[BUG] Getting error when running deepseed in dolly training with exits with return code = -9
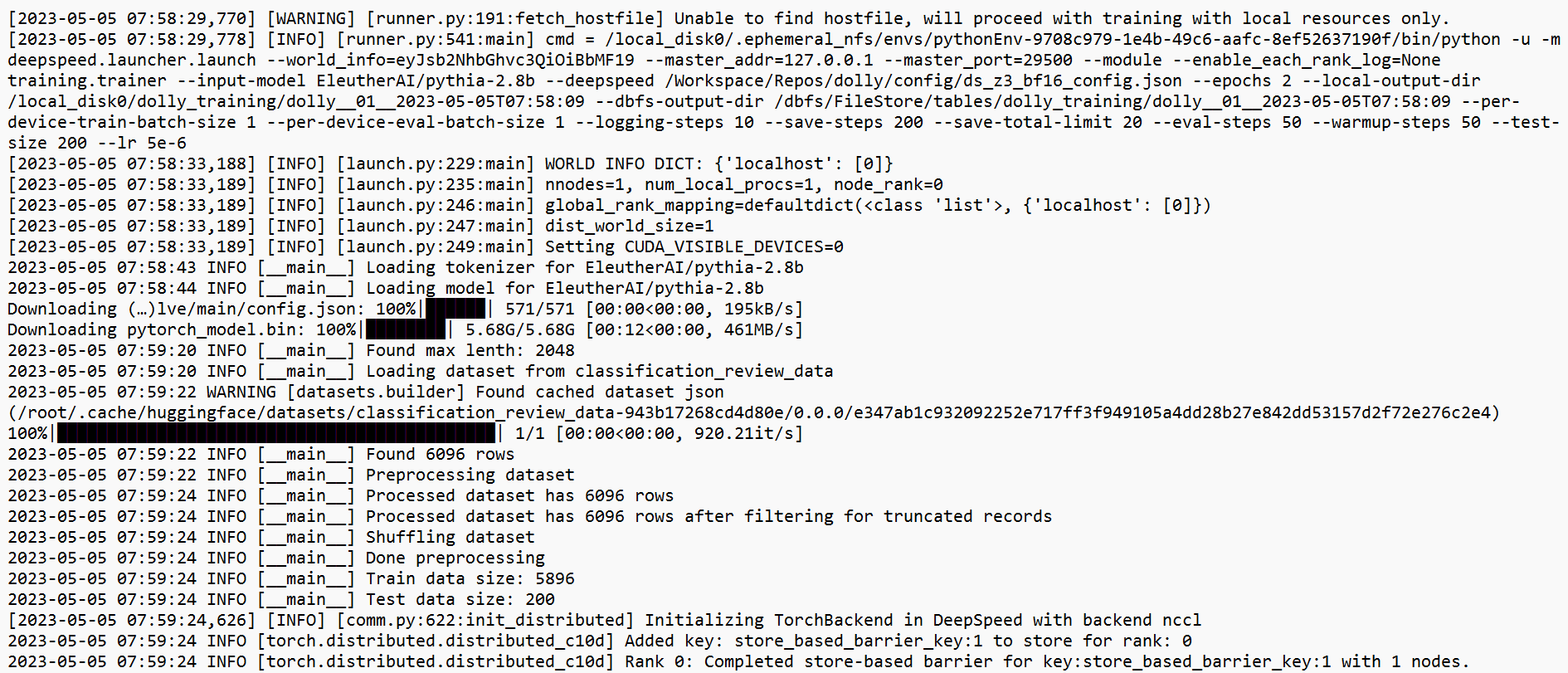
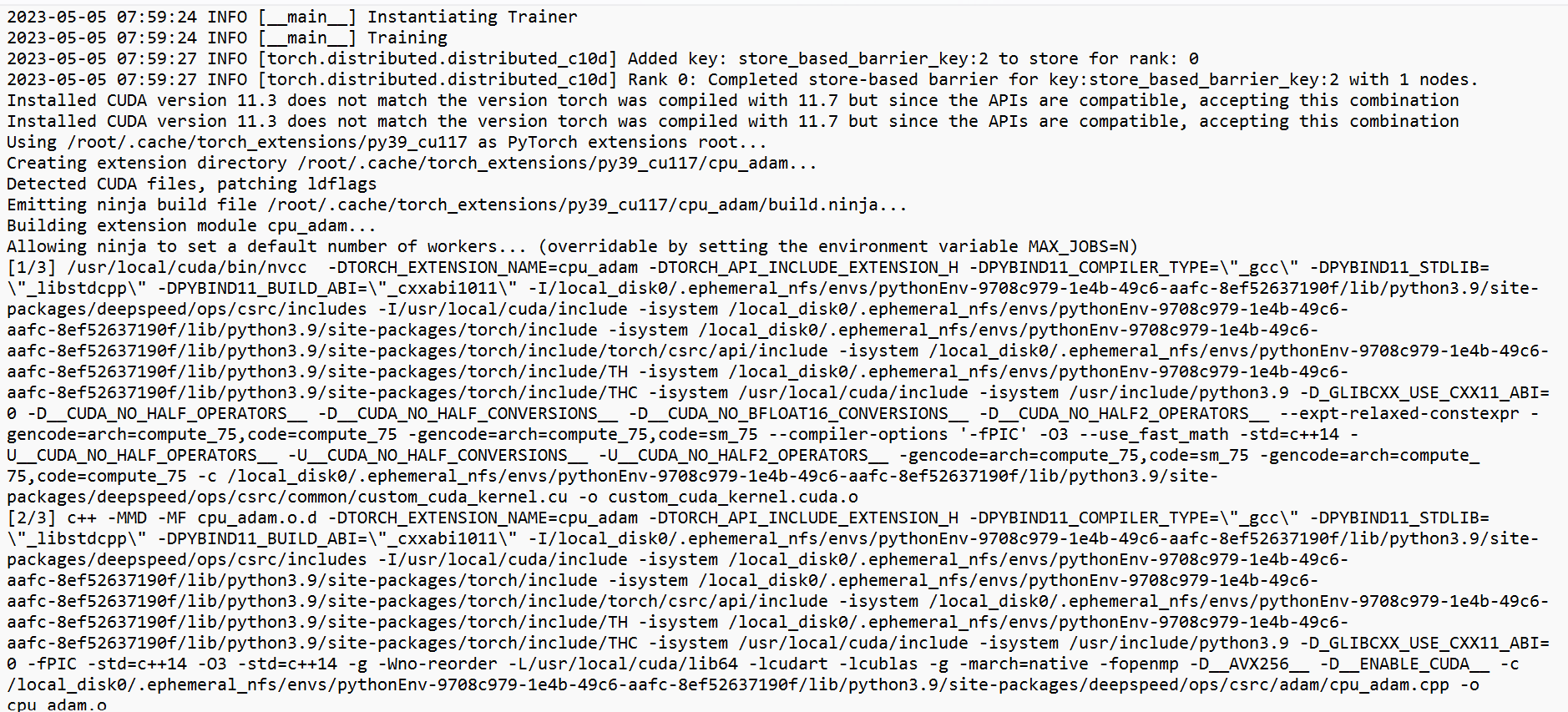
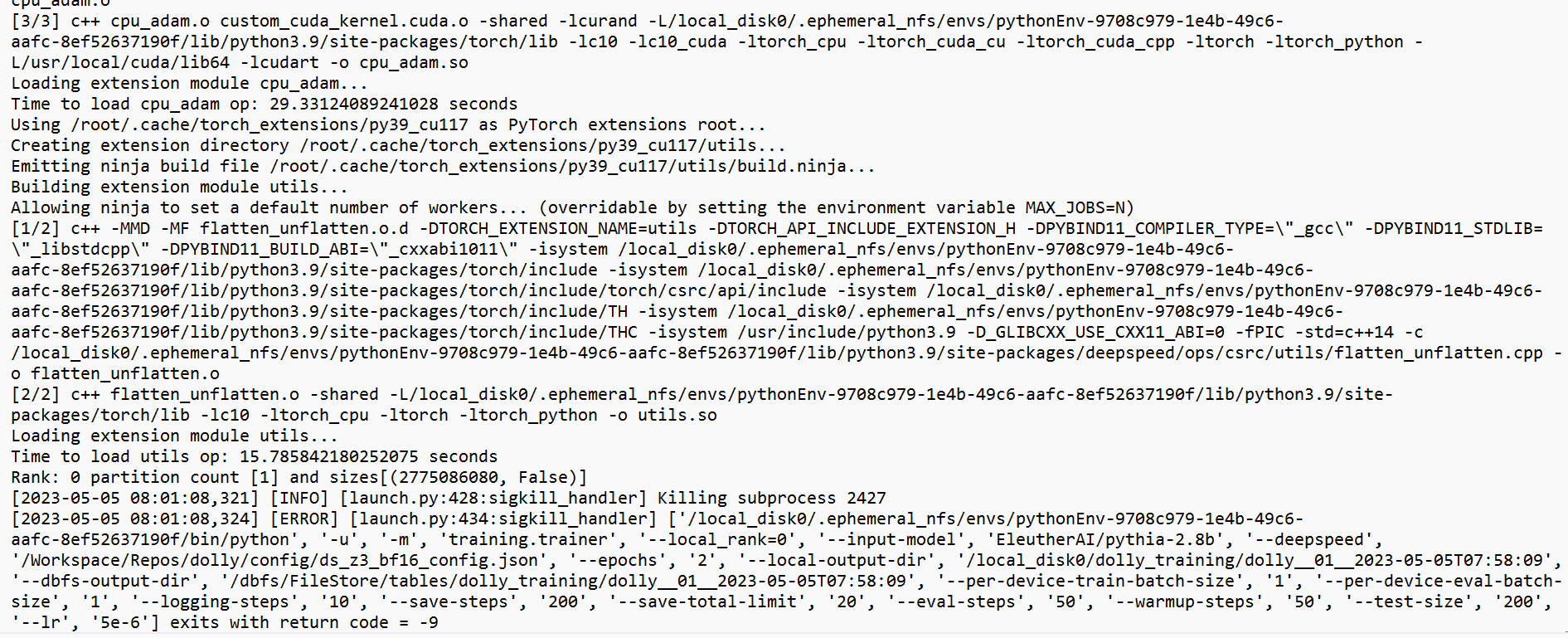
Describe the bug I started running deepseed config on EleutherAI/pythia-2.8b model, I ran into error exits with run code= -9. After splitting and preprocessing the dataset i am getting [ERROR] [launch.py:434:sigkill_handler].
Log output
I used train_dolly.py to launch the application in databricks repo..
Expected behavior I am not understanding the error or the info is mentioning in the output.
deepseed config
{
"bf16": {
"enabled": "auto"
},
"optimizer": {
"type": "AdamW",
"params": {
"lr": "auto",
"betas": "auto",
"eps": "auto",
"weight_decay": "auto"
}
},
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": "auto",
"warmup_max_lr": "auto",
"warmup_num_steps": "auto"
}
},
