DeepSpeedExamples
 DeepSpeedExamples copied to clipboard
DeepSpeedExamples copied to clipboard
Why does the rw_eval.py script return a different score for the same sample each time?
- model: llama-2-7b-hf
- execute command: python rw_eval.py --model_name_or_path /data/llama-2-hf/llama-2-7b-hf/
- GPU: A6000(48G)
- result
-
first result
-
second result
- Question: Why does the rw_eval.py script return a different score for the same sample each time? How to modify to make the same sample to return the same score each time?
have you found that there is a big difference between the results of RM training and those measured by rw_eval.py? The training results show that the acc is about 0.99, average chosen score 10, averge rejected score -9, the difference between chosen and rejected is very large, but the reward value is very small when using rw_eval.py test.
have you found that there is a big difference between the results of RM training and those measured by rw_eval.py? The training results show that the acc is about 0.99, average chosen score 10, averge rejected score -9, the difference between chosen and rejected is very large, but the reward value is very small when using rw_eval.py test.
I think may be because of the create_critic_model in rw_eval didn't load the v_head params from ckpt, they init randomly. There are also problems in create_critic_model in init the base_model since the key of state_dict becomes rwtransformers.layers......, which lead to loading failure using auto_class.from_pretrained().
Thank you for your answer. Is there any way to solve this problem? I feel that the Step3 reward model does not load correctly either.
Thank you for your answer. Is there any way to solve this problem? I feel that the Step3 reward model does not load correctly either.
the code by setting rlhf_training = True in create_critic_model() is generally okay. But if you directly use this args in rw_eval will meet some distributed errors. Consider refactor rw_eval by the code used in rlhf_training=True
Thank you for your answer. Is there any way to solve this problem? I feel that the Step3 reward model does not load correctly either.
for step 3 reward model loading, i also observe the rm and critic model output nan. Problem haven't been well located yet. One possible problem is that in RewardModel, self.PAD_ID=tokenizer.pad_token_id, but some tokenizer doen't have pad_token_id, change to eos_token_id or some pre-defined token
you are right, I print input_id and find that actor's pad_id is inconsistent with rm's pad_id for step3. Use rw_eval.py to load the reward model and pass it into rlhf_training=True to get the correct reward.
have you found that there is a big difference between the results of RM training and those measured by rw_eval.py? The training results show that the acc is about 0.99, average chosen score 10, averge rejected score -9, the difference between chosen and rejected is very large, but the reward value is very small when using rw_eval.py test.你有没有发现RM训练的结果和rw_eval.py测量的结果差别很大?训练结果显示acc约为0.99,平均选择分数10,平均拒绝分数-9,选择和拒绝的差异很大,但使用rw_eval.py测试时奖励值很小。
Yes, I have encountered the same issue. I only trained step2, the reward model, and got a training result of around acc 0.9. However, when using rw_reward.py with the same sample datas, there's a significant difference. Do you know the reason or how to solve this?"
@jiangchengSilent @Luoxiaohei41
Thank you for your reply. I will try out your suggestions and will update you with any conclusions.
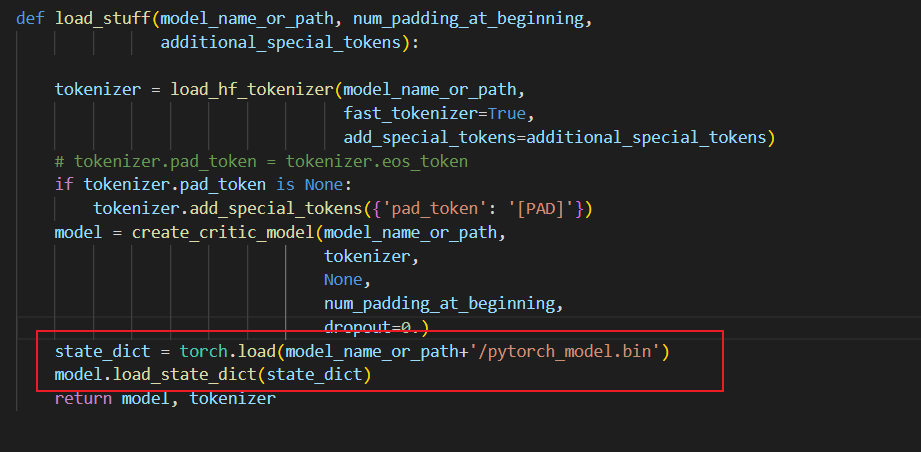
Insert the following two lines of code in the rw_eval.py file:
row 52: state_dict = torch.load(model_name_or_path+'/pytorch_model.bin')
row 53: model.load_state_dict(state_dict)
Insert the following two lines of code in the rw_eval.py file:在rw_eval.py文件中插入以下两行代码: row 52: state_dict = torch.load(model_name_or_path+'/pytorch_model.bin') 第52行:state_dict = torch.load(model_name_or_path+'/pytorch_model.bin') row 53: model.load_state_dict(state_dict) 第 53 行:model.load_state_dict(state_dict)
Thank you very much, the code has solved this problem.
Insert the following two lines of code in the rw_eval.py file: row 52: state_dict = torch.load(model_name_or_path+'/pytorch_model.bin') row 53: model.load_state_dict(state_dict)

I got a mismatch of parameters:
RuntimeError: Error(s) in loading state_dict for RewardModel: size mismatch for rwtransformer.embed_tokens.weight: copying a param with shape torch.Size([32000, 4096]) from checkpoint, the shape in current model is torch.Size([32008, 4096]).