[BUG] `TrainSchedule` seems to use one more buffer than what's needed
I believe that TrainSchedule, which implements the synchronous 1F1B pipeline training schedule, uses one more buffer than what is actually needed in every pipeline stage except for the last.
https://github.com/microsoft/DeepSpeed/blob/d323abd80f62bebb9924bb85feb72b57c25af50d/deepspeed/runtime/pipe/schedule.py#L243-L247
- Imagining a 4-stage pipeline with 8 microbatches, the first stage will do four forward computations and then one backward computation. So thinking in the high level, it should need only four buffers to remember the activations for the first four forward passes. However,
num_pipe_bufferswill return5for such a case (self.stages == 4,self.stage_id == 0, andself.microbatches == 8). - In any case, the largest value of
self.stage_idisself.stages - 1. Thus,buffersis never smaller than 2. However, this function currently returnsmax(2, buffers), which hints a one-off mistake.maxing with 2 itself makes sense because the last stage, which only has at most one in-flight microbatch and theoretically only needs one buffer, actually needs two buffers in order forsendandrecvto not deadlock or overwrite to each other.
Changing to the following, training should run well in theory.
def num_pipe_buffers(self):
buffers = min(self.stages - self.stage_id, self.micro_batches)
return max(2, buffers)
However, it dies with an assertion error triggered here
https://github.com/microsoft/DeepSpeed/blob/d323abd80f62bebb9924bb85feb72b57c25af50d/deepspeed/runtime/pipe/engine.py#L1032
which is part of _exec_send_grads and ensures that intermediate activations from the previous stage in the 'input' buffer has the .grad attribute, which are the Jacovian-vector products produced by _exec_backward_pass.
Why does this happen? Inspecting the PipeInstructions generated by the modified TrainSchedule class for the penultimate stage (self.stage_id == 2 where self.stages == 4 and self.microbatches == 8):
>>> pprint(list(FixBufferTrainSchedule(8, 4, 2)), width=120)
[[-1],
[-2],
[0, RecvActivation(buffer_id=0), ForwardPass(buffer_id=0)],
[-1, SendActivation(buffer_id=0)],
[1, RecvActivation(buffer_id=1), ForwardPass(buffer_id=1)],
[0, SendActivation(buffer_id=1), RecvGrad(buffer_id=0), BackwardPass(buffer_id=0)],
[2, RecvActivation(buffer_id=0), SendGrad(buffer_id=0), ForwardPass(buffer_id=0)], # WRONG!
[1, SendActivation(buffer_id=0), RecvGrad(buffer_id=1), BackwardPass(buffer_id=1)],
[3, RecvActivation(buffer_id=1), SendGrad(buffer_id=1), ForwardPass(buffer_id=1)],
[2, SendActivation(buffer_id=1), RecvGrad(buffer_id=0), BackwardPass(buffer_id=0)],
[4, RecvActivation(buffer_id=0), SendGrad(buffer_id=0), ForwardPass(buffer_id=0)],
[3, SendActivation(buffer_id=0), RecvGrad(buffer_id=1), BackwardPass(buffer_id=1)],
[5, RecvActivation(buffer_id=1), SendGrad(buffer_id=1), ForwardPass(buffer_id=1)],
[4, SendActivation(buffer_id=1), RecvGrad(buffer_id=0), BackwardPass(buffer_id=0)],
[6, RecvActivation(buffer_id=0), SendGrad(buffer_id=0), ForwardPass(buffer_id=0)],
[5, SendActivation(buffer_id=0), RecvGrad(buffer_id=1), BackwardPass(buffer_id=1)],
[7, RecvActivation(buffer_id=1), SendGrad(buffer_id=1), ForwardPass(buffer_id=1)],
[6, SendActivation(buffer_id=1), RecvGrad(buffer_id=0), BackwardPass(buffer_id=0)],
[8, SendGrad(buffer_id=0)],
[7, RecvGrad(buffer_id=1), BackwardPass(buffer_id=1)],
[9, SendGrad(buffer_id=1)],
[8, ReduceTiedGrads(), ReduceGrads(), OptimizerStep()]]
The integers (-1, -2, 0, -1, ...) in front of the list in each line is the current microbatch number for each step. I hacked the source code to better visualize.
