SynapseML
 SynapseML copied to clipboard
SynapseML copied to clipboard
[BUG]An error occurred while calling o1156.fit. : java.lang.UnsatisfiedLinkError:
SynapseML version
0.10.2
System information
- Language version : python 3.9
- Spark Version : 3.2.1
- Spark Platform : EMR Notebook (Pyspark Kernel)
Describe the problem
I'm testing a demo code for using LightGBMClassifier on both local machine (with Spark 3.3)and on EMR Cluster. And I am stuck at the same following error.
From EMR Notebook

From Local Machine

Code to reproduce issue
.......... feature_cols = train_df.columns[1:] featurizer = VectorAssembler(inputCols=feature_cols, outputCol='features') train_data = featurizer.transform(train_df) model = LightGBMClassifier(objective="binary", featuresCol="features", labelCol="is_useful", isUnbalance=True) model_train = model.fit(train_data)
Other info / logs
No response
What component(s) does this bug affect?
- [ ]
area/cognitive: Cognitive project - [ ]
area/core: Core project - [ ]
area/deep-learning: DeepLearning project - [X]
area/lightgbm: Lightgbm project - [ ]
area/opencv: Opencv project - [ ]
area/vw: VW project - [ ]
area/website: Website - [ ]
area/build: Project build system - [ ]
area/notebooks: Samples under notebooks folder - [ ]
area/docker: Docker usage - [ ]
area/models: models related issue
What language(s) does this bug affect?
- [ ]
language/scala: Scala source code - [X]
language/python: Pyspark APIs - [ ]
language/r: R APIs - [ ]
language/csharp: .NET APIs - [ ]
language/new: Proposals for new client languages
What integration(s) does this bug affect?
- [X]
integrations/synapse: Azure Synapse integrations - [ ]
integrations/azureml: Azure ML integrations - [ ]
integrations/databricks: Databricks integrations
Hey @raxu-wish :wave:! Thank you so much for reporting the issue/feature request :rotating_light:. Someone from SynapseML Team will be looking to triage this issue soon. We appreciate your patience.
Hi @raxu-wish , thank you for reporting the issue. Can you share the link to the demo code you are using?
Hi @raxu-wish , thank you for reporting the issue. Can you share the link to the demo code you are using?
Hi @JessicaXYWang
import findspark
findspark.init("/opt/homebrew/Cellar/apache-spark/3.3.1/libexec")
import pyspark
from pyspark import SparkContext, SparkConf
from pyspark.sql.window import Window
from pyspark.sql import functions as func
from pyspark.sql.types import StringType,BooleanType,DateType
from pyspark.ml.feature import VectorAssembler, StringIndexer
from pyspark.sql.functions import *
spark = (pyspark.sql.SparkSession.builder.master("local[2]")) \
.appName("local-1672912084343") \
.config("spark.jars.packages", "com.microsoft.azure:synapseml_2.12:0.10.2") \
.config("spark.jars.repositories", "https://mmlspark.azureedge.net/maven")\
.getOrCreate()
from synapse.ml.lightgbm import LightGBMClassifier, LightGBMRegressor
from synapse.ml.core.platform import materializing_display as display
if __name__ == "__main__":
conf = SparkConf()
print(conf.getAll())
print('spark version:', spark.version)
columns = [ "is_useful", "language", "users_count"]
data = [(0, "Java", "a"), (1, "Python", "b"), (1, "Python", "b"), (0, "Java", "b"),
(0, "Java", "av"), (1, "Python", "a"), (1, "Python", "b"), (0, "Java", "ab"),
(0, "Java", "a"), (1, "Python", "sa"), (1, "Python", "d"), (0, "Java", "v")]
df= spark.createDataFrame(data).toDF(*columns)
print(df.show())
catergories = ["language", "users_count"]
categories_idx= ["language_idx", "users_count_idx"]
indexer = StringIndexer(inputCols=catergories, outputCols=categories_idx)
train_df = indexer.fit(df).transform(df)['is_useful', 'language_idx', 'users_count_idx']
print('train_df:', train_df.show())
feature_cols = train_df.columns[1:]
featurizer = VectorAssembler(inputCols=feature_cols, outputCol='features')
train_data = featurizer.transform(train_df)
print('train_data:', train_data)
print(display(train_data.groupBy("is_useful").count()))
model = LightGBMClassifier(objective="binary", featuresCol="features", labelCol="is_useful", isUnbalance=True)
model_train = model.fit(train_data)
Hi @raxu-wish , thank you for reporting the issue. Can you share the link to the demo code you are using?
