[BUG] DeBERTa has bad performance when using ZERO Stage-3 with continuous warnings "A module has unknown inputs or outputs type"
Describe the bug DeBERTa has bad performance when using ZERO Stage-3 . stdout has continuous warnings
[stage3.py:104:_apply_to_tensors_only] A module has unknown inputs or outputs type (<class
'torch.nn.parameter.Parameter'>) and the tensors embedded in it cannot be detected. The ZeRO-3 hooks designed to trigger before
or after backward pass of the module relies on knowing the input and output tensors and therefore may not get triggered proper
ly.
To Reproduce Steps to reproduce the behavior:
- Official HF Accelerate
run_glue_no_trainer.pyscript - Setting up DeepSpeed Zero-3 theough command
accelerate config. The output config yaml:
compute_environment: LOCAL_MACHINE
deepspeed_config:
gradient_accumulation_steps: 1
offload_optimizer_device: none
zero_stage: 3
distributed_type: DEEPSPEED
fsdp_config: {}
machine_rank: 0
main_process_ip: null
main_process_port: null
main_training_function: main
mixed_precision: fp16
num_machines: 1
num_processes: 2
use_cpu: false
- bash script to run the finetuning of
microsoft/deberta-v2-xlarge-mnlion MRPC dataset using ZERO Stage-3.
#!/bin/bash
time accelerate launch /home/sourab/deepspeed-test/src/text-classification/run_glue_no_trainer.py \
--task_name "mrpc" \
--max_length 128 \
--model_name_or_path "microsoft/deberta-v2-xlarge-mnli" \
--output_dir "/home/sourab/deepspeed-test/glue/mrpc_deepspeed_stage3_accelerate" \
--per_device_train_batch_size 16 \
--per_device_eval_batch_size 16 \
--gradient_accumulation_steps 1 \
--learning_rate 3.5e-6 \
--weight_decay 0.0 \
--max_grad_norm 1.0 \
--num_train_epochs 6 \
--num_warmup_steps 50 \
--with_tracking \
- Relevant output snippets. The first one shows the weird behaviour with continuous warnings. The second shows the eval metrics being worse when compared to setup without using DeepSpeed.


Expected behavior A clear and concise description of what you expected to happen. No contiguous stream of warnings and no performance degradation when using DeepSpeed Stage-3 with DeBERTa.
ds_report output
Please run ds_report to give us details about your setup.
-------------------------------------------------- [0/1948]
DeepSpeed C++/CUDA extension op report
--------------------------------------------------
NOTE: Ops not installed will be just-in-time (JIT) compiled at
runtime if needed. Op compatibility means that your system
meet the required dependencies to JIT install the op.
--------------------------------------------------
JIT compiled ops requires ninja
ninja .................. [OKAY]
--------------------------------------------------
op name ................ installed .. compatible
--------------------------------------------------
cpu_adam ............... [NO] ....... [OKAY]
cpu_adagrad ............ [NO] ....... [OKAY]
fused_adam ............. [NO] ....... [OKAY]
fused_lamb ............. [NO] ....... [OKAY]
[WARNING] please install triton==1.0.0 if you want to use sparse attention
sparse_attn ............ [NO] ....... [NO]
transformer ............ [NO] ....... [OKAY]
stochastic_transformer . [NO] ....... [OKAY]
async_io ............... [NO] ....... [OKAY]
utils .................. [NO] ....... [OKAY]
quantizer .............. [NO] ....... [OKAY]
transformer_inference .. [NO] ....... [OKAY]
--------------------------------------------------
DeepSpeed general environment info:
torch install path ............... ['/home/sourab/dev/lib/python3.8/site-packages/torch']
torch version .................... 1.12.0.dev20220505+cu113
torch cuda version ............... 11.3
torch hip version ................ None
nvcc version ..................... 10.2
deepspeed install path ........... ['/home/sourab/dev/lib/python3.8/site-packages/deepspeed']
deepspeed info ................... 0.6.4, unknown, unknown
deepspeed wheel compiled w. ...... torch 1.12, cuda 11.3
Screenshots If applicable, add screenshots to help explain your problem.
System info (please complete the following information):
- OS: Ubuntu 20.04.3 LTS (Focal Fossa)
- GPU count and types: 1 machine with x2 NVIDIA TITAN RTX each
- Python version: Python 3.8.10
Launcher context
Are you launching your experiment with the deepspeed launcher, MPI, or something else?
Accelerate launcher which just triggers deepspeed launcher
Very interesting. I have never seen such behavior before.
I wasn't part of the Deepspeed integration at accelerate so you probably need to ask there.
