ebe-dataset
 ebe-dataset copied to clipboard
ebe-dataset copied to clipboard
Evidence-based Explanation Dataset (AACL-IJCNLP 2020)
Evidence-based Explanation Dataset

Overview
We present the Evidence-based Explanation Dataset, which is the largest dataset (37,280 reviews) for explaining evidences in recommending hotels for vague requests. Assuming that titles of hotel reviews often correspond to vague requests, the dataset includes hotel reviews with annotations for vague requests, evidence sentences for the requests, recommendation sentences based on the evidences. All hotel review data are extracted from Jalan, which is a travel information web site in Japan.
Data Annotation
Assuming that some review titles express vague requests and that the corresponding review texts contain evidences,
we extract vague requests from review titles and annotate evidence sentences for the requests in review texts.
Finally, we rewrite evidence sentences into recommendation sentences.
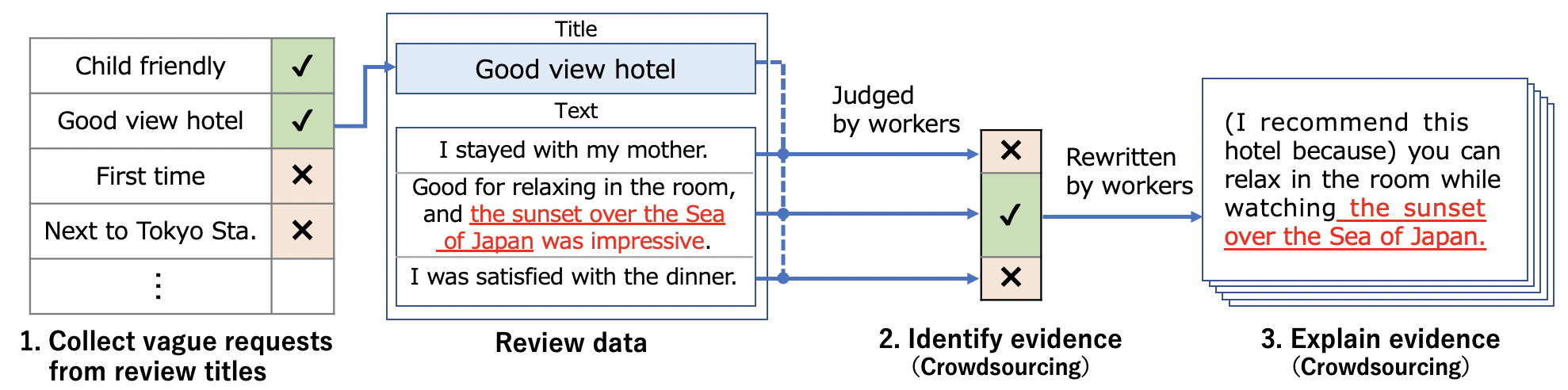 The detailed annotation guidelines for this dataset are available in the papers (en: AACL-ICLNLP2020 Kanouchi+, ja: NLP2020 Kanouchi+).
The detailed annotation guidelines for this dataset are available in the papers (en: AACL-ICLNLP2020 Kanouchi+, ja: NLP2020 Kanouchi+).
Description
org/evidence-based_explanation.json.gz is the entire dataset for Evidence-based Explanation.
evidence_identification_dataset/*. and evidence_explanation_dataset/* are evaluation dataset for Evidence Identification and Evidence Explanation, which are made from org/evidence-based_explanation.json.gz.
