18.06.1: starting container failed: failed to get network during CreateEndpoint: network not found
I'm experiencing a problem on 18.06.1 similar to #2015, some services recently began to fail occasionally upon redeploy with:
starting container failed: failed to get network during CreateEndpoint: network sa8m3w8pqi0tqzro06naftwbu not found
This is docker log from one of the affected worker node, the 4th line looks weird, as it indicates some network removal operations that should not happen:
time="2019-02-22T18:50:12.298220240+08:00" level=info msg="NetworkDB stats worker-04(03ad71380621) - netID:sa8m3w8pqi0tqzro06naftwbu leaving:false netPeers:6 entries:77 Queue qLen:0 netMsg/s:0"
time="2019-02-22T18:55:12.498417669+08:00" level=info msg="NetworkDB stats worker-04(03ad71380621) - netID:sa8m3w8pqi0tqzro06naftwbu leaving:false netPeers:6 entries:61 Queue qLen:0 netMsg/s:0"
time="2019-02-22T18:57:15.646497195+08:00" level=warning msg="Error (Unable to complete atomic operation, key modified) deleting object [endpoint sa8m3w8pqi0tqzro06naftwbu 400a306d13ff57f7c0b773f692fb4c1399500c821a9fd2f7b7172fcbbebb903d], retrying...."
time="2019-02-22T18:57:15.728256035+08:00" level=error msg="network xxx_default remove failed: unknown network xxx_default id sa8m3w8pqi0tqzro06naftwbu" module=node/agent node.id=xpoaymvry45sb5q888o1jpoi8
time="2019-02-22T18:57:15.728298569+08:00" level=error msg="remove task failed" error="unknown network xxx_default id sa8m3w8pqi0tqzro06naftwbu" module=node/agent node.id=xpoaymvry45sb5q888o1jpoi8 task.id=5mav3lpsdc7gk8hpwgnyvtbr4
time="2019-02-22T18:57:15.768893162+08:00" level=error msg="fatal task error" error="starting container failed: failed to get network during CreateEndpoint: network sa8m3w8pqi0tqzro06naftwbu not found" module=node/agent/taskmanager node.id=xpoaymvry45sb5q888o1jpoi8 service.id=2x43w0s1gvxkzu4b8qw4wk3y2 task.id=kdyljmb8isyp02cqaq5dqsdnu
time="2019-02-22T18:57:16.045314219+08:00" level=error msg="fatal task error" error="starting container failed: failed to get network during CreateEndpoint: network sa8m3w8pqi0tqzro06naftwbu not found" module=node/agent/taskmanager node.id=xpoaymvry45sb5q888o1jpoi8 service.id=vdputsk4p8vf6a3klda75od44 task.id=j3l9cc5job0ih3g7eokgp73mk
time="2019-02-22T18:57:18.861072689+08:00" level=warning msg="Error (Unable to complete atomic operation, key modified) deleting object [endpoint sa8m3w8pqi0tqzro06naftwbu 1c327c91e28c1024b23384b52d16861b8593c002c0312975d4ebac6e5953a962], retrying...."
time="2019-02-22T18:57:40.752379324+08:00" level=warning msg="deleteServiceInfoFromCluster NetworkDB DeleteEntry failed for 655f0010bee9de626f131bfbc629da4d0b79c84227709ac924921c8e7b900c58 sa8m3w8pqi0tqzro06naftwbu err:cannot delete entry endpoint_table with network id sa8m3w8pqi0tqzro06naftwbu and key 655f0010bee9de626f131bfbc629da4d0b79c84227709ac924921c8e7b900c58 does not exist or is already being deleted"
time="2019-02-22T19:00:12.699101399+08:00" level=info msg="NetworkDB stats worker-04(03ad71380621) - netID:sa8m3w8pqi0tqzro06naftwbu leaving:false netPeers:6 entries:64 Queue qLen:0 netMsg/s:0"
My workaround: polling service status during update, if this specific error is detected, deploy affected services again
Others: https://github.com/moby/libnetwork/issues/2341#issuecomment-674424639 https://github.com/moby/libnetwork/issues/2341#issuecomment-674429287
I'm seeing this as well. It's causing us some very significant issues, unfortunately
I am observing the same log, Docker version:
Client:
Version: 18.09.4
API version: 1.39
Go version: go1.10.8
Git commit: d14af54266
Built: Wed Mar 27 18:34:51 2019
OS/Arch: linux/amd64
Experimental: false
Server: Docker Engine - Community
Engine:
Version: 18.09.3
API version: 1.39 (minimum version 1.12)
Go version: go1.10.8
Git commit: 774a1f4
Built: Thu Feb 28 06:02:24 2019
OS/Arch: linux/amd64
Experimental: true
Hello, I experience the same kind of issue, did you guys found what was the reason?
