vscode-jupyter
 vscode-jupyter copied to clipboard
vscode-jupyter copied to clipboard
Connect to existing Local Kernel
FYI - This feature is for the scratch path.
Connecting to exiting live remote kernels is simple:
- When we detect remote kernels we create a controller for that live remote kernel
- Then we select that
remote kernel controllerin a notebook/IW
For local kernels, we have no such concept - we must create a controller that points to the live local kernel. Suggestions
- Option 1: When we start a kernel, we could then create a controller that points to this active kernel (similar to live remote kernels)
- Option 2: When starting a scratch pad, we can first create the controller and then attach the controller to the notebook
Notes:
- How can user start a notebook that points to the same local live kernel?
- We need option 1 for this.
- How can user start an IW that points to the same local live kernel?
- We need option 1 for this.
- What is the life time of this controller?
- Rmemeber - this is a local live kernel.
- If all notebooks/IW that connect to this controller are closed, then kill off the kernel (as is done today) & delete this controller.
- However if the kernel was originally started by a 3rd party exetnsion then don't do anything (in that case the lifetime of the kernel/controller is managed by the 3rd party extension).
- If the kernel dies (3rd party closes this or we kill it), then remove the controller from the list (e.g. if user kills the kernel from kernel management UI).
- Do we have multiple IKernel instances?
- No, we'll have just the one IKernel instance.
- Where do we list these live local kernels
- Just as with live remote kernels, we'll have a separate section for live local kernels.
- Interrupts/restarts/cell execution all share the same kernel
- Thus if we restart the kernel in scratch pad, that will restart the kernel in the other notebook/iw (where the kernel was originally started)
- Similarly execution in scratch pad will end up getting queued along with the other cells. I.e. if we have a few cells running in the original notebook, and we create a scratch pad, and run cells in this scratch pad, they will end up getting queued in the same queue (after all its the same kernel).
Thoughts:
- Go with option 2, if and when users ask for option 1, we can add support for that
- Even with Option 2, we still need to create an controller and display it in the list (meaning we still need an entry under
Live Local Kernels), which is the same as Option 1. However this controller is created only when creating a scratch pad (we'll expose a simple API or simple command to make this possible in Jupyter ext).
Outcome:
- When connecting to a local kernel add an entry for the live local kernel in kernel list (for insiders)
- If we connect to a live local kernel and the original notebook/iw is closed, then kill off the corresponding kernel
- If users complain we can change this later
For now, enable this feature only in the pre-release (insider version).
Hi @DonJayamanne what is the status on integrating this into the stable vscode version? This is a must have!
@Trezorro please could you provide an example of your use case, thanks
I use this all the time in Atom's Hydrogen, and now that Atom is breaking in more places it would be nice to have this support in vscode.
My use case is mostly in having an interactive and persistent Jupyter session while developing data-intensive libraries. Say I have a package split into multiple files:
# a.py
import pandas as pd
def create_dataframe():
return pd.DataFrame({'a': [1, 2, 3]})
# b.py
from a import create_dataframe
def use_dataframe()
df = create_dataframe()
# use df
Say that I'm editing b.py but realize that I need to modify the behavior of create_dataframe in a.py. Without being able to share one Jupyter kernel across both files, I need to restart the kernel that b.py is using so that I can get the updated create_dataframe definition. But when both files are able to share the same Jupyter kernel, I can re-evaluate create_dataframe and use that function without needing to restart the kernel that b.py is using. Avoiding a restart of the kernel is very useful when the steps to re-create the data in memory take a long time.
Here's a recorded example of how my desired behavior works in Hydrogen
https://user-images.githubusercontent.com/15164633/204104970-2c27a3f6-0187-4b44-9cc5-3319056e8f0b.mov
- First I create a new Jupyter kernel in
a.pyand execute its code - Then I attach to the same kernel in
b.py, runcreate_dataframeand check that its output is expected - Then I realize I need to change
create_dataframeina.py. I can make a change tocreate_dataframe, re-execute that function definition, and then call it inb.pywithout restarting the kernel.
This works because create_dataframe is defined in the running kernel as <function __main__.create_dataframe()>. But if this code is loaded as a library, it will still work because of from a import create_dataframe.
