DeepSpeedExamples
 DeepSpeedExamples copied to clipboard
DeepSpeedExamples copied to clipboard
Example models using DeepSpeed

│ /data/miniconda3/envs/arainmodel/lib/python3.10/site-packages/deepspeed/runtime/hybrid_engine.py │ │ :296 in create_inference_containers │ │ │ │ 293 │ │ │ │ │ self._orig_modules_others.append(child) │ │ 294 │ │ │ │ │ self._orig_fwds_others.append(child.forward) │ │ 295...
I run command: `python train.py --actor-model facebook/opt-1.3b --reward-model facebook/opt-350m --deployment-type single_node` when the process run into `step 2`: ``` Launch command: bash /mnt/disks/data-1/marvin/DeepSpeedExamples/applications/DeepSpeed-Chat/training/step2_reward_model_finetuning/training_scripts/single_node/run_350m.sh /mnt/disks/data-1/marvin/DeepSpeedExamples/applications/DeepSpeed-Chat/output/reward-models/350m ``` we encounter the following error,...
My questions are mostly for the stage 3, according to the doc https://github.com/microsoft/DeepSpeedExamples/blob/master/applications/DeepSpeed-Chat/training/step3_rlhf_finetuning/training_scripts/README.md it says that ``` If you don't have step 1 and step 2 models. You may simply...
This PR fixes: 1. the actor/critic mean loss calculation 2. step-3 training script for 1.3b model on single gpu 3. some typos
in step2, how to slove this question? 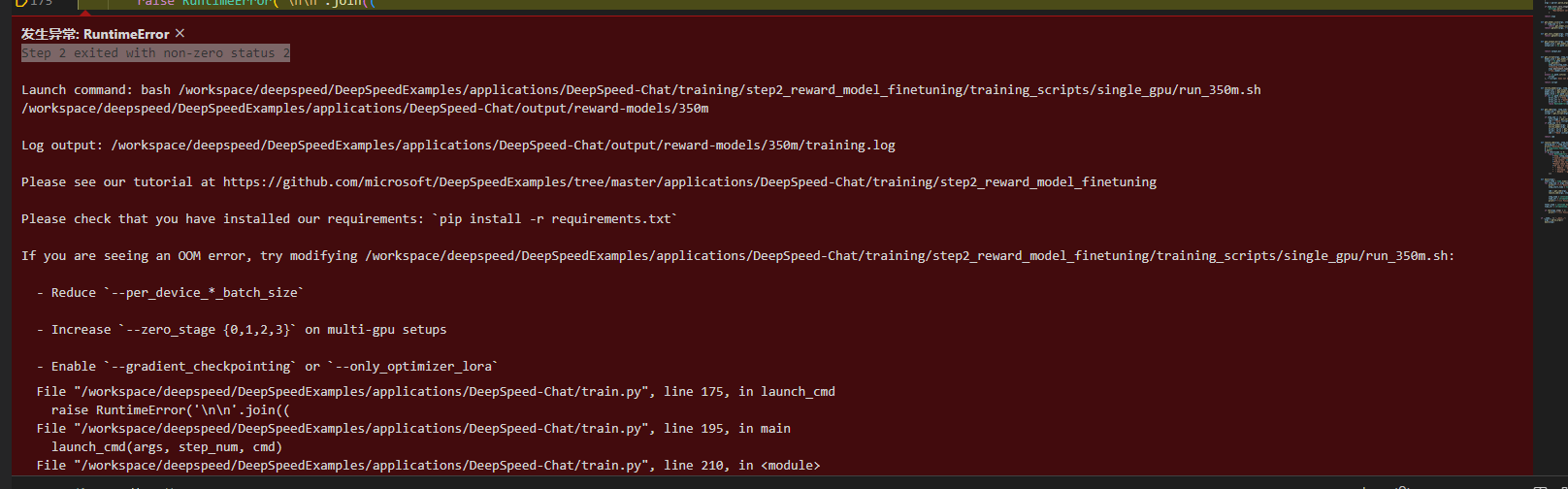 @codedecde
Regarding the two parts of generation training data and PPO training in the code(applications/DeepSpeed-Chat/training/step3_rlhf_finetuning/main.py), I think that the current training is more like the onPolicy method. Because per_device_train_batch_size==per_device_mini_train_batch_size, now the...
I want to launch the run_66b RLHF in slurm cluster. I tried to find some tutorial, but failed.
When I run a script `bash training_scripts/other_language/run_chinese.sh`, I encounter a problem. ``` Traceback (most recent call last): File "xxx/DeepSpeedExamples/applications/DeepSpeed-Chat/training/step1_supervised_finetuning/main.py", line 339, in main() File "xxx/DeepSpeedExamples/applications/DeepSpeed-Chat/training/step1_supervised_finetuning/main.py", line 284, in main model,...
I trained the PPO model, use the gpt. I modified the option of model_name_or_path from opt to gpt2 I passed step 1 and step 2,But An error occurred in step...
Is there anyone else meet such problem? Single_gpu model with 1.3B model, the two previous steps: step1 and step2 are both successfully complete, but the step3 yields errors when **nvcc**...