SynapseML
 SynapseML copied to clipboard
SynapseML copied to clipboard
Getting typeError: 'JavaPackage' object is not callable. for LightGBMRegressor.
Describe the bug A clear and concise description of what the bug is. LightGBMRegressor throws 'JavaPackage' object is not callable
To Reproduce
Steps to reproduce the behavior, code snippets encouraged
import pyspark
spark = pyspark.sql.SparkSession.builder.appName("MyApp")
.config("spark.jars.packages", "com.microsoft.azure:synapseml_2.12:0.9.4")
.config("spark.jars.repositories", "https://mmlspark.azureedge.net/maven")
.getOrCreate()
!install-package synapseml==0.9.4
from synapse.ml.lightgbm import LightGBMRegressor
I am using hyperopt for parameter search. But then I think the error is from the LightGBMRegressor.
Expected behavior A clear and concise description of what you expected to happen.
Info (please complete the following information):
- SynapseML Version: [e.g. v0.17] 0.9.4
- Spark Version [e.g. 2.4.3]. 2.4.7
- Spark Platform [e.g. Databricks]. company has own builtin platform
** Stacktrace**
Please post the stacktrace here if applicable
TypeError Traceback (most recent call last)
<ipython-input-75-80e45f50d04a> in <module>
4 algo=HYPEROPT_ALGO,
5 max_evals=N_HYPEROPT_PROBES,
----> 6 trials=trials)
~/.pyenv/versions/pip-3.7.5/lib/python3.7/site-packages/hyperopt/fmin.py in fmin(fn, space, algo, max_evals, timeout, loss_threshold, trials, rstate, allow_trials_fmin, pass_expr_memo_ctrl, catch_eval_exceptions, verbose, return_argmin, points_to_evaluate, max_queue_len, show_progressbar, early_stop_fn, trials_save_file)
553 show_progressbar=show_progressbar,
554 early_stop_fn=early_stop_fn,
--> 555 trials_save_file=trials_save_file,
556 )
557
~/.pyenv/versions/pip-3.7.5/lib/python3.7/site-packages/hyperopt/base.py in fmin(self, fn, space, algo, max_evals, timeout, loss_threshold, max_queue_len, rstate, verbose, pass_expr_memo_ctrl, catch_eval_exceptions, return_argmin, show_progressbar, early_stop_fn, trials_save_file)
686 show_progressbar=show_progressbar,
687 early_stop_fn=early_stop_fn,
--> 688 trials_save_file=trials_save_file,
689 )
690
~/.pyenv/versions/pip-3.7.5/lib/python3.7/site-packages/hyperopt/fmin.py in fmin(fn, space, algo, max_evals, timeout, loss_threshold, trials, rstate, allow_trials_fmin, pass_expr_memo_ctrl, catch_eval_exceptions, verbose, return_argmin, points_to_evaluate, max_queue_len, show_progressbar, early_stop_fn, trials_save_file)
584
585 # next line is where the fmin is actually executed
--> 586 rval.exhaust()
587
588 if return_argmin:
~/.pyenv/versions/pip-3.7.5/lib/python3.7/site-packages/hyperopt/fmin.py in exhaust(self)
362 def exhaust(self):
363 n_done = len(self.trials)
--> 364 self.run(self.max_evals - n_done, block_until_done=self.asynchronous)
365 self.trials.refresh()
366 return self