It's very similar to this issue -> https://github.com/microsoft/SynapseML/issues/1224#issuecomment-957169802
@raxu-wish this looks like a binary incompatibility issue. Adding @svotaw here who might know more about the supported architectures
Hi raxu and jcui, I cannot repro this on Azure Synapse Analytics or Databricks.
I'll try it with EMR on the weekend and get back to you before next Monday.
Hi @raxu-wish , could you try:
%%configure -f
{
"name": "synapseml",
"conf": {
"spark.jars.packages": "com.microsoft.azure:synapseml_2.12:0.10.2",
"spark.jars.repositories": "https://mmlspark.azureedge.net/maven"
}
}
from pyspark.ml.feature import VectorAssembler, StringIndexer
from synapse.ml.lightgbm import LightGBMClassifier, LightGBMRegressor
columns = [ "is_useful", "language", "users_count"]
data = [(0, "Java", "a"), (1, "Python", "b"), (1, "Python", "b"), (0, "Java", "b"),
(0, "Java", "av"), (1, "Python", "a"), (1, "Python", "b"), (0, "Java", "ab"),
(0, "Java", "a"), (1, "Python", "sa"), (1, "Python", "d"), (0, "Java", "v")]
df= spark.createDataFrame(data).toDF(*columns)
print(df.show())
catergories = ["language", "users_count"]
categories_idx= ["language_idx", "users_count_idx"]
indexer = StringIndexer(inputCols=catergories, outputCols=categories_idx)
train_df = indexer.fit(df).transform(df)['is_useful', 'language_idx', 'users_count_idx']
print('train_df:', train_df.show())
feature_cols = train_df.columns[1:]
featurizer = VectorAssembler(inputCols=feature_cols, outputCol='features')
train_data = featurizer.transform(train_df)
print('train_data:', train_data)
print(display(train_data.groupBy("is_useful").count()))
model = LightGBMClassifier(objective="binary", featuresCol="features", labelCol="is_useful", isUnbalance=True)
model_train = model.fit(train_data)
and see if the problem still exists?
Hi @JessicaXYWang Yeah that's the exact same code snippet I tried on EMR Notebook. And the first screenshot is the error log corresponds to it.
@raxu-wish I cannot get a repro there.
Here is my configuration, everything else is default.