The HF Trainer integration works just fine with deberta-v2, though I only tested with mlm - but it should work with classification just as well, please see the test here: https://github.com/huggingface/transformers/blob/3601aa8fc9c85cc2c41acae357532ee3b267fb9a/tests/deepspeed/test_model_zoo.py#L196
Also you're running pt-nightly - I wonder if this is something new in pytorch? Does it work with pt-1.11?
Hello Stas, Thank you for the information. I observe it with trainer too. Steps to reproduce the behaviour with trainer:
- Official
run_glue.pyscript with the following change. The change is required because we are using DeBERTa-V2 XLarge model finetuned on MNLI (3 output classes) to finetune on MRPC task (2 output classes). This is inline with official DeBERTa experiment script mrpc.sh to get best performance.
model = AutoModelForSequenceClassification.from_pretrained(
model_args.model_name_or_path,
from_tf=bool(".ckpt" in model_args.model_name_or_path),
config=config,
cache_dir=model_args.cache_dir,
revision=model_args.model_revision,
- use_auth_token=True if model_args.use_auth_token else None
+ use_auth_token=True if model_args.use_auth_token else None,
+ ignore_mismatched_sizes=True,
)
- Below ZERO Stage-3 Config
zero3_config.json:
{
"fp16": {
"enabled": "auto",
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
},
"optimizer": {
"type": "AdamW",
"params": {
"lr": "auto",
"betas": "auto",
"eps": "auto",
"weight_decay": "auto",
"torch_adam": true,
"adam_w_mode": true
}
},
"scheduler": {
"type": "WarmupDecayLR",
"params": {
"warmup_min_lr": "auto",
"warmup_max_lr": "auto",
"warmup_num_steps": "auto",
"total_num_steps": "auto"
}
},
"zero_optimization": {
"stage": 3,
"overlap_comm": true,
"contiguous_gradients": true,
"sub_group_size": 1e9,
"reduce_bucket_size": "auto",
"stage3_prefetch_bucket_size": "auto",
"stage3_param_persistence_threshold": "auto",
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9,
"stage3_gather_16bit_weights_on_model_save": true
},
"gradient_accumulation_steps": "auto",
"gradient_clipping": "auto",
"steps_per_print": 2000,
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"wall_clock_breakdown": false
}
- bash script to run the finetuning of
bert-base-uncasedon MRPC dataset using ZERO Stage-3.
#!/bin/bash
time torchrun --nproc_per_node=2 run_glue.py \
--task_name "mrpc" \
--max_seq_len 128 \
--model_name_or_path "microsoft/deberta-v2-xlarge-mnli" \
--output_dir "./glue/mrpc_deepspeed_stage3_trainer" \
--overwrite_output_dir \
--do_train \
--evaluation_strategy "epoch" \
--per_device_train_batch_size 16 \
--per_device_eval_batch_size 16 \
--gradient_accumulation_steps 1 \
--learning_rate 3.5e-6 \
--weight_decay 0.0 \
--max_grad_norm 1.0 \
--num_train_epochs 6 \
--lr_scheduler_type "linear" \
--warmup_steps 50 \
--logging_steps 100 \
--fp16 \
--fp16_full_eval \
--optim "adamw_torch" \
--report_to "wandb" \
--deepspeed "zero3_config.json"
Also you're running pt-nightly - I wonder if this is something new in pytorch? Does it work with pt-1.11
Yes, this is on pt-nightly. However, I believe it has something to do with DeepSpeed itself based on the warnings. I might be wrong but it would be worthwhile to wait for someone from DeepSpeed team to guide us on this. Will test it out with pt-1.11.
@pacman100, we made some recent changes to ZeRO 3, so I wonder if those are source of regression. Could you please try v0.6.0?
