[BUG] step3 AssertionError: --{actor,critic}_gradient_checkpointing and --only_optimizer_lora cannot be enabled at the same time.
Describe the bug A clear and concise description of what the bug is.
To Reproduce Steps to reproduce the behavior:
- Command/Script to reproduce
- What packages are required and their versions
- How to run the script. official scripts
python3 train.py --step 3 --actor-model 1.3b --reward-model 350m
Expected behavior A clear and concise description of what you expected to happen.
ds_report output
Please run ds_report to give us details about your setup.
ds_report
--------------------------------------------------
DeepSpeed C++/CUDA extension op report
--------------------------------------------------
NOTE: Ops not installed will be just-in-time (JIT) compiled at
runtime if needed. Op compatibility means that your system
meet the required dependencies to JIT install the op.
--------------------------------------------------
JIT compiled ops requires ninja
ninja .................. [OKAY]
--------------------------------------------------
op name ................ installed .. compatible
--------------------------------------------------
async_io ............... [NO] ....... [OKAY]
cpu_adagrad ............ [NO] ....... [OKAY]
cpu_adam ............... [NO] ....... [OKAY]
fused_adam ............. [NO] ....... [OKAY]
fused_lamb ............. [NO] ....... [OKAY]
quantizer .............. [NO] ....... [OKAY]
random_ltd ............. [NO] ....... [OKAY]
sparse_attn ............ [NO] ....... [OKAY]
spatial_inference ...... [NO] ....... [OKAY]
transformer ............ [NO] ....... [OKAY]
stochastic_transformer . [NO] ....... [OKAY]
transformer_inference .. [NO] ....... [OKAY]
utils .................. [NO] ....... [OKAY]
--------------------------------------------------
DeepSpeed general environment info:
torch install path ............... ['/lib/python3.9/site-packages/torch']
torch version .................... 1.12.0
deepspeed install path ........... ['/lib/python3.9/site-packages/deepspeed']
deepspeed info ................... 0.9.0+0b5252b, 0b5252b, master
torch cuda version ............... 11.6
torch hip version ................ None
nvcc version ..................... 11.6
deepspeed wheel compiled w. ...... torch 1.12, cuda 11.6
Screenshots
If applicable, add screenshots to help explain your problem.

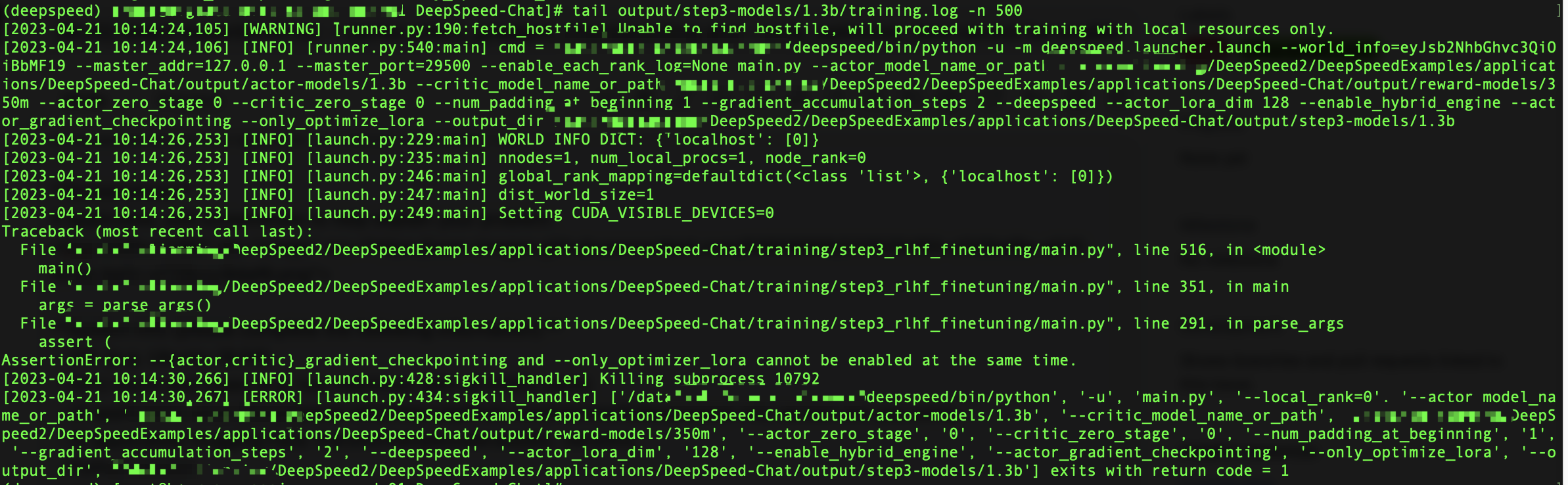 if delete --only_optimizer_lora or --only_optimize_lora
there will be OOM
if I add
if delete --only_optimizer_lora or --only_optimize_lora
there will be OOM
if I add
--per_device_train_batch_size 4 \
--per_device_eval_batch_size 4 \
in step3 shell scripts there will be can not recognize "per_device_*_batch_size"
so what should I Do to deal with it ? System info (please complete the following information):
- OS: [e.g.centOs 7.9]
- GPU count and types .4* Tesla V100-PCIE.
- (if applicable) what DeepSpeed-MII version are you using
- (if applicable) Hugging Face Transformers/Accelerate/etc. versions
- Python version 3.9.16
- Any other relevant info about your setup
Docker context Are you using a specific docker image that you can share? No Additional context Add any other context about the problem here. No
the source code have write that "gradient_checkpointing" and "only_optimize_lora" cannot be used at the same time. so you can decrease the size of batch or delete only_optimize_lora