DeepSpeedExamples
 DeepSpeedExamples copied to clipboard
DeepSpeedExamples copied to clipboard
unable to prodcude bing_bert with nvidia data
I used the default setting and run the code with 32 V100, the data was constructed from nvidia scripts. I was able to reproduce nvidia's results on Squad (F1=90), but failed to reoroduce deepspeed results.
stage 1, maxlen 128 (epoch 0-16)
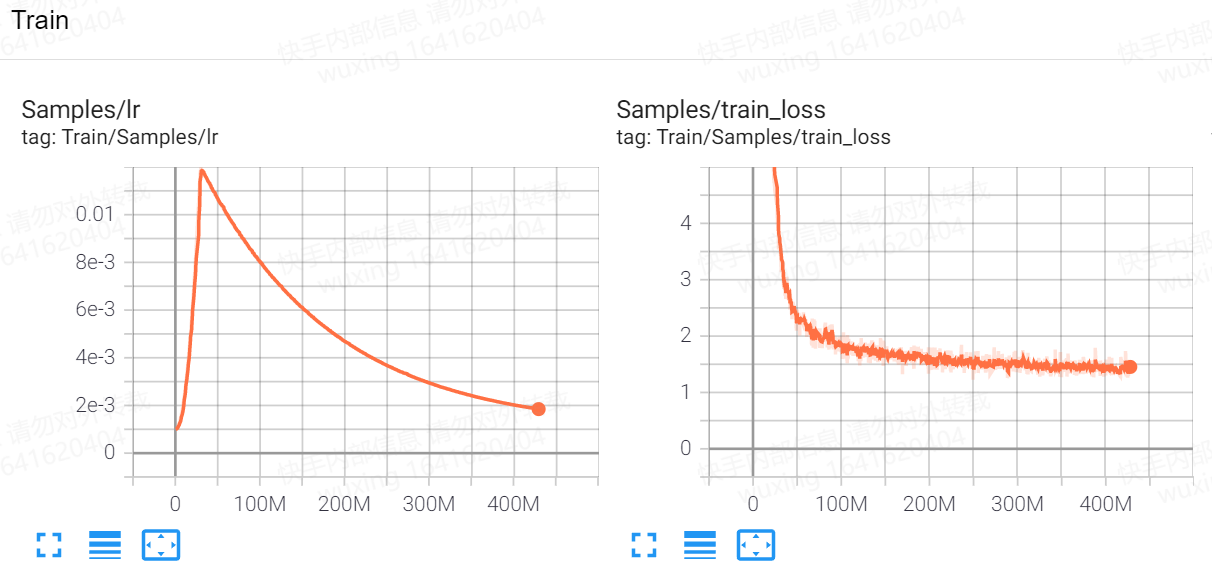 stage 2, maxlen 512 (epoch 17-20)
stage 2, maxlen 512 (epoch 17-20)
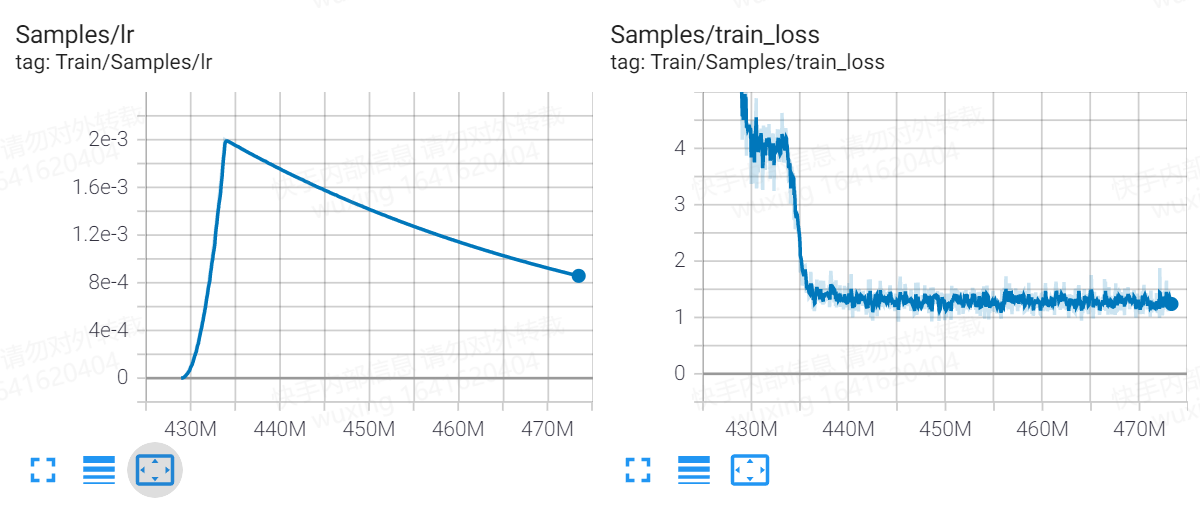
I evaluated the epoch20 checkpoint on BingBertSquad, and the results were unexpected low: F1=21
Thank you .
@1024er, apologies for the delay. Will take a closer look asap.
Thank you so much ~ Is there any progress please? :)
@1024er, apologies I have not had much time to explore this.
Hi,do you have time to take a look recently ? Thank you @tjruwase
Hi @1024er , have you ever encountered the problem that DeepSpeed will stall at the end of the first epoch (please refer to this issue)?
If so, I wonder if it is convenient for you to share your solution? If not, could you please tell me the DeepSpeed version and the Nvidia docker version you used in your experiments?
Hi @1024er , have you ever encountered the problem that DeepSpeed will stall at the end of the first epoch (please refer to this issue)?
If so, I wonder if it is convenient for you to share your solution? If not, could you please tell me the DeepSpeed version and the Nvidia docker version you used in your experiments?
This is due to the inconsistent amount of data on each gpu. This problem can be solved by processing the same amount of data per shard.
Hi @1024er , have you ever encountered the problem that DeepSpeed will stall at the end of the first epoch (please refer to this issue)? If so, I wonder if it is convenient for you to share your solution? If not, could you please tell me the DeepSpeed version and the Nvidia docker version you used in your experiments?
This is due to the inconsistent amount of data on each gpu. This problem can be solved by processing the same amount of data per shard.
Thank you for your reply. I'll have a try and share my results asap.
Hi @1024er , have you ever encountered the problem that DeepSpeed will stall at the end of the first epoch (please refer to this issue)? If so, I wonder if it is convenient for you to share your solution? If not, could you please tell me the DeepSpeed version and the Nvidia docker version you used in your experiments?
This is due to the inconsistent amount of data on each gpu. This problem can be solved by processing the same amount of data per shard.
Thank you for your reply. I'll have a try and share my results asap.
Have you encountered the problem with a very low F value mentioned above ?
Hi @1024er I'd suggest to double check whether the checkpoints are loaded successfully or not by checking the return values of the model.load_state_dict calls in https://github.com/microsoft/DeepSpeedExamples/blob/master/BingBertSquad/nvidia_run_squad_deepspeed.py#L828
There should be 2~4 missing keys depending on whether you use LM or not. If you see more than that, that's the problem
Hi, @1024er . Sorry for late reply. I've tried your method in the last few weeks. However, DeepSpeed still have some other bugs such as optimizer loss becomes NaN in fp16 mode.
I'm not working on this framework because I can't reproduce DeepSpeed's BERT results for almost two months. However, from my experience, I have tried Megatron-LM (which is also part of the code source of the DeepSpeed) For your reference, the latest version of Megatron-LM code can't reproduce the results on the SQUAD dataset either (its accuracy can only reach about 60% with BERT-base).
Good luck!