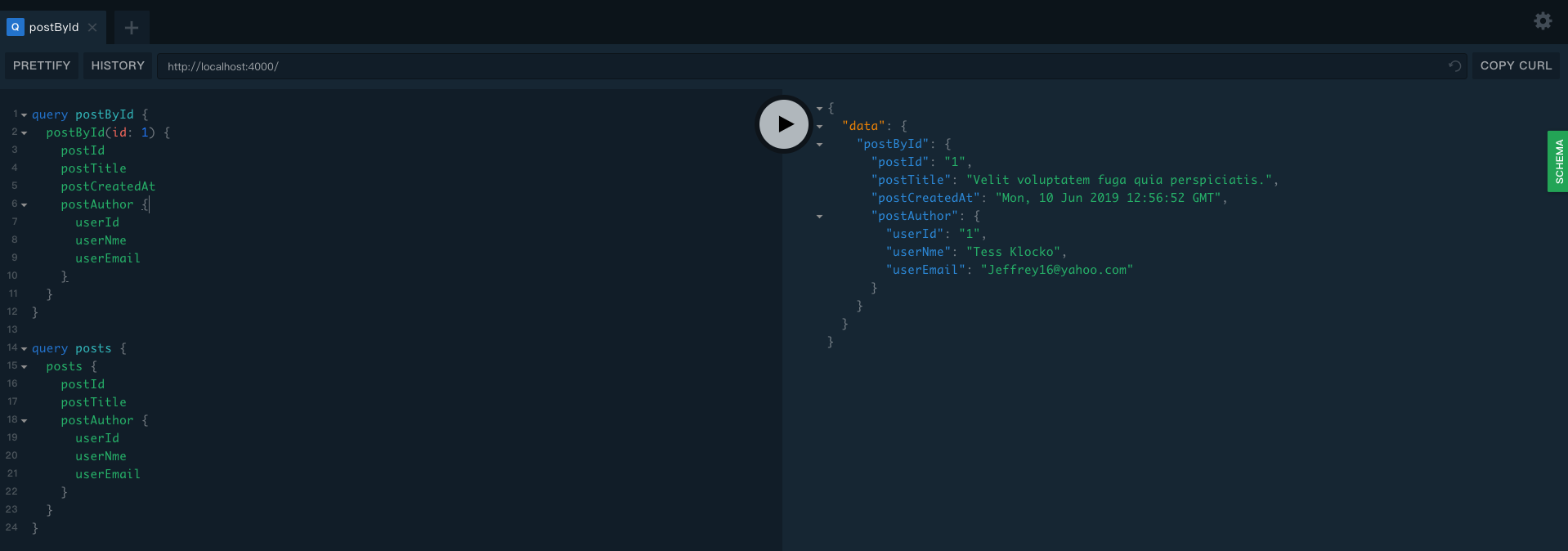
postById这个query查询了Post这个Object type上的所有字段,客户端取得正常返回结果。

删除postAuthor这个查询字段,客户端也取得正常返回结果。
从客户端的角度来看,上述两次查询都取得了正常结果,然而,上述这样编写resolver,会让服务端多出很多不必要的字段解析,甚至严重影响应用程序性能。我们继续看第二次查询,客户端并没有查询postAuthor这个字段,但是postById这个resolver却依旧去数据库中查询了user作为postAuthor,这浪费了一次查询,占用了一个连接池资源。可以试想,如果postAuthor是通过Http请求去某个远程服务器上获取的,这一次http请求也是一次无意义的性能损耗。
同理,客户端查询posts,但如果不查询postAuthor,然而服务端的resolver却给每一个post去查询相应的postAuthor,这就是很多次的无意义的查询。所以下面介绍官方正确的resolver写法:
正确的resolver写法
import { IResolvers } from 'graphql-tools';
const resolversBetter: IResolvers = {
Query: {
async postById(_, { id }, { memoryDB }) {
return memoryDB.posts.find((post) => post.postId === id);
},
async posts(_, __, { memoryDB }) {
return memoryDB.posts;
},
},
Post: {
async postAuthor(source, _, { memoryDB }) {
console.count('resolve Post.postAuthor');
return memoryDB.users.find((user) => user.userId === source.postAuthorId);
},
},
};
export { resolversBetter };
再次执行之前的两次客户端查询postById,客户端不查询postAuthor,那么postById这个resolver只进行了一次数据库查询,根据id去posts表中查询相应的post。
客户端查询postAuthor,此时,服务端的Post.postAuthor这个resolver才会执行,从而去users表中查询相应的user作为postAuthor。下图是客户端查询postAuthor的返回结果:

服务端Post.postAuthor这个resolver执行后打印出的console.count日志如下:
resolve Post.postAuthor: 1
这个问题想出来的比较早,有兴趣的可以看看原始提问:
https://stackoverflow.com/questions/52272727/resolve-all-fields-in-one-resolver-v-s-resolve-field-in-each-resolver
使用一年多下来,有时候觉得GraphQL并不严谨,很多问题官方没有解释的很清楚,比如SDL中定义循环引用的问题:
https://stackoverflow.com/questions/53863934/is-graphql-schema-circular-reference-an-anti-pattern。
以及SDL如何设计,Object Type嵌套层级深度,客户端查询字段如何映射到SQL查询column(SQL语句中查询的column和客户端查询的字段一一对应,不多查column)的问题。此外还需要解决N+1 query,缓存问题。
apollographql的一些GraphQL模块实现也还处于起步阶段,apollographql的服务端上传模块apollo-upload-server和客户端上传模块apollo-upload-client相比于multer和jQuery-File-Upload,弱太多了,只能满足最基本的上传需求,所以如果对上传功能要求比较高的话,建议使用现有更成熟的方案。对于apollographql升级到2.0以后,使用的dataSource,目前官方也只给出了HTTP通信的dataSource实现apollo-datasource-rest,SQL和NoSQL的dataSource实现社区里都是一些个人零零散散的实现,对于新手来说,基本等于没有。
如果你使用TypeScript, Node.js, GraphQL作为技术栈,推荐一个库: https://typegraphql.ml/, 能减少很多冗余代码。
源码
https://github.com/mrdulin/apollo-graphql-tutorial/tree/master/src/resolve-fields-in-one-resolver
大佬,不知道现在apollographql里SQL的dataSource实现怎么样了呀?看官方文档感觉不敢在项目里用,现在只是简单的在每个resolver里面查SQL,感觉和普通的 restful api没区别呀