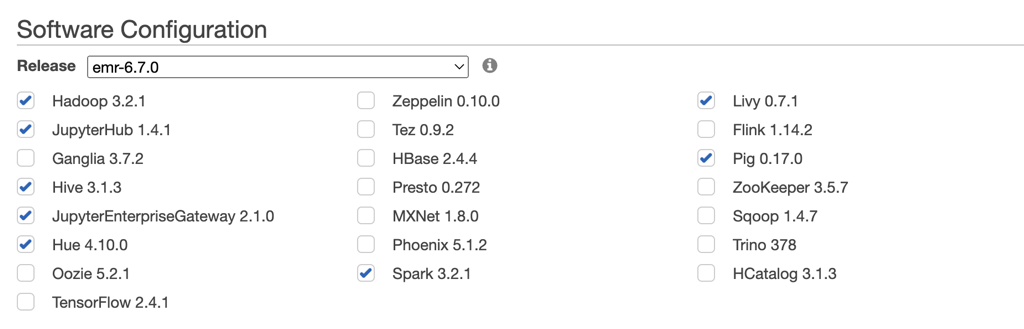 and here are my results:
and here are my results:
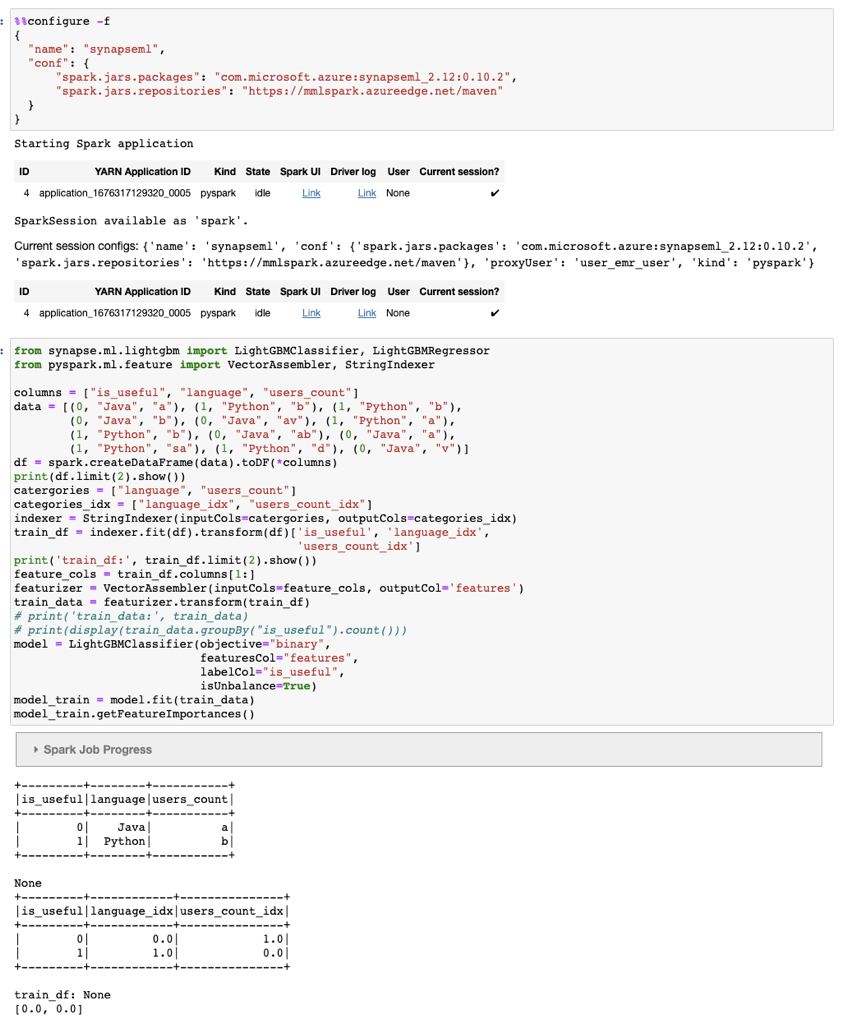
I'd recommend check with AWS for this problem.
Hi @JessicaXYWang I've been facing same issue even in local.
Can you please help me identify the correct link to download the jar files?
Using this in local --> pyspark --packages com.microsoft.azure:synapseml_2.12:0.11.0

And below error in EMR An error was encountered: An error occurred while calling o545.fit. : java.lang.UnsatisfiedLinkError: /mnt/tmp/mml-natives3919960614392113149/lib_lightgbm.so: /lib64/libm.so.6: version `GLIBC_2.27' not found (required by /mnt/tmp/mml-natives3919960614392113149/lib_lightgbm.so) at java.lang.ClassLoader$NativeLibrary.load(Native Method) at java.lang.ClassLoader.loadLibrary0(ClassLoader.java:1934) at java.lang.ClassLoader.loadLibrary(ClassLoader.java:1817) at java.lang.Runtime.load0(Runtime.java:782) at java.lang.System.load(System.java:1100) at com.microsoft.azure.synapse.ml.core.env.NativeLoader.loadLibraryByName(NativeLoader.java:66) at com.microsoft.azure.synapse.ml.lightgbm.LightGBMUtils$.initializeNativeLibrary(LightGBMUtils.scala:33) at com.microsoft.azure.synapse.ml.lightgbm.LightGBMBase.train(LightGBMBase.scala:36) at com.microsoft.azure.synapse.ml.lightgbm.LightGBMBase.train$(LightGBMBase.scala:35) at com.microsoft.azure.synapse.ml.lightgbm.LightGBMRanker.train(LightGBMRanker.scala:26) at com.microsoft.azure.synapse.ml.lightgbm.LightGBMRanker.train(LightGBMRanker.scala:26) at org.apache.spark.ml.Predictor.fit(Predictor.scala:151) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:244) at py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:357) at py4j.Gateway.invoke(Gateway.java:282) at py4j.commands.AbstractCommand.invokeMethod(AbstractCommand.java:132) at py4j.commands.CallCommand.execute(CallCommand.java:79) at py4j.GatewayConnection.run(GatewayConnection.java:238) at java.lang.Thread.run(Thread.java:750)
@arshee2403 hi Arshee, can you provide your EMR cluster setup (Release, Applications) and code to repro?
