DeepSpeed
 DeepSpeed copied to clipboard
DeepSpeed copied to clipboard
ZERO Stage 3 with NVME Offload very slow
When running ZERO Stage 3 with NVME offload on a 10B parameter model, I am observing roughly 2.3 TFLOPS/GPU (whereas we expect to see closer to 30-40 TFLOPS/GPU for v100 GPUs, which we do when using ZERO Stage 2).
Potentially related to pre-fetching problems seen in https://github.com/microsoft/DeepSpeed/issues/1069
Method to reproduce is: https://gist.github.com/stephenrawls/1d396fe3f3c63ec1dc7edf85747503e5
we havent been updating this issue, but we were seeing the same issues even after optimizations to stage3 discussed in https://github.com/microsoft/DeepSpeed/issues/1069 and trying to figure out why (optimizations: https://github.com/jfc4050/DeepSpeed/tree/stage3)
i think i found the biggest (there's other smaller factors) culprit
with the blocking HtoD copy. note the cudaStreamSynchronize calls. The tensors are in pinned memory and i dont think we need to block the python process on the copies as long as the allgathers are still blocked on them
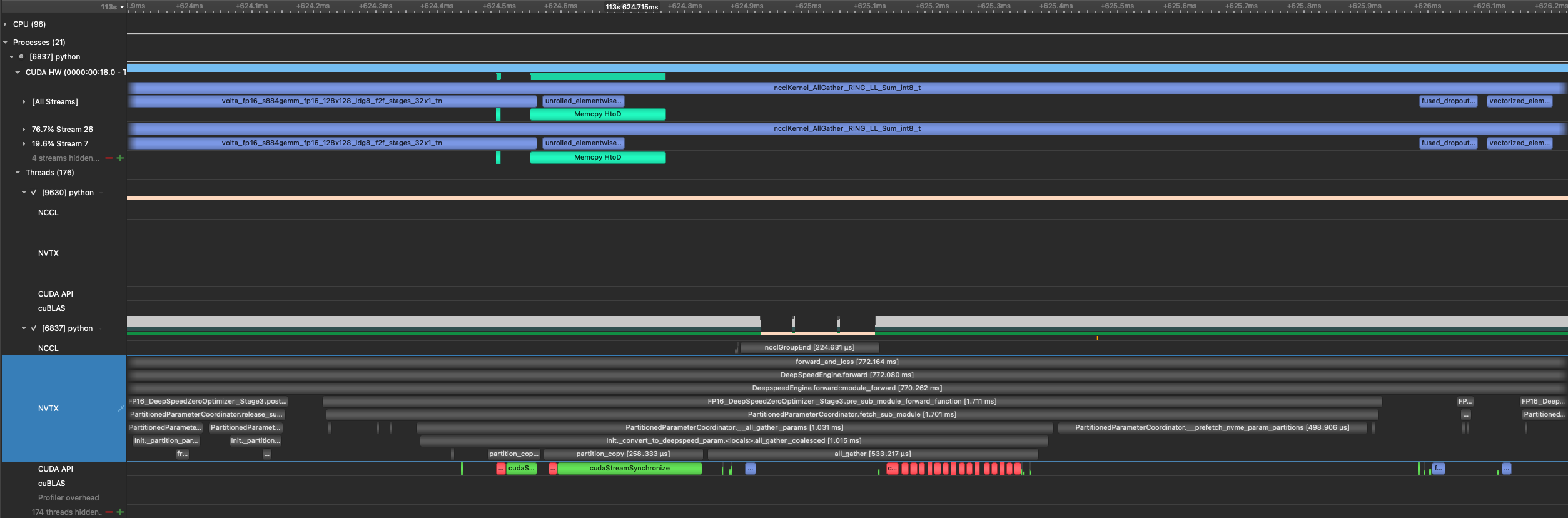
with non-blocking HtoD copy (commit for the fix https://github.com/jfc4050/DeepSpeed/commit/0d1ac060a26cf155b55be82305caf0f76b5f2cd4)
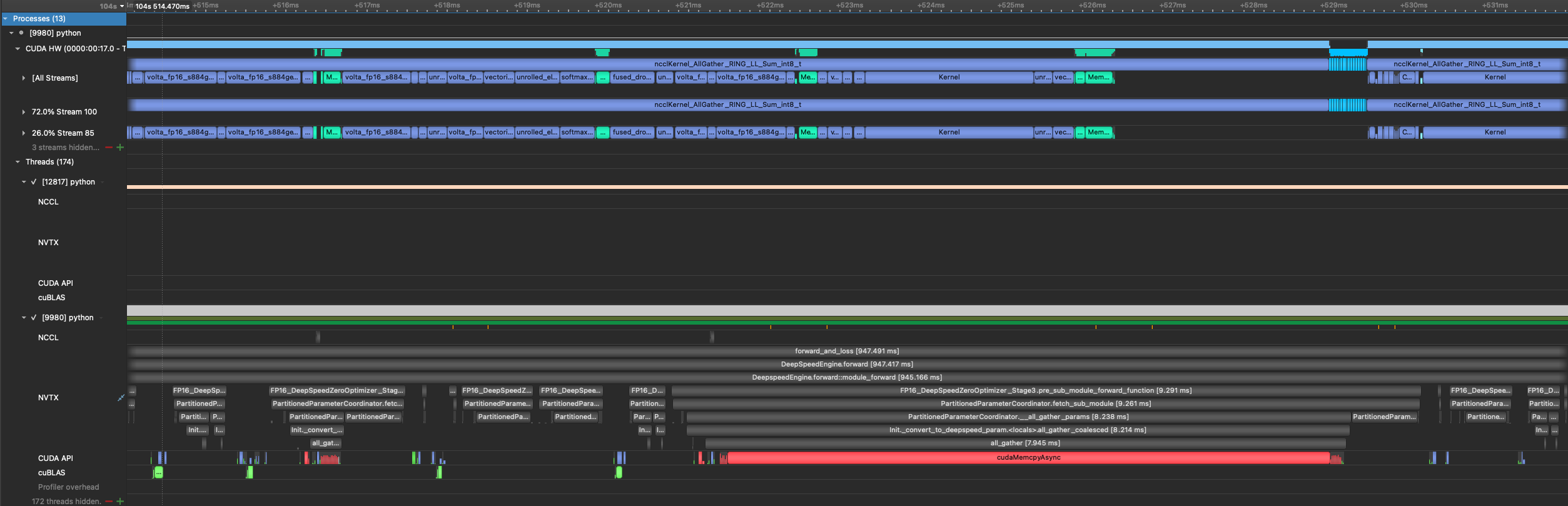
i havent fully verified correctness yet, but based on behavior when there is no prefetching, seems like it is fine to make the copy non-blocking