I use the ipynb for presentation (cells with few lines of code and explanation around them) and py code with all complexities (making widgets, generating data, plots, etc) is separate. I work mostly within VSCode and use Jupyter rarely... I usually work on code and presentation/notebook in parallel going back and forth. I will nibble at the code and add a cell that captures the gist. Vice versa, I can prototype within the notebook and then move it to the code. Either way having a connection between IW and the notebook is a boon. In my current workflow, I run a remote (mostly localhost) Jupyter outside of VSCode and then connect the notebook and the IW to this remote. It works fine but needless to say having to run Jupyter outside, get the URL, paste in VSCode, etc is a nuisance... Sometimes I start with the IW and then connect the notebook to it (IW shows as default.ipynb notebook). Sometimes the other way around.
It seems natural to provide the same functionality within VSCode (perhaps as a new type of remote: a local virtual kernel)
It would be great if we could have this feature in vs code, for DS this is a must have feature.
@Shayan-B Please do upvote this issue, thats how we prioritize issues.
This is a critical feature for using notebooks. I basically can't use VS Code notebooks without having a connected terminal to prototype code. Having the interactive terminal connected to a .py file is nice, but most of my work is in notebooks, and having to constantly export from .ipynb to .py (and the reverse) is just too much friction, so I just end up launching Jupyter Lab and skipping VS Code.