Hi @JessicaXYWang I've been facing same issue even in local. Can you please help me identify the correct link to download the jar files? Using this in local --> pyspark --packages com.microsoft.azure:synapseml_2.12:0.11.0
And below error in EMR An error was encountered: An error occurred while calling o545.fit. : java.lang.UnsatisfiedLinkError: /mnt/tmp/mml-natives3919960614392113149/lib_lightgbm.so: /lib64/libm.so.6: version `GLIBC_2.27' not found (required by /mnt/tmp/mml-natives3919960614392113149/lib_lightgbm.so) at java.lang.ClassLoader$NativeLibrary.load(Native Method) at java.lang.ClassLoader.loadLibrary0(ClassLoader.java:1934) at java.lang.ClassLoader.loadLibrary(ClassLoader.java:1817) at java.lang.Runtime.load0(Runtime.java:782) at java.lang.System.load(System.java:1100) at com.microsoft.azure.synapse.ml.core.env.NativeLoader.loadLibraryByName(NativeLoader.java:66) at com.microsoft.azure.synapse.ml.lightgbm.LightGBMUtils$.initializeNativeLibrary(LightGBMUtils.scala:33) at com.microsoft.azure.synapse.ml.lightgbm.LightGBMBase.train(LightGBMBase.scala:36) at com.microsoft.azure.synapse.ml.lightgbm.LightGBMBase.train$(LightGBMBase.scala:35) at com.microsoft.azure.synapse.ml.lightgbm.LightGBMRanker.train(LightGBMRanker.scala:26) at com.microsoft.azure.synapse.ml.lightgbm.LightGBMRanker.train(LightGBMRanker.scala:26) at org.apache.spark.ml.Predictor.fit(Predictor.scala:151) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:244) at py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:357) at py4j.Gateway.invoke(Gateway.java:282) at py4j.commands.AbstractCommand.invokeMethod(AbstractCommand.java:132) at py4j.commands.CallCommand.execute(CallCommand.java:79) at py4j.GatewayConnection.run(GatewayConnection.java:238) at java.lang.Thread.run(Thread.java:750)
I get the exact same error about `GLIBC_2.27' not found. My setup is very simple:
I'm trying to run a pyspark application in Jupyter environment.
%%configure -f
{
"name": "synapseml",
"conf": {
"spark.jars.packages": "com.microsoft.azure:synapseml_2.12:0.11.1-spark3.3",
"spark.jars.repositories": "https://mmlspark.azureedge.net/maven"
}
}
def get_session(appName: str) -> SparkSession:
return (
SparkSession.builder.appName(appName)
.config("spark.jars.packages", "org.mlflow:mlflow-spark:1.30.0")
.config(
"spark.jars.packages", "com.microsoft.azure:synapseml_2.12:0.11.1-spark3.3"
)
.config("spark.jars.repositories", "https://mmlspark.azureedge.net/maven")
.config("spark.sql.shuffle.partitions", 1000)
.config("spark.dynamicAllocation.executorIdleTimeout", 600)
.config("spark.default.parallelism", 1000)
.config("spark.sql.adaptive.enabled", True)
.config("spark.sql.adaptive.coalescePartitions.enabled", True)
.config("spark.sql.execution.arrow.pyspark.enabled", True)
.config("spark.sql.execution.arrow.pyspark.fallback.enabled", True)
.enableHiveSupport()
.getOrCreate()
)
LightGBM is an estimator in a pipeline that's part of a CrossValidator. Please suggest how to get lightgbm running in EMR
@JessicaXYWang - I've tracked down the issue and you might need to rebuild LightGBM. As of now Amazon EMR only supports variants of Amazon Linux 2 which have glibc version 2.26. I've tried running different operating systems but it will simply not allow that to happen, including Amazon Linux 2023 which is released by them.