org/evidence-based_explanation.json.gz
- Explanation
| Key | Explanation |
|---|---|
| index (int) | ID of the example |
| title (str) | Review title (including vague requests such as "Good view") |
| review (str) | Review text |
| sent (str) | Each review sentence |
| relevance_score (float) | Ratio of the 5 workers who said that the sentence was related to the title. (0.0~1.0) |
| evidence_score (float) | Ratio of the 5 workers who said that the sentence contained the evidence for the title. (0.0 ~ 1.0) It only exists if the relevance_score is 0.6 or higher. |
| recommendation_sents (list) | Recommendation sentences. It only exists if the evidence_score is 0.6 or higher. |
| recommendation_labels (dict) | Labels and their numbers that (1) workers rewrote into recommendation sentences, (2) said the evidence (or title) is negative or (3) said no evidence for explanation. (recommendation: 0~5, negative: 0~5, no_evidence: 0~5) |
- Example
{
"index": 0,
"title": "眺望が抜群です",
"review": "建物は年季が入っていますが、私は好きです。 食事は鍋にしたのですが、ボリューム満点で少し残してしまいました。 小食の方は、少な目にした方がストレスなく頂けると思います。 部屋は2階でしたが、諏訪湖を見下ろす感じでとても気持ちよかったです。 機会があればまた行きたい宿でした。",
"review_items": [
{
"sent": "建物は年季が入っていますが、私は好きです。",
"relevance_score": 0.0
},
{
"sent": "食事は鍋にしたのですが、ボリューム満点で少し残してしまいました。",
"relevance_score": 0.0
},
{
"sent": "小食の方は、少な目にした方がストレスなく頂けると思います。",
"relevance_score": 0.0
},
{
"sent": "部屋は2階でしたが、諏訪湖を見下ろす感じでとても気持ちよかったです。",
"relevance_score": 1.0,
"evidence_score": 1.0,
"recommendation_sents": [
"諏訪湖を見下ろす感じでとても気持ちよいので、この宿がオススメです。",
"2階というそこまで高くない階に宿泊しても諏訪湖を見下ろせる眺望が抜群なので、この宿がオススメです。",
"2階だと諏訪湖を見下ろす感じがとても気持ちよいので、この宿がオススメです。",
"2階の部屋から諏訪湖を見下ろす感じで、とても気持ちいいので、この宿がオススメです。",
"2階からでも諏訪湖を見下ろす感じでとても気持ちよいので、この宿がオススメです。"
],
"recommendation_labels": {
"recommendation": 5,
"negative": 0,
"no_evidence": 0
}
},
{
"sent": "機会があればまた行きたい宿でした。",
"relevance_score": 0.0
}
]
},...
- How to use
import json
import gzip
DATASET_PATH = "/path/to/evidence-based_explanation.json.gz"
with gzip.open(DATASET_PATH, 'r') as f:
evidence_dataset = json.load(f)
evidence_identification_dataset/(train|test|dev).tsv
- This is the evaluation dataset for the Evidence Identification task.
- The target is 1 if the evidence_score is 0.6 or higher.
- Normalisation
- The titles and sentences are Unicode NFKC normalized.
- All characters are converted from half-width to full-width.
- Tokenized by jumanpp-2.0.0.
- We randomly divided the data by review into training, development, and test.
- Data size
| Reviews | Sentences | Positive (%) | |
|---|---|---|---|
| Train | 29,826 | 148,671 | 20,709 (13.9) |
| Dev | 3,726 | 18,549 | 2,606 (14.0) |
| Test | 3,728 | 18,823 | 2,489 (13.2) |
| Total | 37,280 | 186,043 | 25,804 (13.9) |
- Explanation of the (train|test|dev).tsv
| # | Explanation | Samples |
|---|---|---|
| 0 | ID of the example | 1-sent1 |
| 1 | Title (Vague request) | 景色 が 良い (Good view) |
| 2 | Sentence | 部屋 から 海 が 見え ます (You can see the ocean from your room.) |
| 3 | Target | 1 (Evidence), 0 (No evidence) |
evidence_explanation_dataset/*
- This is the evaluation dataset for the Evidence Explanation task.
- Given a title and a evidence sentence, each worker rewrote into a recommendation sentence.
-
(train|dev|test).srccontainstitle [SEP] evidence sentence. -
(train|dev|test).trgcontainsrecommendation sentence.
-
- Normalisation is the same as the evidence identification dataset.