~/.pyenv/versions/pip-3.7.5/lib/python3.7/site-packages/hyperopt/fmin.py in run(self, N, block_until_done)
298 else:
299 # -- loop over trials and do the jobs directly
--> 300 self.serial_evaluate()
301
302 self.trials.refresh()
~/.pyenv/versions/pip-3.7.5/lib/python3.7/site-packages/hyperopt/fmin.py in serial_evaluate(self, N)
176 ctrl = base.Ctrl(self.trials, current_trial=trial)
177 try:
--> 178 result = self.domain.evaluate(spec, ctrl)
179 except Exception as e:
180 logger.error("job exception: %s" % str(e))
~/.pyenv/versions/pip-3.7.5/lib/python3.7/site-packages/hyperopt/base.py in evaluate(self, config, ctrl, attach_attachments)
890 print_node_on_error=self.rec_eval_print_node_on_error,
891 )
--> 892 rval = self.fn(pyll_rval)
893
894 if isinstance(rval, (float, int, np.number)):
<ipython-input-72-7d028191e57e> in objective(space)
13
14 print(lgb_params)
---> 15 lightgbm = LightGBMRegressor()
16
17
/usr/local/spark/python/pyspark/__init__.py in wrapper(self, *args, **kwargs)
108 raise TypeError("Method %s forces keyword arguments." % func.__name__)
109 self._input_kwargs = kwargs
--> 110 return func(self, **kwargs)
111 return wrapper
112
~/.pyenv/versions/pip-3.7.5/lib/python3.7/site-packages/synapse/ml/lightgbm/LightGBMRegressor.py in __init__(self, java_obj, alpha, baggingFraction, baggingFreq, baggingSeed, binSampleCount, boostFromAverage, boostingType, categoricalSlotIndexes, categoricalSlotNames, chunkSize, defaultListenPort, driverListenPort, dropRate, earlyStoppingRound, featureFraction, featuresCol, featuresShapCol, fobj, improvementTolerance, initScoreCol, isProvideTrainingMetric, labelCol, lambdaL1, lambdaL2, leafPredictionCol, learningRate, matrixType, maxBin, maxBinByFeature, maxDeltaStep, maxDepth, maxDrop, metric, minDataInLeaf, minGainToSplit, minSumHessianInLeaf, modelString, negBaggingFraction, numBatches, numIterations, numLeaves, numTasks, numThreads, objective, parallelism, posBaggingFraction, predictionCol, repartitionByGroupingColumn, skipDrop, slotNames, timeout, topK, tweedieVariancePower, uniformDrop, useBarrierExecutionMode, useSingleDatasetMode, validationIndicatorCol, verbosity, weightCol, xgboostDartMode)
275 super(LightGBMRegressor, self).__init__()
276 if java_obj is None:
--> 277 self._java_obj = self._new_java_obj("com.microsoft.azure.synapse.ml.lightgbm.LightGBMRegressor", self.uid)
278 else:
279 self._java_obj = java_obj
/usr/local/spark/python/pyspark/ml/wrapper.py in _new_java_obj(java_class, *args)
65 java_obj = getattr(java_obj, name)
66 java_args = [_py2java(sc, arg) for arg in args]
---> 67 return java_obj(*java_args)
68
69 @staticmethod
TypeError: 'JavaPackage' object is not callable
If the bug pertains to a specific feature please tag the appropriate CODEOWNER for better visibility
Additional context Add any other context about the problem here.
AB#1984505
