Early Stopping implementation might have a bug
Early Stopping implemented in LoadGen seems to have a bug: overlatency count collapses to 1 as the total query count increases. It is likely that a very fast accelerator can go way more than min_query_count for meeting the min_duration and for any reason EarlyStopping may come in handy.
Also it's worth double checking why the above behavior happens, and see if currently used counts (meaningful counts > 1) are solid.
I have ported the C++ code to Python as in attached zip file earlystop.zip (please run it like python earlystop.py) to demonstrate what's going on. Hope this helps identifying the issue.
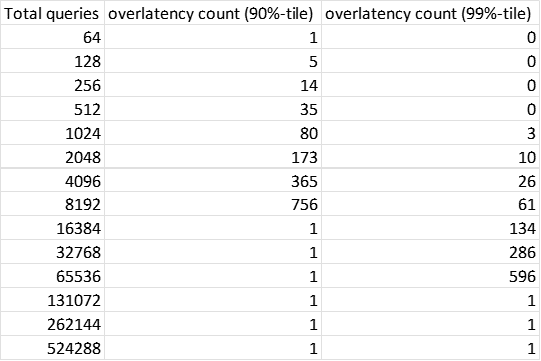
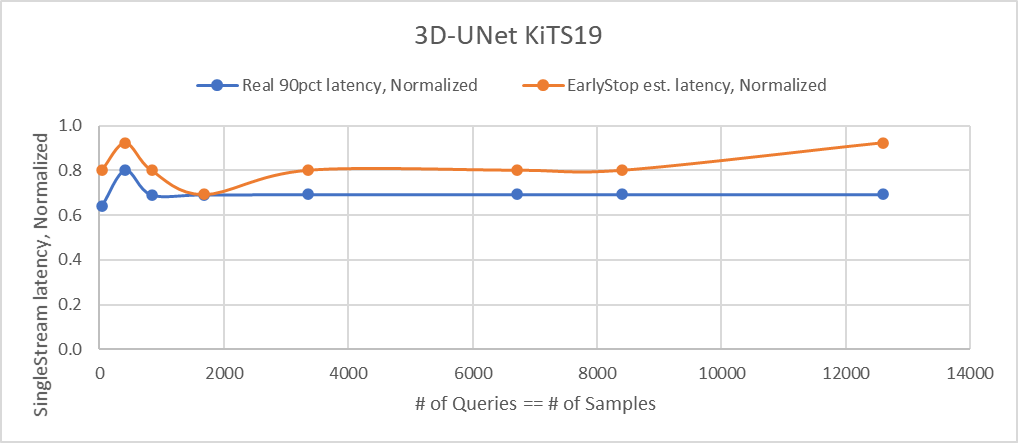
Hi @nv-jinhosuh . Thanks for catching this. It turns out that the fix is simple... there's no complicated overflowing issue going on. There's currently an overlatency query bound that's set to (1 << 10). So when the overlatency count gets beyond 1024, the early stopping loop terminates early and we have the bug.
There's no need for this overlatency bound, and removing it seems to resolve the issue. So I'll put in a PR to fix this.
@ckstanton Does this look like a manifestation of the same bug to you?
================================================
MLPerf Results Summary
================================================
SUT name : ArmNN_TFLite_SUT
Scenario : SingleStream
Mode : PerformanceOnly
90th percentile latency (ns) : 15443391
Result is : VALID
Min duration satisfied : Yes
Min queries satisfied : Yes
Early stopping satisfied: Yes
Early Stopping Result:
* Processed at least 64 queries (45317).
* Would discard 0 highest latency queries.
* Early stopping 90th percentile estimate: 41232125
* Early stopping 99th percentile estimate: 22679287
================================================
Additional Stats
================================================
QPS w/ loadgen overhead : 75.53
QPS w/o loadgen overhead : 75.59
Min latency (ns) : 9204559
Max latency (ns) : 41232125
Mean latency (ns) : 13228655
50.00 percentile latency (ns) : 14008000
90.00 percentile latency (ns) : 15443391
95.00 percentile latency (ns) : 16327907
97.00 percentile latency (ns) : 17329774
99.00 percentile latency (ns) : 22200163
99.90 percentile latency (ns) : 27176409
A question to the WG. We have already collected lots of results like above, which would be rather onerous to rerun before the submission deadline. I'm wondering if we can submit them as they are, and rerun during the review period.
That looks like the same bug to me.
On Tue, Feb 8, 2022, 6:43 PM Anton Lokhmotov @.***> wrote:
A question to the WG. We have already collected lots of results like above, which would be rather onerous to rerun before the submission deadline. I'm wondering if we can submit them as they are, and rerun during the review period.
— Reply to this email directly, view it on GitHub https://github.com/mlcommons/inference/issues/1083#issuecomment-1033286617, or unsubscribe https://github.com/notifications/unsubscribe-auth/ABA5I6XTKOSS5BSKCU6ATDTU2HIGTANCNFSM5N3NJX6Q . Triage notifications on the go with GitHub Mobile for iOS https://apps.apple.com/app/apple-store/id1477376905?ct=notification-email&mt=8&pt=524675 or Android https://play.google.com/store/apps/details?id=com.github.android&referrer=utm_campaign%3Dnotification-email%26utm_medium%3Demail%26utm_source%3Dgithub.
You are receiving this because you are subscribed to this thread.Message ID: @.***>
That looks like the same bug to me.
Agreed. There should be on the order of ~4500 acceptable overlatency queries for this run, which is bigger than the threshold of 1024 where we're seeing the issue.
@psyhtest BTW, since the log shows the test met the min_query/min_duration criteria, I don't think there's any need for you to use early stopping estimate. So I believe, regardless of the bug being manifested, you can submit the results using the normal measurement (just avoid using early stopping estimate). Maybe need a word in WG for confirming this.
@nv-jinhosuh That's my feeling too. But IIRC we decided that the early estimate would be used as the metric regardless. And it is what the submission checker appears to do. Right, @ckstanton @pgmpablo157321?
@nv-jinhosuh That's my feeling too. But IIRC we decided that the early estimate would be used as the metric regardless. And it is what the submission checker appears to do. Right, @ckstanton @pgmpablo157321?
Correct... the early stopping estimate is used as the metric, regardless of how many queries are processed