crnn.pytorch
 crnn.pytorch copied to clipboard
crnn.pytorch copied to clipboard
Anyone who has trained the model on dataset syth90k? Could you show the final accuracy ?
And the tricks you have tried to prove the accuracy.
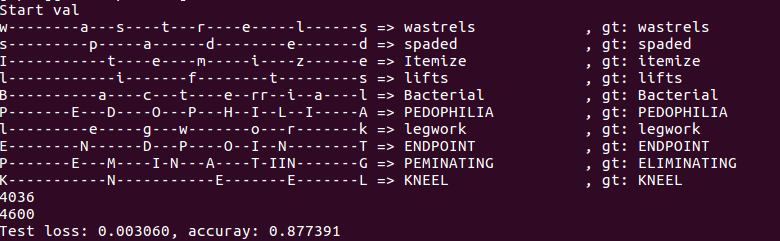 the accuracy that i achieve.
i just want to know is there any promotion can be done?
the accuracy that i achieve.
i just want to know is there any promotion can be done?
What's your test set? I try to reproduce the results of CRNN, but got really bad performance.
I create syth90k_train (about 7.2M images) and syth90k_val (about 0.8M images) using create_dataset.py from CRNN and sort the images according to their aspect ratios. The training settings are as follows:
python train.py --adadelta --cuda --random_sample --niter 250000 --workers 0
python train.py --adadelta --cuda --keep_ratio --niter 50000 --workers 0 --pretrained netCRNN_250000.pth
The validation accuracy I got:
250k iterations: 0.784 - 0.761 - 0.746 - 0.719 - 0.713
50k iterations: 0.663
Any clues?
@hzli-ucas You can print out the wrong predictions, then you can see the model can not classify uppercase i and lowercase L and so on. as long as you remove one of them, the accuracy will increase immediately.
@Fighting-JJ Not really this reason, 'cause my labels are case-insensitive, i.e. nclass = 37. Here are some examples of the wrong predictions:
s---uu-s-h--e => sushe (SUSHI ) a------n--- => an (ART ) m---------f----- => mf (ART ) m--------u--s-c--u---mm-- => muscum (MUSEUM ) m--------mm--u--m---s => mmums (MUSEUM ) n--------w--i---------s => nwis (TIMKEN ) e------------e-----n-----------rr----aa-----l---- => eenral (CENTRAL ) c------e-nn-t--r--a-ll-y => centraly (CENTRAL ) s--------t--aa---ii-oo--n------- => staion (STATION ) m------aa------s---h- => mash (MASSA ) -------e-------t------ => et (HERTZ ) c------o---u---r--ii-yy--a--rr--dd- => couriyard (COURTYARD )
I cannot see obvious regular pattern from them. Besides, the trained crnn.pth provided in this repositry got a 93% accuracy on my validation set. I have tried to finetune from it for 50k iterations, but the accuracy on val drops like: 0.872 - 0.859 - 0.860 - 0.845 - 0.826.
Do you create your own datasets? Does the author provide open source datasets ?
Do you create your own datasets? Does the author provide open source datasets ?
What's your test set? I try to reproduce the results of CRNN, but got really bad performance. I create syth90k_train (about 7.2M images) and syth90k_val (about 0.8M images) using create_dataset.py from CRNN and sort the images according to their aspect ratios. The training settings are as follows:
python train.py --adadelta --cuda --random_sample --niter 250000 --workers 0python train.py --adadelta --cuda --keep_ratio --niter 50000 --workers 0 --pretrained netCRNN_250000.pthThe validation accuracy I got: 250k iterations: 0.784 - 0.761 - 0.746 - 0.719 - 0.713 50k iterations: 0.663 Any clues?
How do you create syth90k_train and syth90k_val
@DuckJ Create the lmdb dataset with create_dataset.py in bgshih/crnn. The original text image datasets can be found here.
Do you rembmber the map_size in https://github.com/bgshih/crnn/blob/master/tool/create_dataset.py#L37 when make train lmdb, that includes 70K images. I set the map_size as 20G, but not enough
@DuckJ I've got 7,224,600 images in train set, and 22GB (map_size=2210241024*1024) will be enough. The validation set contains 802,733 images and needs 2.5GB.
Thanks. did you finally reproduce the results of the author's model? Now, I am retraining the model with a simplified network. Could you tell me the batchsize you set when training? Thank you