so I just end up launching Jupyter Lab and skipping VS Code.
Thanks but how do you achieve this feature request today in Jupyter lab?
but most of my work is in notebooks, and having to constantly export from .ipynb to .py (and the reverse) is just too much friction
looks like you need a separate feature This issues don’t seem to fulfill your requirements above You seem to want to just switch between ipynb and py files , but there’s no mention of sharing the same kernel session Also I am not sure how you can achieve that in Jupyter lab (you’ve indicated that you can do that)
Thanks for the quick response and the clarifying questions. In Jupyter Lab you right-click the active notebook of interest and select "New Console for Notebook". And that's it. The attached gif gets at the functionality.
@wetlandscapes this is the main feature I am missing since I switched from jupyterlab to vscode
Thanks for the quick response and the clarifying questions. In Jupyter Lab you right-click the active notebook of interest and select "New Console for Notebook". And that's it. The attached gif gets at the functionality.

Similarly, in jupyter-notebook, you can use THIS extension.
Here you just use ctrl-b to open an interactive scratchpad.
Major missing this feature.
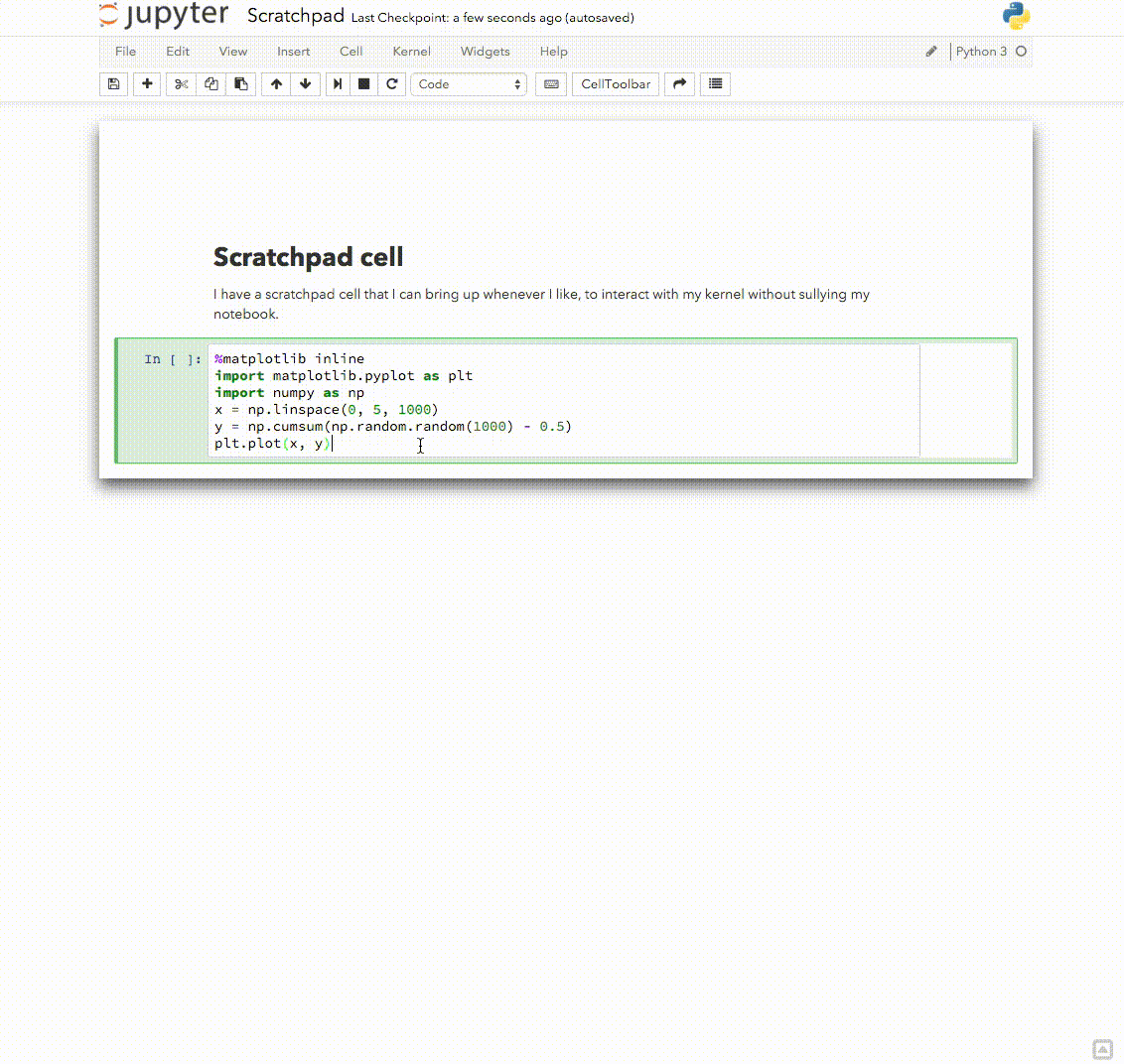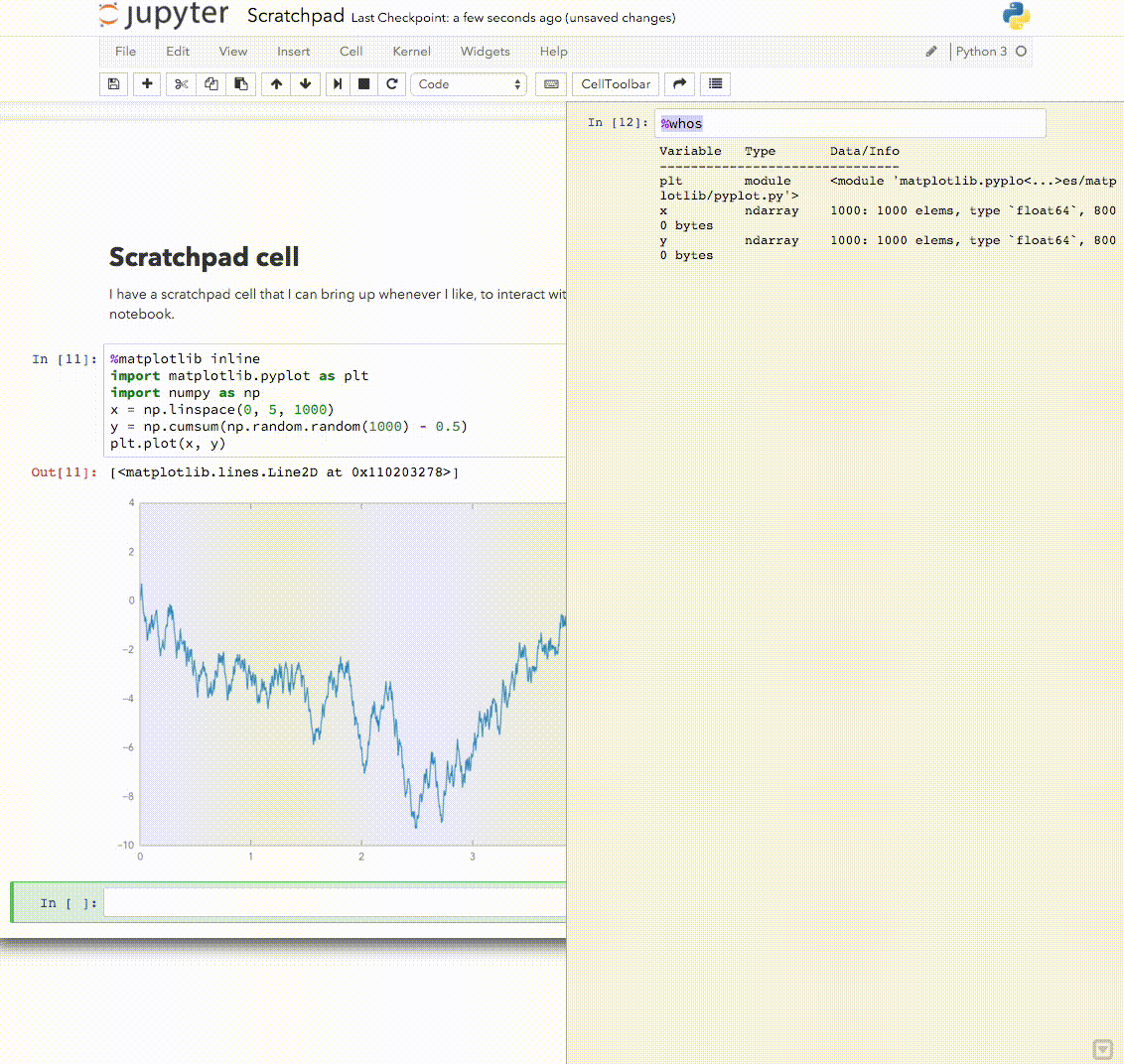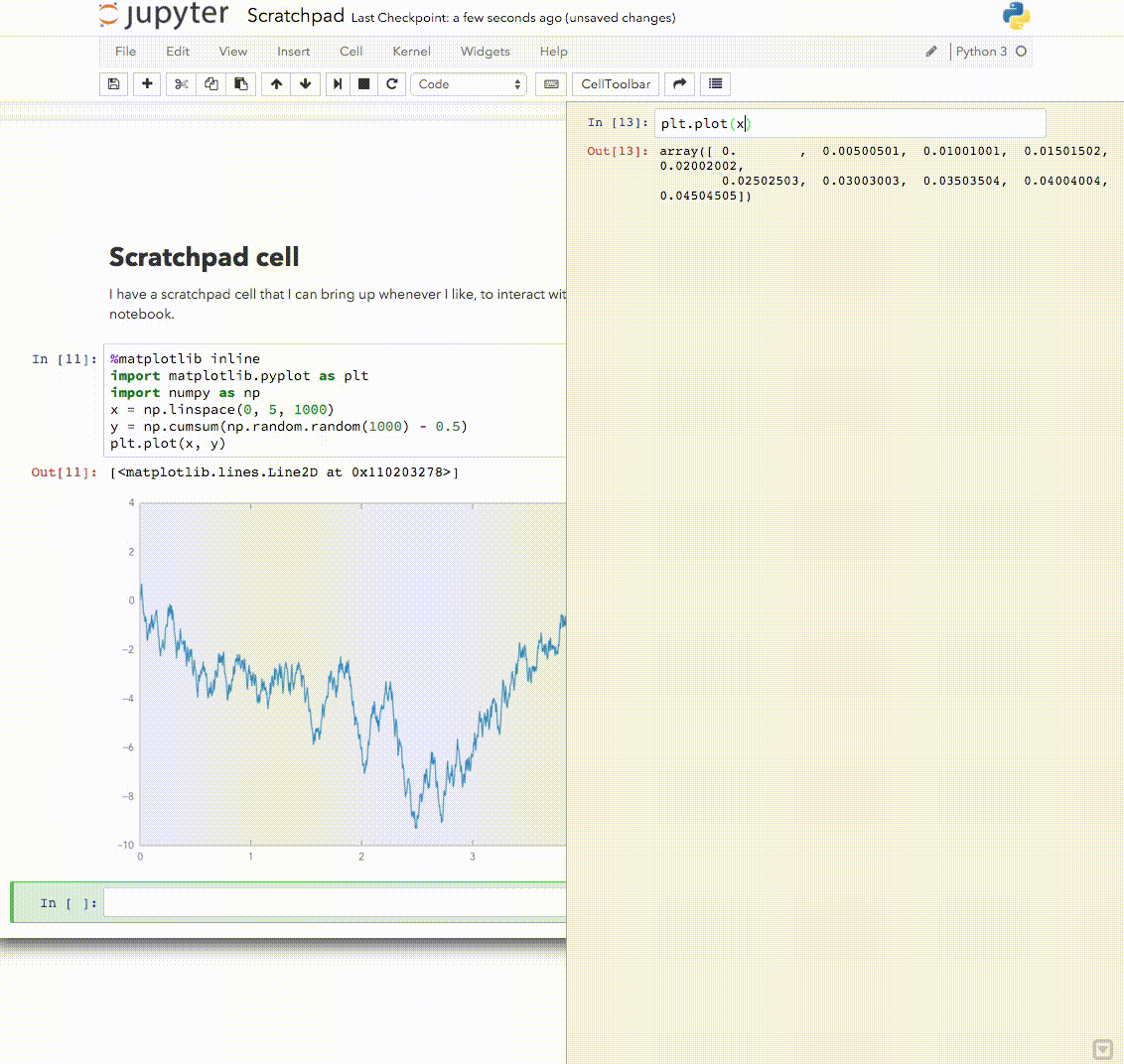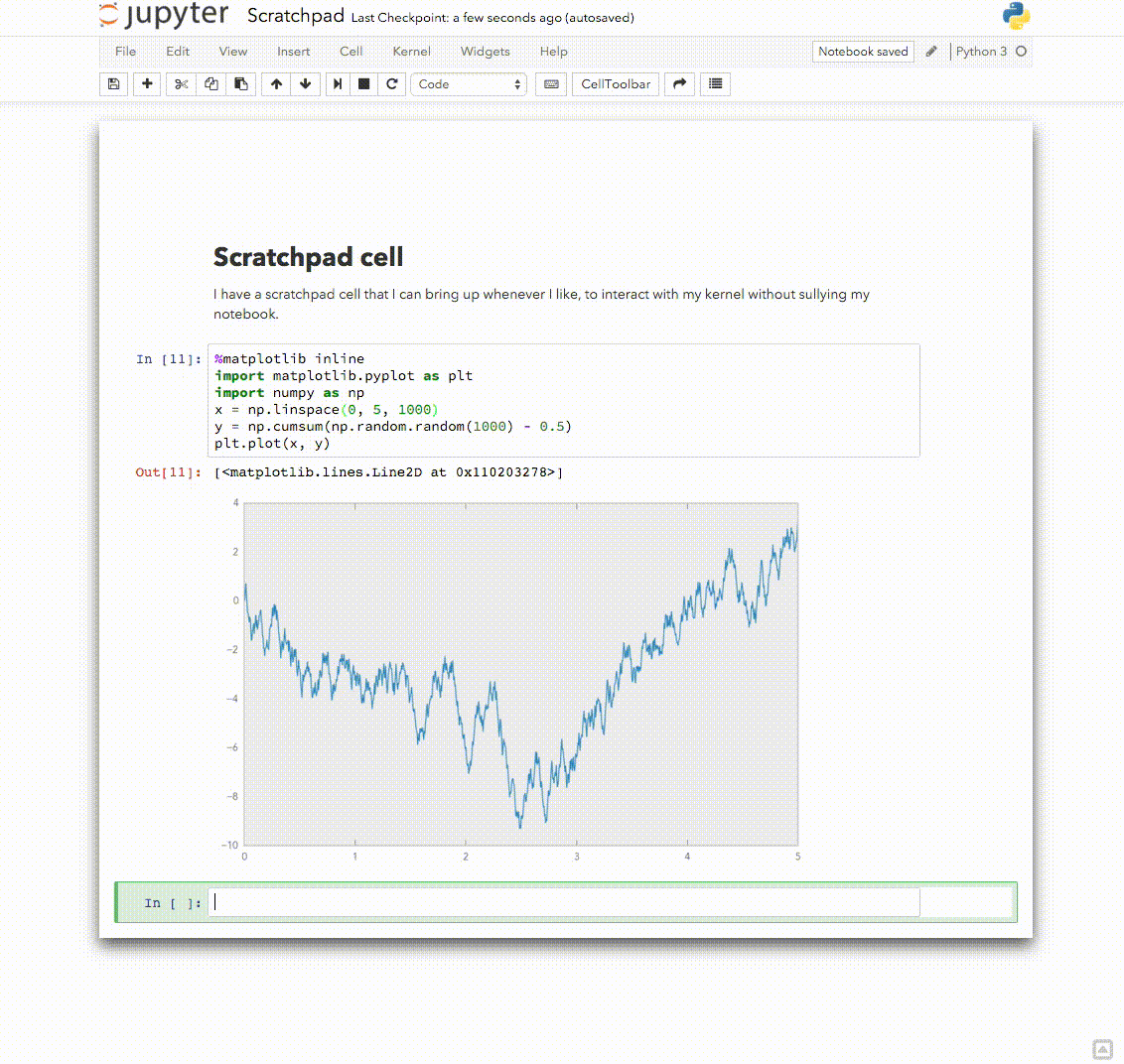
Here is a version of this one I like Explore using the interactive window as a console for notebook kernels
<3 I know many users at my work who refuse to switch from Spyder because this feature is missing.