@musram Strange, it looks like the underlying java code is not setup/working.
Do you see anything in the console when running this setup code:
spark = pyspark.sql.SparkSession.builder.appName("MyApp") .config("spark.jars.packages", "com.microsoft.azure:synapseml_2.12:0.9.4") .config("spark.jars.repositories", "https://mmlspark.azureedge.net/maven") .getOrCreate()
Are you running locally or on a cluster?
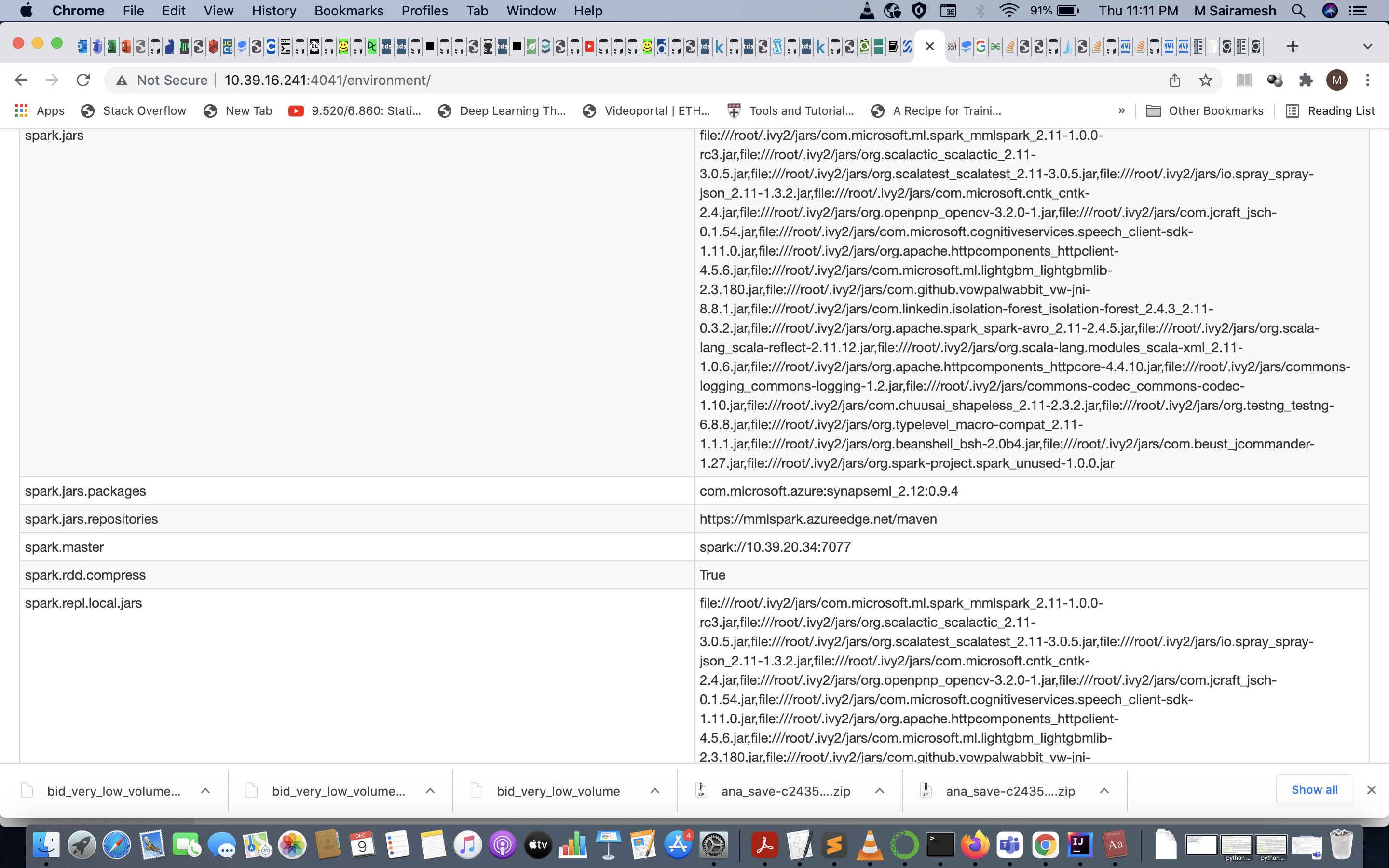
@imatiach-msft, I run on the cluster. I had tried using mmlspark which was not working and felt outdated. Then I tried using synapseML. I have attached the screenshot which confirms the jar files. I had specified the version in the issue. I doubt it is because of the version. Can you pls confirm it? If is it is a version then where do I find the compatible synapseML.
@musram it looks like you are specifying a mix of mmlspark (the old name of this repo) jars and synapseml package, but I don't think that is the problem. It looks like you are using one of the latest releases so that should be fine.
Based on the error it looks like the python just can't call the java code:
self._new_java_obj("com.microsoft.azure.synapse.ml.lightgbm.LightGBMRegressor", self.uid)
I do see some similar issue with lots of things people tried here, some worked and some got stuck: https://github.com/microsoft/SynapseML/issues/718
But I don't see anything that might help you...
I also see this same exact error on a cloudera cluster here: https://github.com/microsoft/SynapseML/issues/772
The issue is very clear though, for some reason that cluster just can't load the jar files, but the python is getting installed fine.
What does this install-package command do: !install-package synapseml==0.9.4 I am not familiar with it...
@musram oh, I just noticed this: Spark Version [e.g. 2.4.3]. 2.4.7 it looks like you are using an old version of spark. I don't think it will work with the newest version of synapseml unfortunately. I'm guessing there is some console which shows how the package is getting installed and there is some error there but you are not seeing it for some reason. Also adding @mhamilton723 in case he might have some ideas on this.
@musram note the doc on the main page:
SynapseML requires Scala 2.12, Spark 3.0+, and Python 3.6+. See the API documentation for Scala and for PySpark.
@musram this error looks like its not properly loading the library from your spark packages. Please see the logs to ensure that the maven packages are properly downloading. If the spark session has already been created by the time you pass it the spark packages, it wont work. Also the python install isn't necessary as the spark package brings in the python bindings. You are probabbly in a state where you are using the python bindings, but not bringing in the scala bindings. Going to close this issue but please comment if this fix doesent work for you.