@MBearo 社区现有的DB Datasource: https://www.apollographql.com/docs/apollo-server/data/data-sources/#community-data-sources
根据自己项目用到的db driver,不论是原始的db driver,比如node-postgres,还是knex.js这样的query builder, 还是sequelize, typeorm这样的orm,自己撸一个。
看一下源码:https://github.com/cvburgess/SQLDataSource/blob/master/index.js
几个重要的点:
- 默认使用InMemoryLRUCache缓存,对于多个应用实例的集群,或是分布式应用,你需要应用程序外部共享缓存系统,请使用Using Memcached/Redis as a cache storage backend
- https://github.com/cvburgess/SQLDataSource/blob/master/index.js#L28 这一行为knex扩展了一个
.cache( ttl )方法,当需要为当前的db操作开启缓存功能时,手动调用该方法。为什么手动调用?因为不是所有数据都需要缓存。
请记住,缓存最适用于相对静态的数据或经常读取的数据
- 缓存更新策略,从这行开始看 https://github.com/cvburgess/SQLDataSource/blob/master/index.js#L50
- 先从缓存中查数据,缓存命中,返回数据
- 缓存未命中,从db中查,此处的
query是knex.js的链式调用的返回结果,比如this.knex.select("*").from("fruit").where({ id: 1 }),是个promise,查到后将数据塞入缓存,设置ttl,返回数据
关于缓存模式的更多信息,看微软的这个技术架构指南cache-aside
-
initialize方法是给apollo server内部调用的,一般不需要手动调用,你需要实现它,每个请求都会调用该方法,你可以从context拿到当前请求的上下文信息。 -
实现好
SQLDatasource基类以后,就可以创建业务层的Datasource了,可以看用法,继承SQLDatasource基类,业务层的Datasource实现具体的业务数据访问方法,例如findById(),UpdateById等,最后在初始化apollo server时,初始化这些业务层Datasource。
@MBearo 社区现有的DB Datasource: https://www.apollographql.com/docs/apollo-server/data/data-sources/#community-data-sources
根据自己项目用到的db driver,不论是原始的db driver,比如node-postgres,还是knex.js这样的query builder, 还是sequelize, typeorm这样的orm,自己撸一个。
看一下源码:https://github.com/cvburgess/SQLDataSource/blob/master/index.js
几个重要的点:
- 默认使用InMemoryLRUCache缓存,对于多个应用实例的集群,或是分布式应用,你需要应用程序外部共享缓存系统,请使用Using Memcached/Redis as a cache storage backend
- https://github.com/cvburgess/SQLDataSource/blob/master/index.js#L28 这一行为knex扩展了一个
.cache( ttl )方法,当需要为当前的db操作开启缓存功能时,手动调用该方法。为什么手动调用?因为不是所有数据都需要缓存。请记住,缓存最适用于相对静态的数据或经常读取的数据
缓存更新策略,从这行开始看 https://github.com/cvburgess/SQLDataSource/blob/master/index.js#L50
- 先从缓存中查数据,缓存命中,返回数据
- 缓存未命中,从db中查,此处的
query是knex.js的链式调用的返回结果,比如this.knex.select("*").from("fruit").where({ id: 1 }),是个promise,查到后将数据塞入缓存,设置ttl,返回数据关于缓存模式的更多信息,看微软的这个技术架构指南cache-aside
initialize方法是给apollo server内部调用的,一般不需要手动调用,你需要实现它,每个请求都会调用该方法,你可以从context拿到当前请求的上下文信息。- 实现好
SQLDatasource基类以后,就可以创建业务层的Datasource了,可以看用法,继承SQLDatasource基类,业务层的Datasource实现具体的业务数据访问方法,例如findById(),UpdateById等,最后在初始化apollo server时,初始化这些业务层Datasource。
跪谢大佬,容我慢慢研究研究,感谢!!!