Source with working feed is not collecting (we're also not blocked)
via @AnissaPierre: The raw feeds look fine but an "invalid date" for "Last New Story" - no stories are coming in. She switched her user-agent and verified that they are not blocking us. Some of those feeds are ones in this state.
- https://sources.mediacloud.org/#/sources/300240/feeds
- https://sources.mediacloud.org/#/sources/623833/feeds
- https://sources.mediacloud.org/#/sources/329358/feeds
For instance, source 329358 has on two feeds that should be ingesting. However, they show up with a note that they haven't ever successfully fetched the RSS. However, when I visit the first one directly ([feed 1591359] (https://sources.mediacloud.org/#/sources/329358/feeds/1591359/edit)) I can see that it has content that looks fine and should be ingesting.
Is RSS parsing failing in some way? The chart of all stories over time suggests that we are a little behind on story volume, but not completely broken:
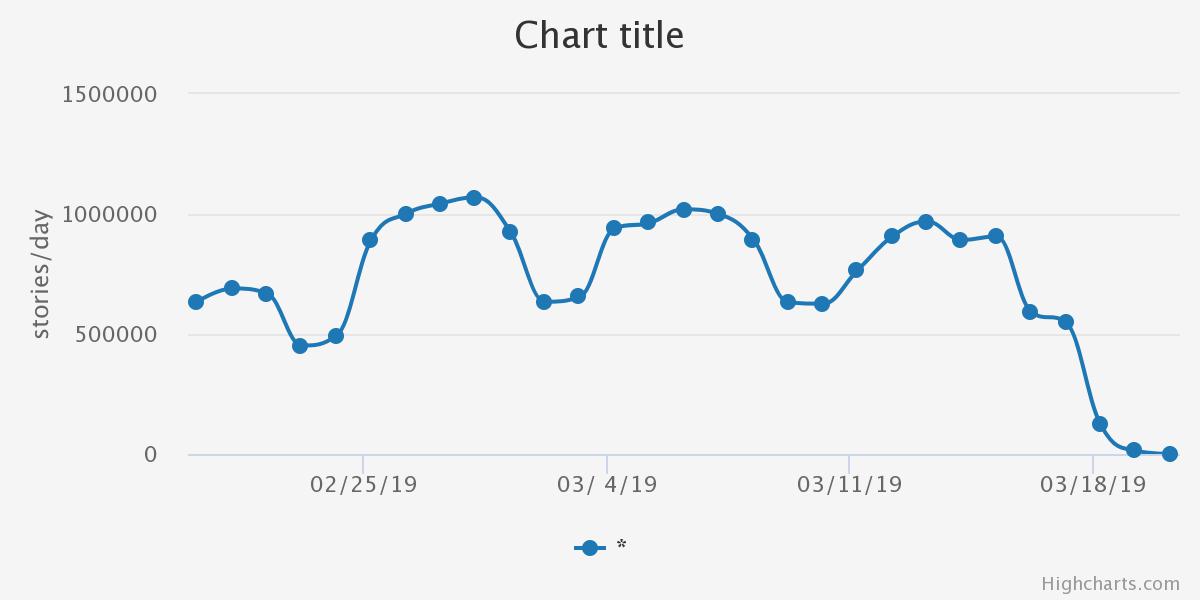
- https://sources.mediacloud.org/#/sources/300240/feeds
This one gets blocked with a 403 when I use both our agent and our from header from mccore1.
- https://sources.mediacloud.org/#/sources/623833/feeds
These are getting timed out by the crawler parent process because they are hanging around in the 'fetching' state for more than five minutes. This is sort of a last resort error detection for the crawler that just means that something went so badly wrong with the fetcher that it never got to a 'success' or 'error' state. A quick check shows that this has happened with 1839 of our most recent 1 million downloads. So worth looking at but I don't think a big priority.
For this particular source, it looks like we are getting the large majority of these feeds fine (which makes the consistent errors for a few of the feeds even weirder), but that at least means that we're getting at least most if not all of the content for that source (usually for a source with that many feeds, you only need a pretty small subset of the feeds to get all of the content).
- https://sources.mediacloud.org/#/sources/329358/feeds
Evidently my new queue scheduling is not working as well as I hoped. It looks like some new content / feeds is getting shunted into the big archive of "we'll get to it sometime in the next month or so" too quickly. That is the case with these -- they are stuck in that archive bucket. I currently put everything other than the most recent 100k downloads into the bucket. I'll try tweaking those schedule settings to be make the 'new stuff that should be gotten ASAP bucket bigger. It's a little tricky because the query to get those new downloads has to be run once a minute, so there's a tradeoff between speed and inclusiveness.
