[REQUEST] Disable zero stage2 all_gather‘s bucketing
It seems that zero stage2 can never overlap all_gather with computation at the end of each step.
Bucketing the all_gather only makes it slower, and eats more GPU memory.
@li-yi-dong, can you please share a bit more details of this issue? It would be helpful to share the model, scripts, and log snippets. Thanks.
@li-yi-dong, can you please share a bit more details of this issue? It would be helpful to share the model, scripts, and log snippets. Thanks.
Hi @tjruwase
I'm training a GPT model with Megatron-DeepSpeed, using zero stage2.
Here is the timeline with default all_gather bucketing strategy:
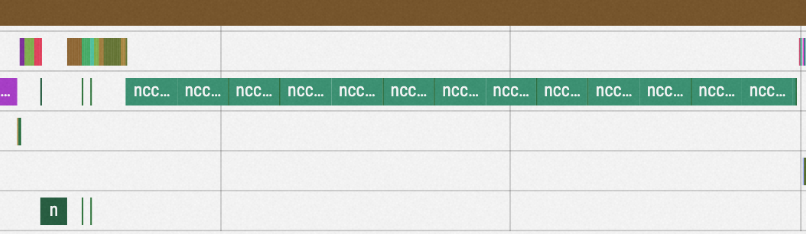 The default bucket size is 5e8, and the all_gather at the end of each step takes around 2.6 seconds.
The default bucket size is 5e8, and the all_gather at the end of each step takes around 2.6 seconds.
I manually set bucket size to 5e10, which is sufficiently large to disable bucketing:
 The all_gather reduces to 1.4 seconds.
The all_gather reduces to 1.4 seconds.
Besides, the default bucket size, 5e8, consumes more GPU memory. By setting the bucket size to 1e10, I'm able to train with larger batch size without CUDA OOM.