Hello @tjruwase, Getting below error with v0.6.0:
Traceback (most recent call last):
File "/home/sourab/deepspeed-test/src/text-classification/run_glue_no_trainer.py", line 619, in <module>
main()
File "/home/sourab/deepspeed-test/src/text-classification/run_glue_no_trainer.py", line 511, in main
accelerator.backward(loss)
File "/home/sourab/accelerate/src/accelerate/accelerator.py", line 616, in backward
self.deepspeed_engine.backward(loss, **kwargs)
File "/home/sourab/accelerate/src/accelerate/utils/deepspeed.py", line 50, in backward
self.optimizer.backward(loss)
File "/home/sourab/test/lib/python3.8/site-packages/deepspeed/utils/nvtx.py", line 11, in wrapped_fn
return func(*args, **kwargs)
File "/home/sourab/test/lib/python3.8/site-packages/deepspeed/runtime/zero/stage3.py", line 2793, in backward
self.loss_scaler.backward(loss.float(), retain_graph=retain_graph)
File "/home/sourab/test/lib/python3.8/site-packages/deepspeed/runtime/fp16/loss_scaler.py", line 53, in backward
scaled_loss.backward(retain_graph=retain_graph)
File "/home/sourab/test/lib/python3.8/site-packages/torch/_tensor.py", line 363, in backward
torch.autograd.backward(self, gradient, retain_graph, create_graph, inputs=inputs)
File "/home/sourab/test/lib/python3.8/site-packages/torch/autograd/__init__.py", line 173, in backward
Variable._execution_engine.run_backward( # Calls into the C++ engine to run the backward pass
RuntimeError: Given normalized_shape=[1536], expected input with shape [*, 1536], but got input of size[0]
@pacman100, thanks for the update. So, you see a totally different error with old release :(. Let's ignore the old release then. I will work on setting up a repro on my side. In the meantime, can you please check if the accuracy issue shows up on single GPU using the latest release? Thanks!
Hello @tjruwase , I tried rerunning using the latest release with multiple and single GPU(s) setup. I don't observe accuracy issue anymore (above might have used different DeBERTa pretrained checkpoint with deepspeed). Below are the plots for finetuning microsoft/deberta-v2-xlarge-mnli on MRPC dataset using 2 GPUs.
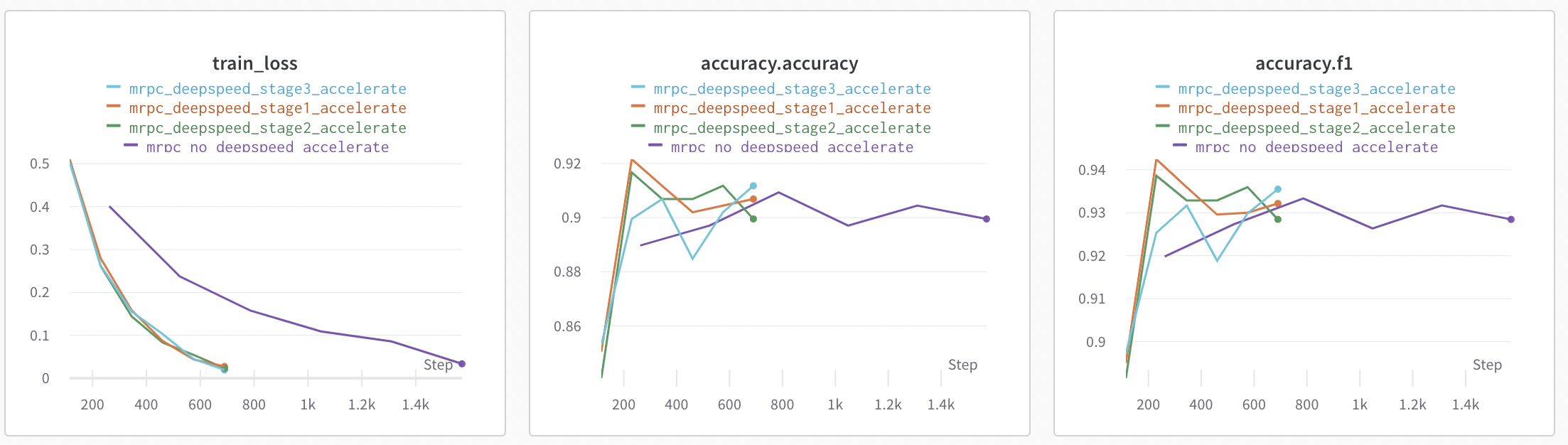
However, I still keep getting the endless logs of the below warnings :
[stage3.py:104:_apply_to_tensors_only] A module has unknown inputs or outputs type (<class
'torch.nn.parameter.Parameter'>) and the tensors embedded in it cannot be detected. The ZeRO-3 hooks designed to trigger before
or after backward pass of the module relies on knowing the input and output tensors and therefore may not get triggered proper
ly.
Therefore, the expected behaviour now is to not have these continuous warnings when using Zero Stage-3.
@pacman100, thanks for sharing your update. I am glad that performance problem is resolved in the latest code. I have created this #1974 to suppress the warning noise. The PR probably needs tweaking such as whether to report this warning some fixed number of times. Right now, it is complete turned off except for debugging mode. Can you please test the PR branch?
Hello @tjruwase, Thank you for the fix 😄! Yes, the above PR is working as expected to suppress the warnings.