For instance, source 329358 has on two feeds that should be ingesting. However, they show up with a note that they haven't ever successfully fetched the RSS. However, when I visit the first one directly ([feed 1591359] (https://sources.mediacloud.org/#/sources/329358/feeds/1591359/edit)) I can see that it has content that looks fine and should be ingesting.
Is RSS parsing failing in some way? The chart of all stories over time suggests that we are a little behind on story volume, but not completely broken:
I have changed the crawler queue scheduling so that it now always gets exactly one download from each host, prioritizing feeds first and then the most recent content downloads. This means that each time the fetchers need a new set of things to download, the scheduler gives them a block of downloads that has exactly one download per host.
The queue currently has about 29k distinct hosts, so this means that fetching the actual stories will likely lag for a bit. The crawler can fetch about 50 things per second, so we are now only downloading one thing from each host every ten minutes or so. The old scheduler was really bad about getting hung up on large numbers of downloads from a few hosts, which means we have accumulated a lot of distinct hosts in the queue. Over the next couple of days, I think the number of distinct hosts should shrink a lot, so that we're generally downloading one thing from each host every minute or two.
Already, the 329358 source has downloaded one of its feeds, which is a good indication that this should fix the underlying problem of us dropping recent feed downloads.
Feed id 1591359 is acting odd in a related way - it says that it has downloaded and added stories recently, but they don't show up in a call to storyList.
mc.feed(1591359)
says it downloaded and added stories from today (2019-03-27):
{'active': True,
'feeds_id': 1591359,
'last_attempted_download_time': '2019-03-27 15:44:47.588440-04:00',
'last_new_story_time': '2019-03-27 15:14:24.723534-04:00',
'last_successful_download_time': '2019-03-27 15:52:47-04:00',
'media_id': 329358,
'name': 'AyoBandung.com',
'type': 'syndicated',
'url': 'https://www.ayobandung.com/rss'}
but
[s['collect_date'] for s in mc.storyList(feeds_id=1591359)]
says all the stories have dates from "2019-03-22".
Is there a separate backlog of stories waiting to be fully processed?
The extractor has fallen behind with the increased rate of the crawler. I have increased the number of extractors so it should start catching up.
-hal
On Wed, Mar 27, 2019 at 2:59 PM rahulbot [email protected] wrote:
Feed id 1591359 is acting odd in a related way - it says that it has downloaded and added stories recently, but they don't show up in a call to storyList.
mc.feed(1591359)
says it downloaded and added stories from today (2019-03-27):
{'active': True, 'feeds_id': 1591359, 'last_attempted_download_time': '2019-03-27 15:44:47.588440-04:00', 'last_new_story_time': '2019-03-27 15:14:24.723534-04:00', 'last_successful_download_time': '2019-03-27 15:52:47-04:00', 'media_id': 329358, 'name': 'AyoBandung.com', 'type': 'syndicated', 'url': 'https://www.ayobandung.com/rss'}
but
[s['collect_date'] for s in mc.storyList(feeds_id=1591359)]
says all the stories have dates from "2019-03-22".
Is there a separate backlog of stories waiting to be fully processed?
— You are receiving this because you were assigned. Reply to this email directly, view it on GitHub https://urldefense.proofpoint.com/v2/url?u=https-3A__github.com_berkmancenter_mediacloud_issues_567-23issuecomment-2D477324667&d=DwMFaQ&c=WO-RGvefibhHBZq3fL85hQ&r=0c5FW2CrwCh84ocLICzUHjcwKK-QMUDy4RRw_n18mMo&m=SBg9r38VAR-1TfVYFNySO4xjBg6z3_sCUWCbWdjRr-U&s=v-9h4p2op2BFfgoFJ_6lIyHNxHGY_-UgDa_TcS7widA&e=, or mute the thread https://urldefense.proofpoint.com/v2/url?u=https-3A__github.com_notifications_unsubscribe-2Dauth_ABvvTxmaXmEcbhIjzkzaNmkq3NHQuTHqks5va82GgaJpZM4b-5FXWb&d=DwMFaQ&c=WO-RGvefibhHBZq3fL85hQ&r=0c5FW2CrwCh84ocLICzUHjcwKK-QMUDy4RRw_n18mMo&m=SBg9r38VAR-1TfVYFNySO4xjBg6z3_sCUWCbWdjRr-U&s=GFKfgTCmYBGNAwLE03G4JnSMwBMHGn22AewtRBdOHfk&e= .
-- Hal Roberts Fellow Berkman Klein Center for Internet & Society Harvard University