Im experiencing the same error message: "failed to get network during CreateEndpoint: network not found", while there is the network in the network ls list...
Right now i have a swarm cluster with 24 nodes and every day i have the same problem in 2 or 3 nodes, we need to run 3 or 4 times some tasks until get a good reply

Hello I have a similar problem, I raised this stack and monitored it for more than 5 hours, randomly I get the network problem, I've tried everything up to the problem version since 18, I'm currently running version 19!
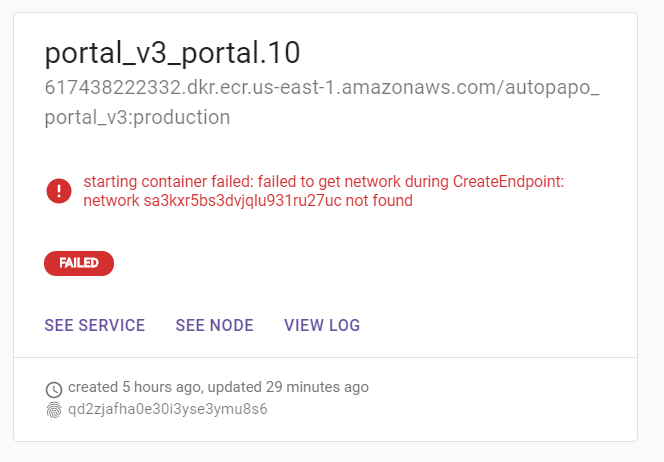
Same Problem:
"failed to get network during CreateEndpoint: network not found",
level=error msg="fatal task error" error="No such container: name.1.35t4bbzy272u3xkpxl8296l2p" module=node/agent/taskmanager node.id=43hjp8zr23r2vlenim4yq3pwy service.id=fg880y07vahuofyifq2bnw1cs task.id=35t4bbzy272u3xkpxl8296l2p
level=error msg="fatal task error" error="No such container: name.jsndjsjdnakjsda" module=node/agent/taskmanager node.id=43hjp8zr23r2vlenim4yq3pwy service.id=i3r7633tvotrjp805jzhks0v0 task.id=tvtp62n1s4kybvy834mlnrako
Error (Unable to complete atomic operation, key modified) deleting object [endpoint sa8m3w8pqi0tqzro06naftwbu 1c327c91e28c1024b23384b52d16861b8593c002c0312975d4ebac6e5953a962], retrying...."
level=warning msg="deleteServiceInfoFromCluster NetworkDB DeleteEntry failed for .... sa8m3w8pqi0tqzro06naftwbu err:cannot delete entry endpoint_table with network id sa8m3w8pqi0tqzro06naftwbu and key 655f0010bee9de626f131bfbc629da4d0b79c84227709ac924921c8e7b900c58 does not exist or is already being deleted"
time="2019-02-22T19:00:12.699101399+08:00" level=info msg="NetworkDB stats worker-04(03ad71380621) - netID:sa8m3w8pqi0tqzro06naftwbu leaving:false netPeers:6 entries:64 Queue qLen:0 netMsg/s:0"
After a Docker restart this pops into my face:
level=error msg="network agent-net remove failed: error while removing network: unknown network
and
level=debug msg="Request address PoolID:10.0.0.0/24 App: ipam/default/data, ID: GlobalDefault/10.0.0.0/24, DBIndex: 0x0, Bits: 256, Unselected: 230, Sequence: (0xffffff80, 1)->(0x0, 6)->(0x1, 1)->end Curr:25 Serial:true PrefAddress:<nil> "
The Unselected part goes to zero. than everything is repeating itself.
Docker-CE 19.03.8 standard installation
i am facing the same issue, it looks like something has changed in the last versions Docker version 19.03.8-ce, build afacb8b7f0
Hi,
Until now there is no fix for that, even with the latest version. We have a large container implementation and sometimes we got this problem, in that case:
- We redeploy the service, but before we prune the cluster, after that the containers works fine
- We create a bash which calls the container and implements a pause(sleep) to run a command after load (or download) the image
I'm using a DockerPy, did the same thing as @alfonsodg, basically it throws an exception whenever this error occurs and what I do is to catch at and try to launch the containers after 5 seconds. It's working for now! I also switched to 19.03.12 but it didn't solve the issue. If it helps I got to say that I get this issue with only 3 containers.
On my side, the problematic machine has two NICs, ens3 for external IP and ens4 for talking to the swarm manager.
By forcing the docker to use the ens4 for communication solves the problem:
docker swarm join --advertise-addr ens4 --listen-addr ens4 --data-path-addr ens4 --token *** <manager_addr>
I guess docker swarm does not look into the route table but just picks the interface with a smaller id.