See the line that says # WRONG!, where RecvActivation is performed on buffer 0, which is holding the gradients produced by the previous BackwardPass(buffer_id=0) in the previous step. I believe this is overwriting the buffer and thus buffer.grad would be None, triggering an assertion error.
This also means that when generating the instructions, all the buffer_ids in the # WRONG! step was 0. This means that prev_buffer and curr_buffer were both 0.
https://github.com/microsoft/DeepSpeed/blob/d323abd80f62bebb9924bb85feb72b57c25af50d/deepspeed/runtime/pipe/schedule.py#L198-L201
This happens because the number of buffers returned by the fixed num_pipe_buffers method is 2, and it coincides with the distance of the previous and current microbatch ids (specifically 0 and 2). Thus, merely taking the modulo (in self._buffer_idx) with 2 results in the same buffer id 0. With the current (suspectedly wrong) num_pipe_buffers, we would take the modulo of 3, which pretty much "solves" this buffer overlap issue.
https://github.com/microsoft/DeepSpeed/blob/d323abd80f62bebb9924bb85feb72b57c25af50d/deepspeed/runtime/pipe/schedule.py#L105-L117
I suspect that it's not right to derive the buffer id from the previous and current microbatch; it may need to take the step number into account, for example.
Ideally I wanted to submit a PR that fixes this, but the logic in TrainSchedule was really complex and I couldn't just fix this quickly, and I also wanted to ask whether this "extra buffer" observation even makes sense. While this is touching a chunk of code that worked well for three years and may be a convoluted task, I still believe it's worth fixing (if it's actually wrong), because at the core of DeepSpeed is ZeRO, which is a technique that trades off performance for memory efficiency.
CC @ShadenSmith
Hello @jaywonchung, thank you for your very detailed report.
I think you are right. We should remove +1 from num_pipe_buffers as you proposed.
I could also reproduce the error after the change.
I found that RecvActivation followed by SendGrad overwrites the buffer.
I thought the basic strategy of scheduling order should be send -> recv to prevent the buffer from being overwritten. The order is implemented in TrainSchedule and I tried to switch the order of RecvActivation and SendGrad there.
Now it looks working properly with a simple model, but I think we need to take some time to test with more examples.
@ShadenSmith I would appreciate it if you could give us any suggestions.
Hi @tohtana :)
Maybe you meant this, but I think what's happening is RecvActivation(buffer_id=0) for writing to self.pipe_buffers['input'][0], thereby removing the tensors that hold the gradients (Jacobian-vector products) produced by BackwardPass(buffer_id=0) in the previous step (because the tensors in self.pipe_buffers['input'][0] gets overwritten). So none of the tensors in self.pipe_buffers['input'][0] will have gradients (.grad), which the following SendGrad(buffer_id=0) expects.
All in all, I don't think this is a P2P communication ordering problem but rather a buffer management problem. RecvActivation should have instead been directed to buffer_id=1 in order to avoid overwriting the tensors that hold gradients.