Thus if you can build LightGBM with glibc < 2.27 then we can use it in EMR. I know its a bit strange to have to rebuild a package just to make it run in a particular environment but EMR has a very wide adoption and it will lead to increased usage of your framework.
cc: @mhamilton723 , @imatiach-msft
@JessicaXYWang - I've tracked down the issue and you might need to rebuild LightGBM. As of now Amazon EMR only supports variants of Amazon Linux 2 which have glibc version 2.26. I've tried running different operating systems but it will simply not allow that to happen, including Amazon Linux 2023 which is released by them.
Thus if you can build LightGBM with glibc < 2.27 then we can use it in EMR. I know its a bit strange to have to rebuild a package just to make it run in a particular environment but EMR has a very wide adoption and it will lead to increased usage of your framework.
cc: @mhamilton723 , @imatiach-msft
@vishalovercome Thanks for tracked down the issue. the glibc version is controlled by LightGBM build.
@svotaw , Amazon EMR users can not use the latest version due to this issue. Can we find a snapshot works fine with glibc 2.26?
Thanks a lot for your reply @JessicaXYWang ! Will the snapshot version run on PySpark 3.3 or even 3.4?
@JessicaXYWang / @svotaw / @imatiach-msft - I got in touch with AWS regarding this issue and they've suggested installing and rebuilding lightgbm like this - https://gist.github.com/dacort/5133d0887c7ac1cd8e4a7981e33356ff. The Dockerfile contains the pertinent information. Since you understand the internals of synapse/lightgbm, I wanted to know whether this will work. Some of my doubts would be:
- Is
lib_lightgbm.sothe only file that needs to be copied over? - What if I wanted to use isolation forest? Would I have to rebuild that as well?
- Is it a problem if OS has glibc 2.26 while certain package that was built with a different version of cmake? I'm not sure about binary compatibilities
- If this solution won't work, then do let me know what will
It would be great if there is some advice on this - how can EMR run the newer versions of LGBM (I am interested in the streaming execution)?
Hi, Damon here - EMR team member and author of the above gist. I think there are two issues here:
- The original reporter @raxu-wish seems to have an issue with cross-platform support based on the
can't load AMD 64-bit .so on a AARCH64-bit platform. I'm guessing they were possibly running a Graviton cluster? - Recent folks have had problems with GLIBC issues based on the
/lib_lightgbm.so: /lib64/libm.so.6: version 'GLIBC_2.27' not found
Both EMR and SageMaker Spark Container (which somebody else used as their base image) use Amazon Linux 2 (AL2) with glibc 2.26.
As mentioned by @vishalovercome I was able to recompile lightgbm on AL2, but would love to hear answers to their questions re: some of the doubts.
Another option on EMR on EC2 is to use container images with a more recent OS. As an example, I was able to run through this LightGBM example with a python:3-11-slim base image (dockerfile below) and a standard spark-submit with --packages com.microsoft.azure:synapseml_2.12:0.11.1,org.apache.hadoop:hadoop-azure:3.3.1.
FROM python:3.11-slim AS base
# Copy OpenJDK 8
ENV JAVA_HOME=/opt/java/openjdk
COPY --from=eclipse-temurin:8 $JAVA_HOME $JAVA_HOME
ENV PATH="${JAVA_HOME}/bin:${PATH}"
# Install libgomp
RUN apt-get update && \
apt install -y libgomp1
# Upgrade pip
RUN pip3 install --upgrade pip
# Configure PySpark
ENV PYSPARK_DRIVER_PYTHON python3
ENV PYSPARK_PYTHON python3
# Install numpy
RUN pip3 install numpy~=1.25.0