meton-robean
meton-robean
### 设备连接图 
既然在研究堵车的原因,那么三种假设就是堵车的三种解释,也就是酒驾,高峰和车祸,先验概率是假设的概率,也就是字面意思,在任何更多的证据前(也就是堵车),预先估计的,不同的假设本身出现的概率。在这里就是P(酒驾),P(高峰)和P(车祸)。 似然概率的含义是,在几种假设前提下,出现该证据的概率,也就是P(堵车|酒驾),P(堵车|高峰)和P(堵车|车祸),这个也是字面意思,就是可能性(likelihood),在不同假设下证据的可能性。这样的话,最大似然估计的意思就是最大化似然概率,说白了就是哪个解释似然概率高就是哪个解释对。也就是argmax(P(堵车|酒驾),P(堵车|高峰),P(堵车|车祸)) 这里的话,后验概率就是在证据出现的情况下,不同假设正确的概率,也就是P(酒驾|堵车),P(高峰|堵车)和P(车祸|堵车),就是P(酒驾)P(堵车|酒驾)/P(堵车),P(高峰)P(堵车|高峰)/P(堵车)和P(车祸)P(堵车|车祸)/P(堵车)。因为P(堵车)对每个假设都是一样的,那比较后验概率也就是不仅要考虑似然概率,也要考虑假设本身的先验概率。说白了就是即便这个假设肯定会导致证据这个结果,但是假设本身不太可能发生的话,我们也不认为这个假设是对的。比如这条路多少年从来没查过酒驾,那么即便一查酒驾路必堵死,我们也不会相信堵车就是查酒驾引起的。 先给出贝叶斯公式 P(H|e)=P(e|H)P(H)/P(e),H是假设(酒驾,高峰和车祸),e是证据(堵车) 先验概率是三种假设的概率P(H),P(酒驾),P(高峰)和P(车祸) 似然概率是不同假设下,出现证据的可能性P(e|H),P(堵车|酒驾),P(堵车|高峰)和P(堵车|车祸) 后验概率是证据出现后假设成立的概率P(H|e),P(酒驾|堵车),P(高峰|堵车)和P(车祸|堵车) P(堵车)只是归一化常数P(e),表示证据的概率,在比较后验时消去,只有算后验分布才有用 这样三种估计的区别也就分出来了, 最大似然估计是认为似然概率大的假设对,argmax(P(e|H)) 最大后验估计是认为后验概率大的假设对,argmax(P(H|e)) 贝叶斯估计就是不仅要知道哪个假设后验高,还要知道后验的分布,P(H|e)
[An Architectural Framework for Accelerating Dynamic Parallel Algorithms on Reconfigurable Hardware](https://cpb-us-w2.wpmucdn.com/sites.coecis.cornell.edu/dist/7/89/files/2016/08/parallelxl-micro2018-10bi0tp.pdf) [论文笔记参考](https://github.com/meton-robean/PaperNotes/issues/8) **该论文加速动态并行特性的应用,下面是这个benchmark描述**   
[Co-Designing Accelerators and SoC Interfaces using gem5-Aladdin](https://ysshao.github.io/assets/papers/shao2016-micro.pdf) **论文中使用的MachSuite,展示了大约一半左右的程序是compute-bound, 一半是memory-bound.** 
[CortexSuite: A Synthetic Brain Benchmark Suite*](http://cseweb.ucsd.edu/groups/bsg/papers/cortex-extended.pdf) **论文提出了CortexSuite包含了各类机器学习应用的C语言实现版本**[下载地址](https://bitbucket.org/taylor-bsg/cortexsuite/src/devel/) 
[XLOOP: Architectural Specialization for Inter-Iteration Loop Dependence Patterns(MICRO2014) #18](https://github.com/meton-robean/PaperNotes/issues/18) 一个发掘循环间和内并行的抽象模型以及加速器原型。 里面用到了的benchmark: 
### lacore 用的是riscv架构,和rocketchip无关,使用的是gem5的riscv模型 https://github.com/meton-robean/PaperNotes/issues/17 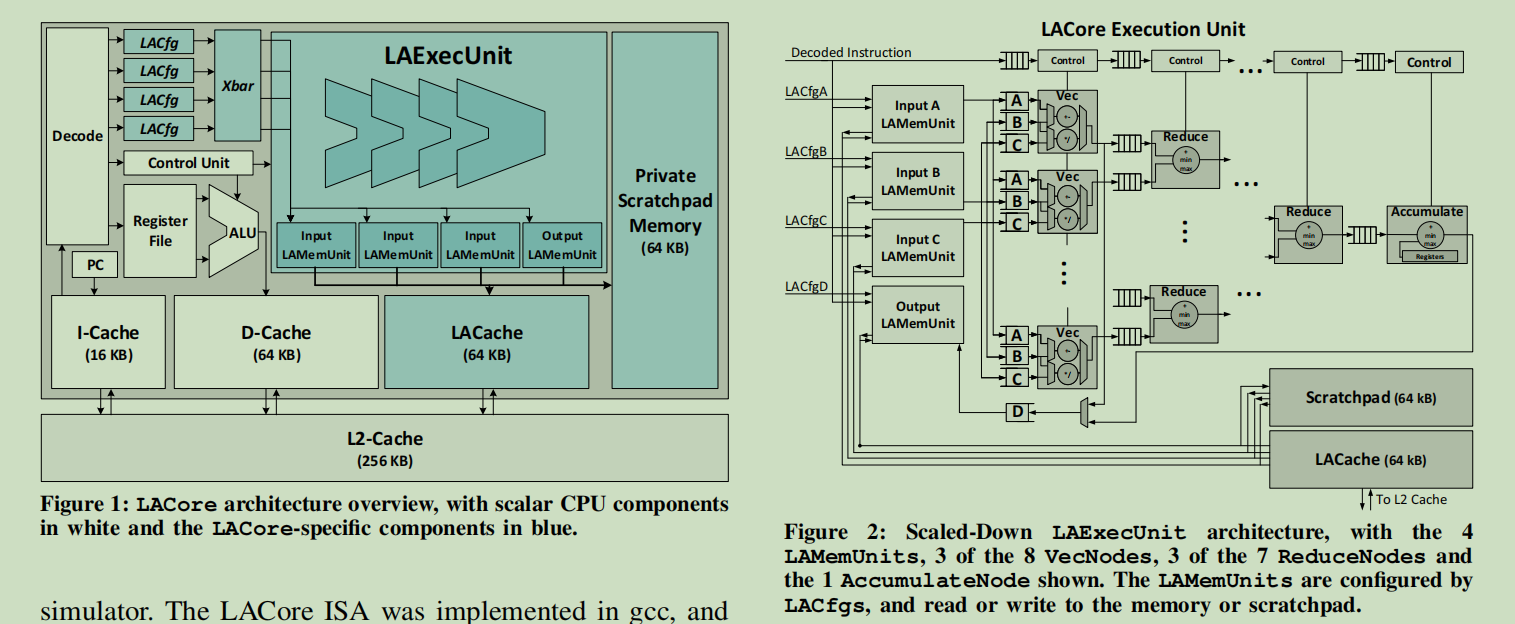
label-riscv
Hwacha 向量处理器
firesim