EDIT: Wrong
Manually fixing three lines would look like:
>>> pprint(list(FixBufferTrainSchedule(8, 4, 2)), width=120)
[[-1],
[-2],
[0, RecvActivation(buffer_id=0), ForwardPass(buffer_id=0)],
[-1, SendActivation(buffer_id=0)],
[1, RecvActivation(buffer_id=1), ForwardPass(buffer_id=1)],
[0, SendActivation(buffer_id=1), RecvGrad(buffer_id=0), BackwardPass(buffer_id=0)],
- [2, RecvActivation(buffer_id=0), SendGrad(buffer_id=0), ForwardPass(buffer_id=0)],
- [1, SendActivation(buffer_id=0), RecvGrad(buffer_id=1), BackwardPass(buffer_id=1)],
- [3, RecvActivation(buffer_id=1), SendGrad(buffer_id=1), ForwardPass(buffer_id=1)],
+ [2, RecvActivation(buffer_id=1), SendGrad(buffer_id=0), ForwardPass(buffer_id=1)],
+ [1, SendActivation(buffer_id=1), RecvGrad(buffer_id=0), BackwardPass(buffer_id=0)],
+ [3, RecvActivation(buffer_id=1), SendGrad(buffer_id=0), ForwardPass(buffer_id=1)],
...
But I never manually tested whether this works, though.
@jaywonchung Thank you for your quick reply.
I confirmed that RecvActivation(buffer_id=0) updated self.pipe_buffers['inputs'][buffer_id] once I fixed num_pipe_buffers(). The new value does not have .grad and is not even the one computed from the desired microbatch. Is my understanding correct?
My idea was that we should send the grad before RecvActivation updates self.pipe_buffers['inputs'][buffer_id]. I don't still understand what the problem is with this idea.
For better understanding, let me also discuss the order you manually changed. Regarding this line,
+ [2, RecvActivation(buffer_id=1), SendGrad(buffer_id=0), ForwardPass(buffer_id=1)],
If you run RecvActivation(buffer_id=1) here, doesn't it also overwrite the self.pipe_buffers['inputs'][1] before BackwardPass(buffer_id=1) and SendGrad(buffer_id=1)?
The buffer management and scheduling are very complicated. I would appreciate it if you could clarify a little more.
I confirmed that
RecvActivation(buffer_id=0)updatedself.pipe_buffers['inputs'][buffer_id]once I fixednum_pipe_buffers(). The new value does not have.gradand is not even the one computed from the desired microbatch. Is my understanding correct?
Yep! That's consistent with my understanding.
My idea was that we should send the grad before
RecvActivationupdatesself.pipe_buffers['inputs'][buffer_id]. I don't still understand what the problem is with this idea.
I probably just didn't immediately get what the resulting schedule would be. AFAIK switching the order of a P2P communication pair (RecvActivation and SendGrad) will require one to also switch an adjacent stage's corresponding P2P communication pair (SendActivation and RecvGrad) for these communication primitives to not deadlock. Did you already take care of this?
For better understanding, let me also discuss the order you manually changed. Regarding this line,
+ [2, RecvActivation(buffer_id=1), SendGrad(buffer_id=0), ForwardPass(buffer_id=1)],If you run
RecvActivation(buffer_id=1)here, doesn't it also overwrite theself.pipe_buffers['inputs'][1]beforeBackwardPass(buffer_id=1)andSendGrad(buffer_id=1)?
Right, I see your point. Receiving the activations for microbatch 2 into buffer 1 will discard states for microbatch 1, which is yet to perform BackwardPass and SendGrad.
Seems like I already forgot a lot of the details of this issue over the past week XD
Oh I see. Putting RecvGrad in front of SendActivation is not a problem, because RecvGrad actually doesn't write to self.pipe_buffers but rather self.grad_layer, and the output buffer ID is only used to figure out the tensor sizes to expect. So swappingRecvActivation with SendGrad and SendActivation with RecvGrad will do the trick. This is probably what you meant, isn't it?
@jaywonchung Yes, that is what I meant.
As you mentioned, I think data in the buffer should be safe even if you switch the order of the "Instructions". I tried to visualize the matching of instructions on stage 1 and 2 (4 stages in total) after switching the order of the instructions.
