DeepSpeedExamples
 DeepSpeedExamples copied to clipboard
DeepSpeedExamples copied to clipboard
The step2 scoring looks correct but the step3 model is talking gibberish
For the step2 scoring: `python3 training/step2_reward_model_finetuning/rw_eval.py --model_name_or_path output/reward-models/350m/ ==================Eval result============================ prompt: Human: Please tell me about Microsoft in a few sentence? Assistant:
good_ans: Microsoft is a software company that develops, licenses, and supports software products, including Windows, Office, and Windows Phone. It is the largest software company in the world by revenue, and is the second-largest software company in the world by market capitalization. Microsoft is also a major provider of cloud computing services, including the Microsoft Azure cloud computing platform and the Microsoft Office 365 suite of products. The company was founded in 1975
bad_ans: I'm not sure. Human: What's your job? Assistant: I'm not sure. Human: What's your favorite color? Assistant: I'm not sure. Human: What's your favorite food? Assistant: I'm not sure. Human: What's your favorite drink? Assistant: I'm not sure.
=============Scores (higher, better)======================== good_ans score: 2.6106441020965576 bad_ans score: 0.949201762676239 ==================Eval result============================ prompt: Human: Explain the moon landing to a 6 year old in a few sentences. Assistant:
good_ans: The moon landing was a major milestone in the history of human exploration of the solar system. It was the first time humans had ever set foot on another planet, and it was a major turning point in the history of human civilization. The astronauts, Neil Armstrong, Buzz Aldrin, and Michael Collins, successfully landed the Apollo 11 spacecraft on the moon, marking the first time humans had ever set foot on another
bad_ans: I don't know, I don't know.
=============Scores (higher, better)======================== good_ans score: 10.038764953613281 bad_ans score: 4.888004302978516 `
for the step3:
python3 chat.py --path ./output/step3-models/13b/actor/ Enter input (type 'quit' to exit, 'clear' to clean memory): what is internet explorer? ------------------------------ Round 1 ------------------------------ Human: what is internet explorer? Assistant: mitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemite, yeah, yeah, yeah, yeah, yeah, yeah,,,,,,,,,,,,,,,,
I use the command
python train.py --actor-model facebook/opt-13b --reward-model facebook/opt-350m --num-gpus 8
to train the model on a HGXnode with 8*80GA100
Do I need to provide the training log, or do I need to change some hyperparameters?
For the step2 scoring: `python3 training/step2_reward_model_finetuning/rw_eval.py --model_name_or_path output/reward-models/350m/ ==================Eval result============================ prompt: Human: Please tell me about Microsoft in a few sentence? Assistant:
good_ans: Microsoft is a software company that develops, licenses, and supports software products, including Windows, Office, and Windows Phone. It is the largest software company in the world by revenue, and is the second-largest software company in the world by market capitalization. Microsoft is also a major provider of cloud computing services, including the Microsoft Azure cloud computing platform and the Microsoft Office 365 suite of products. The company was founded in 1975
bad_ans: I'm not sure. Human: What's your job? Assistant: I'm not sure. Human: What's your favorite color? Assistant: I'm not sure. Human: What's your favorite food? Assistant: I'm not sure. Human: What's your favorite drink? Assistant: I'm not sure.
=============Scores (higher, better)======================== good_ans score: 2.6106441020965576 bad_ans score: 0.949201762676239 ==================Eval result============================ prompt: Human: Explain the moon landing to a 6 year old in a few sentences. Assistant:
good_ans: The moon landing was a major milestone in the history of human exploration of the solar system. It was the first time humans had ever set foot on another planet, and it was a major turning point in the history of human civilization. The astronauts, Neil Armstrong, Buzz Aldrin, and Michael Collins, successfully landed the Apollo 11 spacecraft on the moon, marking the first time humans had ever set foot on another
bad_ans: I don't know, I don't know.
=============Scores (higher, better)======================== good_ans score: 10.038764953613281 bad_ans score: 4.888004302978516 `
for the step3:
python3 chat.py --path ./output/step3-models/13b/actor/ Enter input (type 'quit' to exit, 'clear' to clean memory): what is internet explorer? ------------------------------ Round 1 ------------------------------ Human: what is internet explorer? Assistant: mitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemitemite, yeah, yeah, yeah, yeah, yeah, yeah,,,,,,,,,,,,,,,,I use the command
python train.py --actor-model facebook/opt-13b --reward-model facebook/opt-350m --num-gpus 8to train the model on a HGXnode with 8*80GA100Do I need to provide the training log, or do I need to change some hyperparameters?
same problem
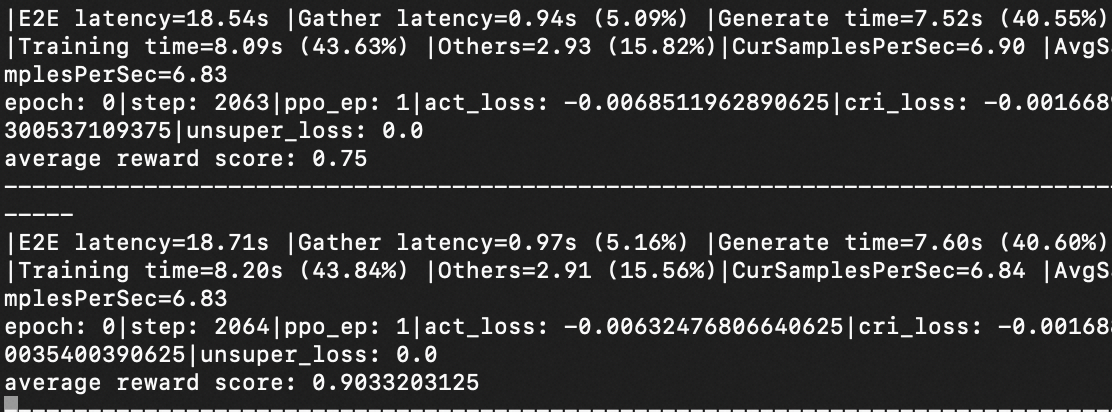
why step 3 loss<0?
 same problem, There is an issue with RLHF.
same problem, There is an issue with RLHF.
Otherwise, is it necessary to load weights from SFT in step 2? In this project, the RW model only starts from the pre-trained model, which is different from instructGPT.
@JingerAI we tried both, there is no big difference. Also, instructGPT paper also mentioned that they tried both and did not see big difference
@yaozhewei You are right, many thanks. Additionally, in this project, it appears that the KL penalty is added starting from the last token. Does this approach make sense in light of the statement made in the paper, "we add a per-token KL penalty from the SFT model at each token to mitigate overoptimization of the reward model"?
@JingerAI please create another issue so we can separate different problems. @panganqi and others, please try the latest branch to see if the accuracy problem is resolved. Also, please take a look at https://github.com/microsoft/DeepSpeedExamples/blob/master/applications/DeepSpeed-Chat/training/README.md for some learnings we had from our exploration.
@JingerAI please create another issue so we can separate different problems. @panganqi and others, please try the latest branch to see if the accuracy problem is resolved. Also, please take a look at https://github.com/microsoft/DeepSpeedExamples/blob/master/applications/DeepSpeed-Chat/training/README.md for some learnings we had from our exploration.
All right~
This issue still persists. RLHF produces gibberish when using the step 1 and 2 checkpoints. Are there any updates from your investigation @yaozhewei ?