"zero_optimization": {
"stage": 2,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"overlap_comm": true,
"contiguous_gradients": true,
"sub_group_size": 1e9,
"reduce_bucket_size": "auto",
"stage3_prefetch_bucket_size": "auto",
"stage3_param_persistence_threshold": "auto",
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9,
"stage3_gather_16bit_weights_on_model_save": true
},
"gradient_accumulation_steps": "auto",
"gradient_clipping": "auto",
"steps_per_print": 2000,
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"wall_clock_breakdown": false
}
Screenshots
System info (please complete the following information):
- 1 GPU with 56GB
- Databricks runtime 11.3
- Python version 3.9
Additional context Please let me know what is the issue and [info] tells in the screenshots.
[2023-05-05 13:33:53,831] [INFO] [launch.py:428:sigkill_handler] Killing subprocess 754 [2023-05-05 13:33:53,866] [ERROR] [launch.py:434:sigkill_handler] ['/usr/bin/python3', '-u', 'run_clm.py', '--local_rank=0', '--deepspeed', 'ds_config_stage3.json', '--model_name_or_path', 'decapoda-research/llama-7b-hf', '--train_file', 'train.csv', '--validation_file', 'validation.csv', '--do_train', '--do_eval', '--fp16', '--overwrite_cache', '--evaluation_strategy=steps', '--output_dir', 'finetuned', '--num_train_epochs', '1', '--eval_steps', '20', '--gradient_accumulation_steps', '128', '--per_device_train_batch_size', '1', '--use_fast_tokenizer', 'False', '--learning_rate', '5e-06', '--warmup_steps', '10', '--save_total_limit', '1', '--save_steps', '20', '--save_strategy', 'steps', '--load_best_model_at_end=True', '--block_size=176', '--report_to=wandb'] exits with return code = -9 root@e60d0a05d3ea:/workspace/finetuning_repo# i ma facing similar issues when i am trying to initiate my training on llms any help in this regard.