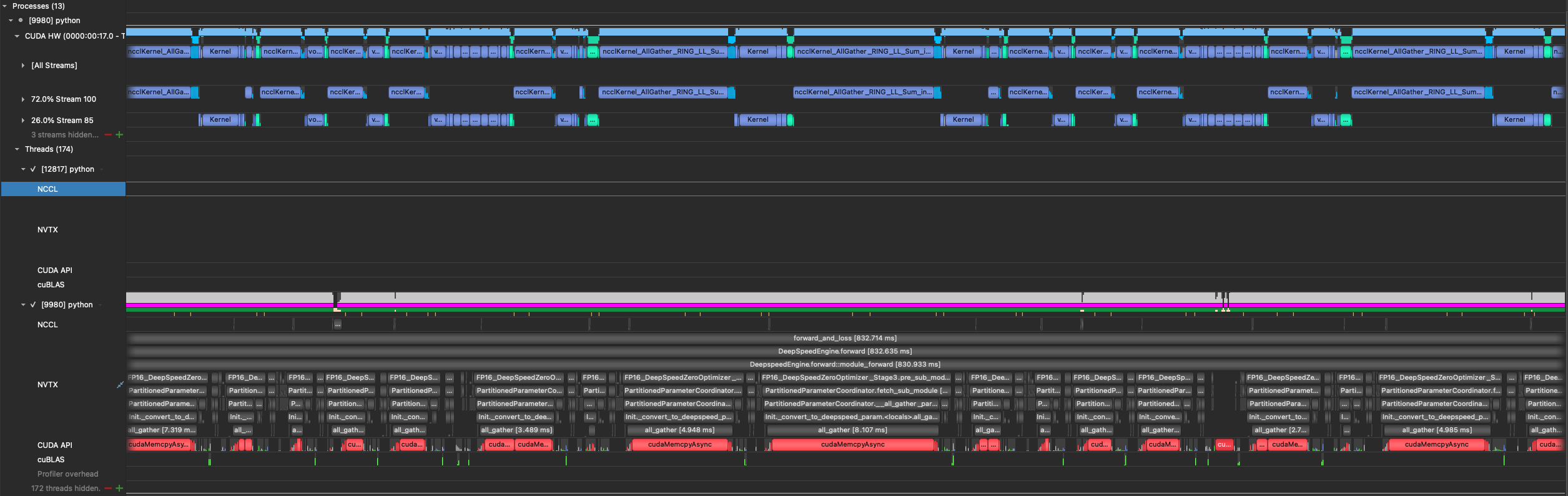
getting 21.75 TFLOPS/GPU (single p3dn) after the fix
@jfc4050, thanks for sharing this update. Are you doing NVMe offload as well similar to the original post?
@tjruwase yes results were with NVMe offload (optimizer states and params). here's the full config
ds_config = {
"wall_clock_breakdown": False,
"train_micro_batch_size_per_gpu": 8,
"gradient_accumulation_steps": 1,
"gradient_clipping": 1.0,
"fp16": {"enabled": True},
"zero_optimization": {
"stage": args.zero_stage,
"overlap_comm": True,
"contiguous_gradients": True,
"reduce_bucket_size": 1.5e8,
"allgather_bucket_size": 1.5e8,
"stage3_max_live_parameters": 1e9,
"stage3_param_persistence_threshold": 1e3,
"offload_optimizer": {
"device": "nvme",
"nvme_path": "/ssd1",
"pin_memory": False,
},
"offload_param": {
"device": "nvme",
"nvme_path": "/ssd1",
"pin_memory": False,
},
},
"activation_checkpointing": {
"partition_activations": False,
"contiguous_memory_optimization": False,
"number_checkpoints": 50,
"cpu_checkpointing": False,
"profile": True,
},
"optimizer": {
"type": "Adam",
"params": {
"lr": 1e-4,
"betas": [0.9, 0.95],
"eps": 1e-8,
"weight_decay": 0.1,
},
},
}
@butterluo, unfortunately this thread went cold almost 2 years ago. The code has changed substantially. Can you please open a new issue and share your experience? Thanks!