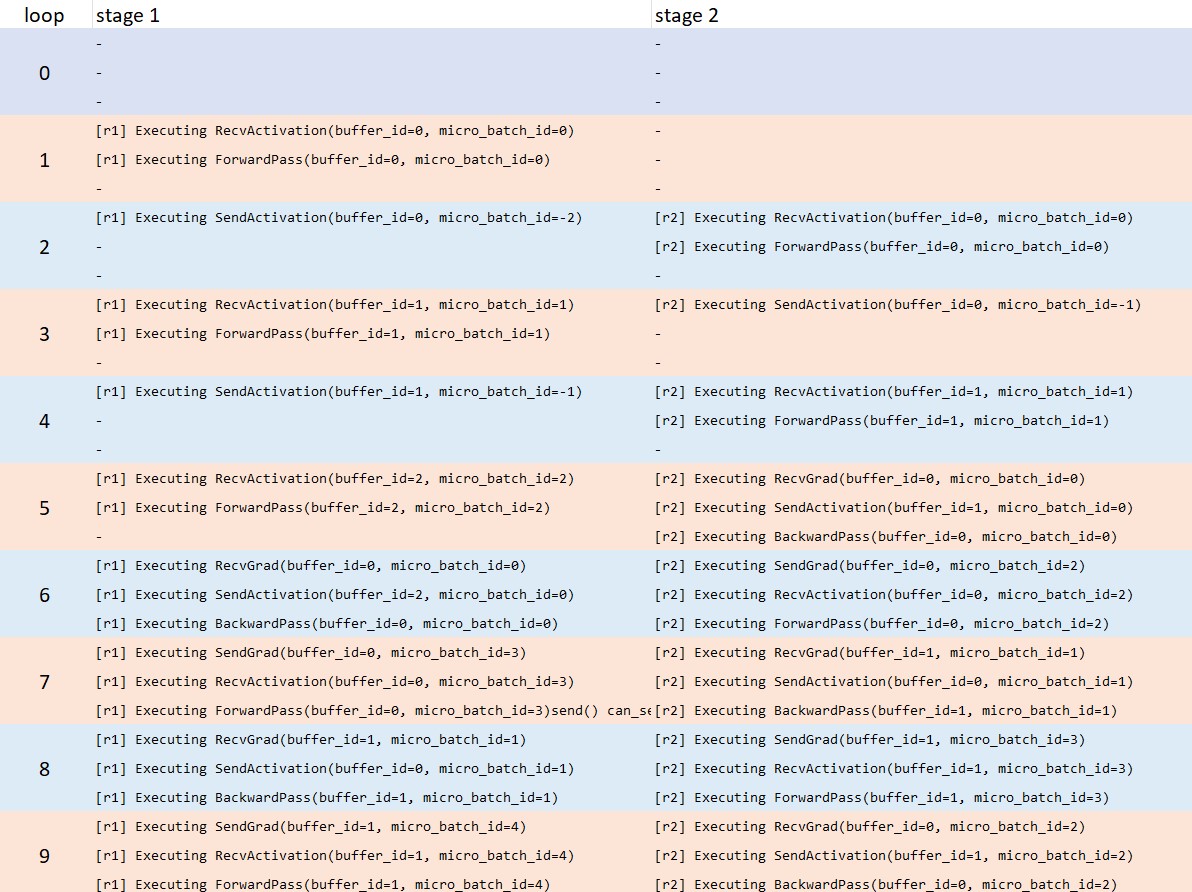
All the recv/send match and data in the buffers looks also safe in this table.
ForwardPass runs soon after RecvActivation. SendActivation runs between RecvGrad and BackwardPass, but it doesn't destroy the buffer for the backward pass.
I appreciate if you could give me any inputs for this. I think we need to test it with some more examples.
The schedule looks good to me. Probably you can try out the alexnet example in DeepSpeedExamples with a fixed random seed and compare the loss value before and after the fix. Also, I believe using DP/ZeRO degree >= 2 and/or running Megatron-DeepSpeed (if it uses the same PipeSchedule class) would be worth testing.
