Loading high frequency data is too slow.
I am going to use qlib for intraday
I updated 1min data in real time to reflect the stock market. And I tried to load last 10 minutes data using following codes.
df = D.features(D.instruments('csi300'), ['$open', '$high', '$low', '$close', '$factor'], start_time='2020-09-14 09:30:00', end_time='2021-09-14 09:40:00', freq="1min")
I expect it will take less than 0.5s but it takes above 30s It is much slower than traditional database. What did I do wrong?
I try your code and it takes less the 0.5s, there should be something wrong. Just try to set dataset_cache=None when you init qlib? Also can you show me your all code?
I got same result when I try to set dataset_cache=None in the init step. I use following codes to test it.
class MyTestCase(unittest.TestCase):
def setUp(self):
provider_uri = "~/.qlib/qlib_data/cn_data_1min" # target_dir
qlib.init(provider_uri=provider_uri, region=REG_CN, dataset_cache=None)
def test_dataset(self):
start = time.time()
df = D.features(D.instruments('csi300'), ['$open', '$high', '$low', '$close', '$factor'], start_time='2020-09-14 09:30:00',
end_time='2021-09-14 09:40:00', freq="1min")
print(time.time()-start)
How about set expression_cache=None also? And what configuration (memory, CPU) are you running the code on?
I alos got same result with "expression_cache=None" I execute profilling tool with above codes and got following results.
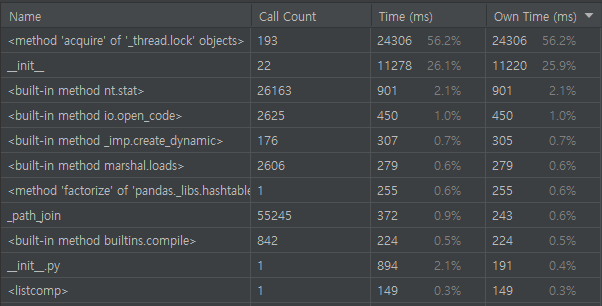
My system infomation is as follows.
CPU: AMD Ryzen 9 3900X 12-Core Processor 3.80 GHz RAM: 64.0GB OS: Windows 10 64bit pro
You can try to run it in linux. For high frequency related code, I think it may be better to run it in linux.
OK. I will try it. And would you explain more detail about it? I wonder why linux is better than window for high frequency related code. I noticed thread lock takes so much time in the profiling result. Is it related with windows os?
Sorry, I don't know much about the process management mechanism of windows, but I guess there may be several reasons for this:
- The efficiency of windows IPC (interprocess communication) may be low, which makes the transmission of high-frequency data between parent and child processes take more time
- Windows process switching may be slower
There may be more possibilities, but they can all be verified by some methods. If you have any opinions, please share them with me.
This issue is stale because it has been open for three months with no activity. Remove the stale label or comment on the issue otherwise this will be closed in 5 days