- Data size
- Train : Dev : Test = 81,980 : 2,332 : 2,191
- Example of
evidence_explanation_dataset/(train|dev|test).src
景色 が 最高 [SEP] あと は 駐車 場 は 広くて 無料 も 助かる し 、 ホテル は 高台 に ある ので 部屋 から の 眺め も 最高でした 。
子連れ に ぴったり [SEP] 2 歳 の やんちゃな 男の子 な ので 心配でした が とても 広くて 綺麗な キッズ スペース が あり おもちゃ も 沢山で 大喜びでした 。
- Example of
evidence_explanation_dataset/(train|dev|test).trg
ホテル は 高台 に ある ので 部屋 から の 眺め も 最高な ので
とても 広くて 綺麗な キッズ スペース が あり おもちゃ も 沢山な ので
References
- Shin Kanouchi, Masato Neishi, Yuta Hayashibe, Hiroki Ouchi and Naoaki Okazaki. You May Like This Hotel Because …: Identifying Evidence for Explainable Recommendations. Proceedings of The 1st Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 10th International Joint Conference on Natural Language Processing (AACL-IJCNLP2020) pages 890-899, December 2020. [PDF]
- 叶内晨, 根石将人, 林部祐太, 岡崎直観. 旅行情報サイトのレビューを用いた抽象的な要求に対する根拠付き推薦文の生成.言語処理学会第26回年次大会 (NLP2020), pp.29–32, 2020年3月 [PDF]
Notes
-
株式会社リクルート(以下「リクルート」といいます。)は自然言語処理の研究に貢献する目的で、言語的注釈が付与されたデータセット(以下「本データセット」といいます。)を公開いたします。
-
Recruit Co., Ltd.(hereinafter referred to as "Recruit") publishes the data set with linguistic annotations (hereinafter referred to as this "Data Set") for the purpose of contributing to the study of natural language processing.
-
本データセットには、クチコミデータから抽出した文、それらを加工した文、アノテーション作業者が付与した判定ラベル、アノテーション作業者が作文した推薦文が含まれます。ラベルや推薦文は作業者によって付与されたものであり、クチコミ投稿者の体験や評価、もしくはリクルートの評価を反映したものではありません。
-
This Data Set is constructed using various methods of extraction from Customer Reviews. Annotators provide judgment via labels and recommendation sentences rewrite. Labels and recommendation sentences are provided by the cloud-sourced annotators and do not reflect the experience, assessment, or Recruit’s assessment of the review contributor.
-
事実と異なる内容が含まれる場合があります。
-
This Data Set may contain content that is contrary to the facts.
-
本データセットは通知なく変更・削除される場合があります。
-
This Data Set is subject to change or deletion without notice.
License and Attribution
-
本データセットに含まれる「じゃらんクチコミデータ」の著作権は、リクルートに帰属します。
-
The copyrights to Customer Reviews included in this Data Set belong to Recruit.
-
本データセットを用いた研究発表を行う際は、Referencesの論文を引用し、次のようにデータの入手元も記述してください。
- 文例: 本研究では株式会社リクルートが提供する"Evidence-based Explanation Dataset" (
https://github.com/megagonlabs/Evidence-based-Explanation-dataset)を利用しました。
- 文例: 本研究では株式会社リクルートが提供する"Evidence-based Explanation Dataset" (
-
When publishing a study using this dataset, please cite papers in References and describe the source of the data as follows.
- Example: To conduct this study, we used "Evidence-based Explanation dataset" (
https://github.com/megagonlabs/Evidence-based-Explanation-dataset) provided by Recruit Co., Ltd.
- Example: To conduct this study, we used "Evidence-based Explanation dataset" (
-
本データセットのライセンスはクリエイティブ・コモンズ・ライセンス (表示-非営利-継承 4.0 国際)です。
-
The license of this Data Set is in the same scope as Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International (CC BY-NC-SA 4.0).
Prohibitions
-
リクルートは本データセットを非営利的な公共利用のために公開しています。分析・研究・その成果を発表するために必要な範囲を超えて利用すること(営利目的利用)は固く禁じます。
-
Recruit discloses this Data Set for non-profit public use. It is strictly prohibited to use for profit purposes beyond the scope necessary for the presentation of analysis, research and results.
-
利用者は、研究成果の公表といえども、前項の出版物等の資料に、適正な例示の範囲を超えてデータセット中のデータを掲載してはならず、犯罪その他の違法行為を積極的に助長・推奨する内容や公序良俗に違反する情報等を記述しないでください。
-
Even when publishing research results, users should not post data in the data set beyond the appropriate exemplary range in the publications and other materials set forth in the preceding paragraph. Users should not describe information obtained from the data set that violates public order and morals, promote or encourage criminal or other illegal acts.
Contact
If you have any inquiries and/or problems about a dataset or notice a mistake, please contact NLP Data Support Team nlp_data_support at r.recruit.co.jp.
Metadata
Owner
Metadata
Evidence-based Explanation Dataset (AACL-IJCNLP 2020)