Like @pacman100 I'm getting good performance with Stage3 training (using a similar setup), but also getting these really concerning warnings:
[WARNING] [parameter_offload.py:55:_apply_to_tensors_only] A module has unknown inputs or outputs type (....) and the tensors embedded in it cannot be detected. The ZeRO-3 hooks designed to trigger before or after backward pass of the module relies on knowing the input and output tensors and therefore may not get triggered properly.
Is there any documentation of ZeRO-3 hooks and how it is that one is suppose to specify the input and output tensors?
You redacted the type from the warning - was it nn.Parameter? If so it has been fixed here: https://github.com/microsoft/DeepSpeed/pull/2642 The fix will work for any tensor.Torch subclass.
If it's another type you can add your voice here https://github.com/microsoft/DeepSpeed/issues/2658 while depicting your concrete situation, since my request was abstract.
Thanks for the response. Ah, yes, I redacted the type because it wouldn't make sense, it's a custom dataclass that holds a bunch of tensors (it's the output of some tensor pooling function). I'll have a closer look at #2658 .
Fantastic. I'm glad you presented a concrete case - actually may be a new Issue would be better since mine is abstract and mentions several unrelated issues in one so it's more likely to be not dealt with.
I'm really interested in understanding of what deepspeed should do, but definitely not skip the backward call!
I wonder if it should check whether the tensor in question has requires_grad==False and then it'd be safe to skip. let's discuss in your Issue if you tag me there please and thank you!
Hi again @stas00, perhaps before I make an issue we can quickly check if this is an issue to be discussed in the context of pytorch-lightning (which is what I am using together with deepspeed).
I made a silly example below that shows the issue:
import torch ### 1.9.1 with Cuda 11.1
from torch.utils.data import DataLoader, Dataset
from pytorch_lightning import LightningModule, Trainer ### using 1.7.7
from pytorch_lightning.callbacks import ModelCheckpoint
from dataclasses import dataclass,field,asdict
class A:
pass
def my_collator(batch):
return {
"data" : torch.stack(batch,dim=0),
"batch_meta_data" : [A(),A()],
"other_stuff" : [[[10],[]]] ## built-in stuff
}
class RandomDataset(Dataset):
def __init__(self, size, length):
self.len = length
self.data = torch.randn(length, size)
def __getitem__(self, index):
return self.data[index]
def __len__(self):
return self.len
class BoringModel(LightningModule):
def __init__(self):
super().__init__()
self.layer = torch.nn.Linear(32, 2)
def forward(self, features):
x = features["data"]
return self.layer(x)
def training_step(self, batch, batch_idx):
loss = self(batch).sum()
self.log("train_loss", loss,batch_size=2)
return {"loss": loss}
def validation_step(self, batch, batch_idx):
loss = self(batch).sum()
self.log("valid_loss", loss,batch_size=2)
def test_step(self, batch, batch_idx):
loss = self(batch).sum()
self.log("test_loss", loss,batch_size=2)
def configure_optimizers(self):
return torch.optim.SGD(self.layer.parameters(), lr=0.1)
if __name__ == "__main__":
train_data = DataLoader(RandomDataset(32, 64), batch_size=2,collate_fn=my_collator)
val_data = DataLoader(RandomDataset(32, 64), batch_size=2,collate_fn=my_collator)
model = BoringModel()
trainer = Trainer(
num_sanity_val_steps=0,
max_epochs=3,
log_every_n_steps=1,
strategy="deepspeed_stage_3",
precision=16,
accelerator="gpu",
devices=1,
)
trainer.fit(model, train_dataloaders=train_data, val_dataloaders=val_data)
this gives me the warning:
[2023-01-04 17:36:20,111] [WARNING] [parameter_offload.py:55:_apply_to_tensors_only] A module has unknown inputs or outputs type (<class '__main__.A'>) and the tensors embedded in it cannot be detected. The ZeRO-3 hooks designed to trigger before or after backward pass of the module relies on knowing the input and output tensors and therefore may not get triggered properly.
because I have this non-built-in/non-tensor thing (batch_meta_data) in the batch representation.
my specific issue: I sometimes put such custom objects (here simulated by this custom object A() and [[[10],[]]]) alongside my batch tensors for on-the-fly analysis, integration with other models, and a whole host of other complicated things. I still don't understand what's going in with _apply_to_tensors_only, but my guess is that it should probably skip these things once it establishes that it has nothing to do with tensors, like it seems to do with built-in objects.
It's very helpful to see the code - thank you, @yakazimir
This definitely has nothing to do with PL and it's a pure DS <-> end user model issue.