I personally do not have the bandwidth at the moment to do these myself.
Hi @jaywonchung,
Thank you for your suggestion.
I compared loss values using AlexNet example in DeepSpeedExamples.
I tested partitioning into 1 (no partitioning), 2, 4 stages (AlexNet was too small for 4 stages, so I added a few layers).
I didn't see a significant difference in loss values.
ZeRO disabled:
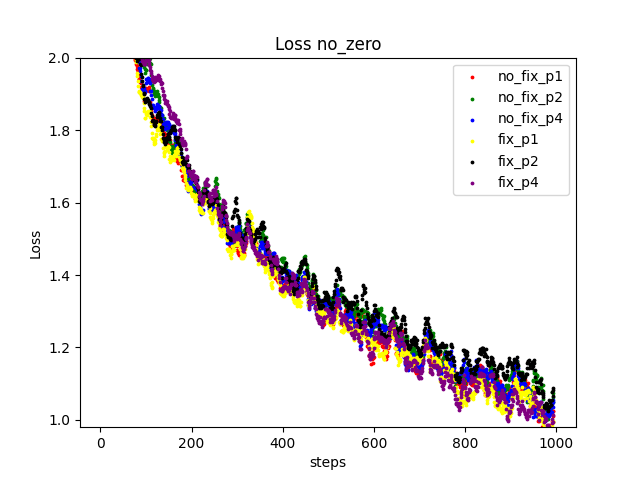
ZeRO 1:

The pipeline engine does not support ZeRO2 and 3. I will allso try with Megatron-DeepSpeed.
Thank you for running these!
My understanding is that all computation inputs and outputs should be bit-level equivalent before and after the fix, and thus for every training step, the loss value should be bitwise identical (as opposed to no significant difference). What do you think?
@jaywonchung Good question! I agree with you on that point.
In fact, I ran the program several times with the same setting. I set the same seed and the flag to use deterministic algorithms as shown below, but still observed the fluctuation of loss values regardless of the fix.
random.seed(args.seed)
np.random.seed(args.seed)
torch.manual_seed(args.seed)
torch.use_deterministic_algorithms(True)
Dropout shouldn't affect when the number of stages is the same. NCCL may not guarantee reproducibility, but the 4-stage settings do not use DP (here I used 4 GPUs in total).
I am wondering if I should see what happens with the non-pipeline version.
Regarding determinism, I think the following piece of code can be helpful. I'm not sure if DeepSpeed already has a helper for enabling training determinism, but if it doesn't, I think it should (which is due a separate issue/PR). And yeah, since we're not doing any AllReduce (but only P2P), I also think NCCL wouldn't be introducing non-determinism here.
https://github.com/huggingface/transformers/blob/7f1cdf18958efef6339040ba91edb32ae7377720/src/transformers/trainer_utils.py#L58-L97
@jaywonchung Thank you for the information!
