BUG: Ray remote tasks internally blocking on object IDs of their dependencies can lead to deadlock
System information
- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): macOS Monterey
- Modin version (
modin.__version__): I ran into this issue in my branch https://github.com/mvashishtha/modin/tree/4493-use-width-and-length-caches, which is a fix for #4493. I think my branch is correct, but I haven't taken the time to reproduce this issue on Modin master yet. - Python version: 3.9.12
- Code we can use to reproduce:
import numpy as np
import modin.pandas as pd
from decimal import Decimal
height = 50_000
width = 751
im = pd.DataFrame(np.random.randint(0, 2, size=(height, width)))
im = im.applymap(lambda x: Decimal(str(x)))
weight_vec = pd.Series(np.random.rand(height)).apply(lambda x: Decimal(str(x)))
print(im.T.multiply(weight_vec))
Describe the problem
I get really good parallel execution for a few seconds, then I get almost no utilization. ray status says there are hundreds of pending tasks but 0/55 cpus are used:
Show `ray status`
======== Autoscaler status: 2022-05-27 16:22:19.115055 ========
Node status
---------------------------------------------------------------
Healthy:
1 node_2a3ebe64b733f71c652c9900fc7c796e8757bb3756253fa2ae824b92
Pending:
(no pending nodes)
Recent failures:
(no failures)
Resources
---------------------------------------------------------------
Usage:
0.0/16.0 CPU
0.00/9.313 GiB memory
0.64/9.313 GiB object_store_memory
Demands:
{'CPU': 1.0}: 197+ pending tasks/actors
I also get a bunch of warning messages like (scheduler +9m23s) Warning: The following resource request cannot be scheduled right now: {'CPU': 1.0}. This is likely due to all cluster resources being claimed by actors. Consider creating fewer actors or adding more nodes to this Ray cluster.
Source code / logs
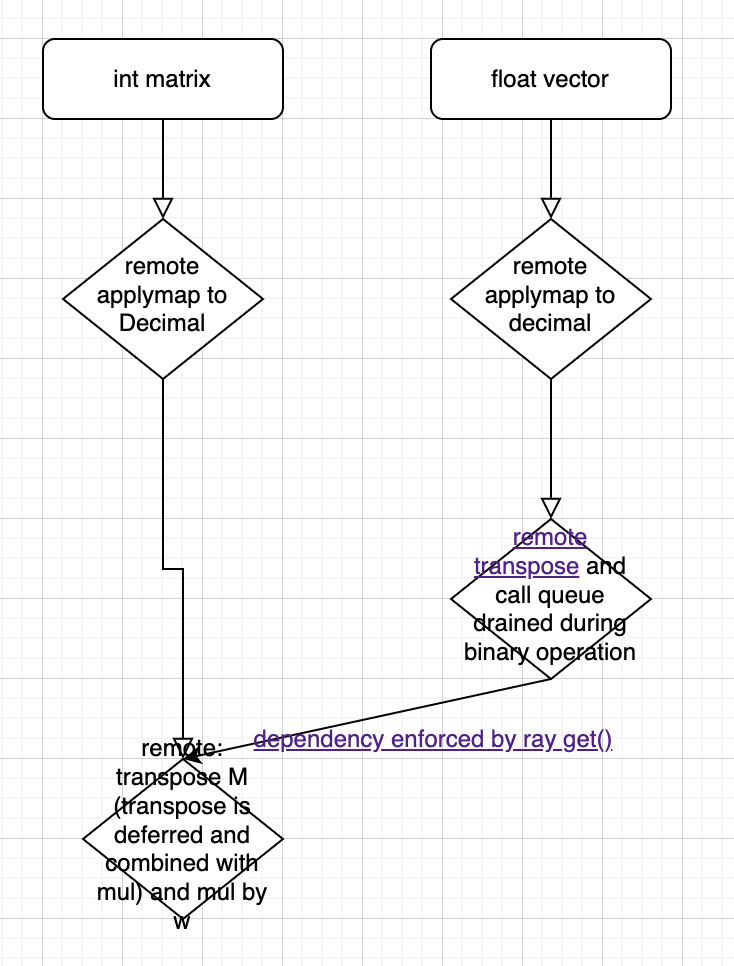
This diagram shows the dependencies among the groups of ray tasks. The tasks doing the transpose and multiply block on getting the partition IDs of the Decimal weights. (The partition IDs are passed in broadcast_apply here).
I found with some logging that ray is scheduling the final transpose+multiply tasks while the series transpose tasks are still running. the final tasks depend on the transpose task indirectly via an object ID that we pass into the remote function within a list. ray doesn't know about that dependency, so it schedules the transpose+multiply tasks before the transpose tasks even start running. We then get deadlock while the transpose+multiply tasks wait for the transpose tasks, but the transpose tasks need to wait for the transpose+multiply tasks so they can access ray CPUs. In my case there are 16 times as many transpose+multiply tasks as series transpose tasks, and at the time all of these are getting scheduled, the applymaps are hogging all the cPUs. so some of the time (in my experience roughly 50%), at least one of those transpose+multiply tasks is blocked on a series transpose that will never happen.
Solution
One solution is to pass object IDs directly to ray remote functions instead of passing a list holding an object ID. That way the ray scheduler can schedule the tasks taking into account their indirect dependencies. I implemented that fix here and it worked.
The reproducer in the issue seem to work fine on the current master (at least, on my machine). However, I stumbled into another example that still triggers the same problem:
import numpy as np
import modin.pandas as pd
NROWS, NCOLS = (1_371_980, 300)
df = pd.DataFrame({f"col{i}": np.random.randint(0, 1_000_000, NROWS) for i in range(NCOLS)})
df = df + 10
cols = df.columns[1:].tolist()
res = df[cols] / df[cols].mean()
print(res._to_pandas())
# autoscaler +1m42s) Tip: use `ray status` to view detailed cluster status. To disable these messages, set RAY_SCHEDULER_EVENTS=0.
# (autoscaler +1m42s) Warning: The following resource request cannot be scheduled right now: {'CPU': 1.0}. This is likely due
# to all cluster resources being claimed by actors. Consider creating fewer actors or adding more nodes to this Ray cluster.
I tried to fix the problem in #6633, and it works now