OK, so in this particular case clearly the object in question has no need in backprop and it's not even a torch.Tensor.
Do you have any cases where you have objects that contain members that are (1) tensors and (2) require backprop?
Now back to your specific example. I think it'd be good for a user to establish a clear understanding of types of objects that require no backprop and communicate that to deepspeed. And thus prevent this confusing warning from being issued in the first place.
So for example I'd propose to extend deepspeed.initialize to include a new flag classes_to_ignore_for_backprop, so in your case it'd be:
... = deepspeed.initialize(..., classes_to_ignore_for_backprop=[A])
now that this declaration has been done, _apply_to_tensors_only could lookup the type of outputs and if it matches the above class do nothing.
If it encounters a class it doesn't know about it could assert with now actionable message like this:
encountered an object of type XYZ that is not a
torch.Tensorsubclass and we don't know how to backprop on it.
- If the object contains no tensors that require backprop (require_grads==False) please register the name of its class via the
classes_to_ignore_for_backproparg ofdeepspeed.initialize.- If it contains tensors that require grads either: (a) provide a method to access those tensors or (b) break up the object into smaller objects so that the tensors are standalone objects and then those no-tensor containing objects should be added to
classes_to_ignore_for_backprop- see (1) above.
So the more advanced design would require the user to include a method get_tensors_requiring_grads in their proprietary classes and then _apply_to_tensors_only could check if hasattr(outputs, "get_tensors_requiring_grads") and call it to extract such tensors and backprop on those.
This is one possible actionable and clarity bringing solution that I came up with. Surely, there are others.
@jeffra, what do you think about this approach?
For this case involving batches with additional information, yes, it's never the case that I have objects with tensors inside or anything else that involve backprop, but I wouldn't want to entirely rule this out. So I think your classes_to_ignore_for_backprop idea is very sensible to also make users mindful of this issue, and this would be easy to integrate into my current pipeline.
Just a clarification: in its current form, is this anything more than a warning? Is it actually breaking something? (it doesn't seem to be, since my model is training just fine, but I see that some outputs are still getting returned in this branch of the _apply_to_tensors_only function)
There was, however, a different case through which I first encountered this issue, below is a simulation of this (I fixed it, because it was a pretty awful design for other reasons, but it might relate to something more general). Apologies for how rough this is:
class ClassifierModel(nn.module):
def __init__(self,....):
self.layer = torch.linear(....)
...
def forward(self,custom_object):
if some_condition:
rep = custom_object.first_tensor
else:
rep = custom_object.second_tensor
return self.layer(rep)
class MainModel(nn.module):
def __init__(self...):
self.classifier = ClassifierModel(....)
self.transformer_model = ....
def forward(self,features):
input_features = features["input_ids"]
encoder_out = self.transformer_model(input_features,...)
custom_obj_w_pooled_tensors = some_pooling_function(encoder_out)
classifier_out = self.classifier(custom_obj_w_pooled_tensors)
....
here it complains about the custom_obj_w_pooled_tensors, which is a dataclass holding a bunch of tensors that the classifier decides how to use. These types of dataclasses seem to be pretty common in existing libraries for passing around groups of tensors, so I suspect that there is something more general about this.
I was thinking for this case: perhaps you could force users to use iterable classes and check these for tensors (rather than just tuples or lists, which the current code seems to do).
Your code snippet is perfect, @yakazimir. I just can't see that custom object, but I assume that its tensors didn't have requires_grad=False. If they did then there is no problem.
So, yes, that seems like the situation where a grad requiring tensor is hidden inside an opaque object.
... since my model is training just fine ...
Is it though? have you checked that those tensors received grads and thus contributed to the learning?
That's the thing with DL - often everything seems to work despite possibly having multiple issues that are quite hidden from the user's awareness.
For example if you miss some backprops your training could take (1) longer to train (2) your design is compromised since some tensors don't contribute to the backprop dance. Yet it will still train and may even appear to be quite successful.
Not to appear an alarmist here, just sharing from my experience where more than once everything looked just fine and only thanks to divergence or sometimes a pure accidental discovery that various subtle problems were discovered.
Thanks. These are tensors that receive grads, yes, this has been checked. (Like I mentioned, this is a terrible design that was fixed before and that doesn't make a lot of sense, but it might reveal something more general about custom objects with tensors). In terms of my broader deepspeed integration, I am able to match the performance of my single gpu version, which has been more thoroughly tested, debugged, and compared against more established training pipelines (I’m not doing anything too out of the ordinary here), so I am fairly confident that it’s working properly in spite of these warnings (similar to what’s reported earlier in this thread by other users).