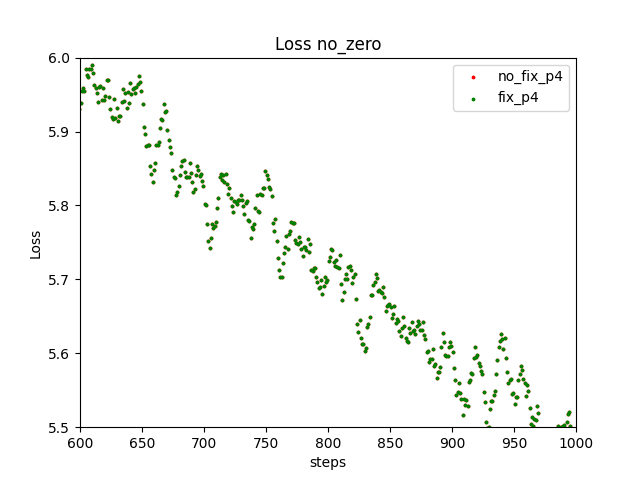
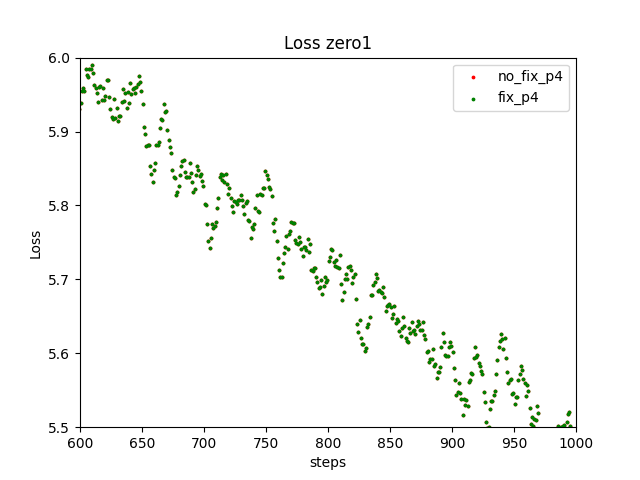
I found that my settings for reproducibility didn't properly work and used the code you mentioned. (I needed to remove the pooling layer in AlexNet because it doesn't support deterministic algorithm) Finally I observed the loss values exactly match. In the following figure, the plots resulting from the same number of stages overlap.
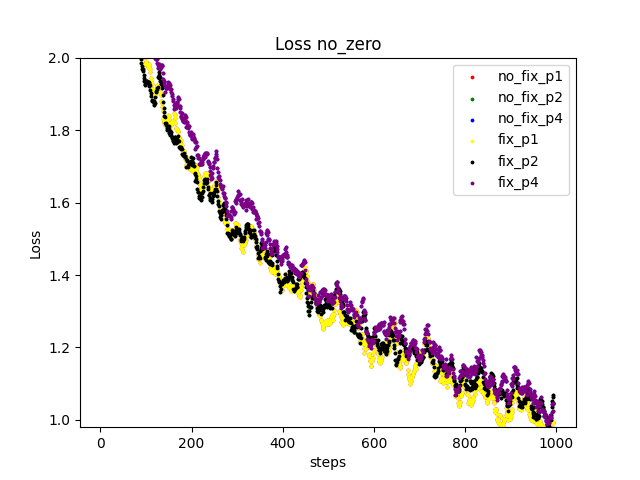
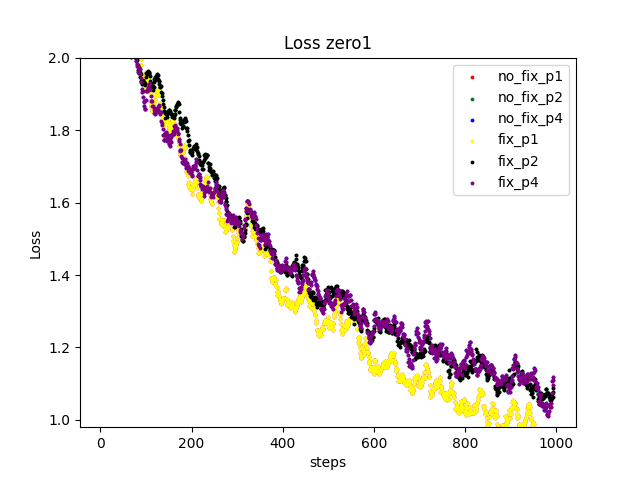
The different numbers of stages lead the different values because the RNG for dropout runs different times. This shouldn't be a problem.
@jaywonchung @ShadenSmith
I also checked with Megatron-DeepSpeed (GPT, 165M parameter) and confirmed that the loss values exactly match. The following figures show the loss values resulting from 4 stages.
I will submit the PR for the fix. Thank you @jaywonchung again for your great help!
@jaywonchung , thanks so much for this fantastic find!! Great work, findings, and report; we super appreciate it!