highlight-sas-stata
 highlight-sas-stata copied to clipboard
highlight-sas-stata copied to clipboard
Add functions help scrape
It was pretty quick to write up for functions specifically.
This is an HTML scrape of all names that begin with f_ in ado/base/f/.
So the idea is to have a pre-generated list with HTML help instead of calling Stata for help?
This PR isn't necessarily meant to be merged. Just to attempt an initial scraping. It would be possible to store HTML help instead of loading from Stata, but I don't think that's really a big deal.
But it would be nice to have a current list of keywords, and I think this is the best way to do that.
Also it's a lull in actual work today so I decided to implement function autocomplete.
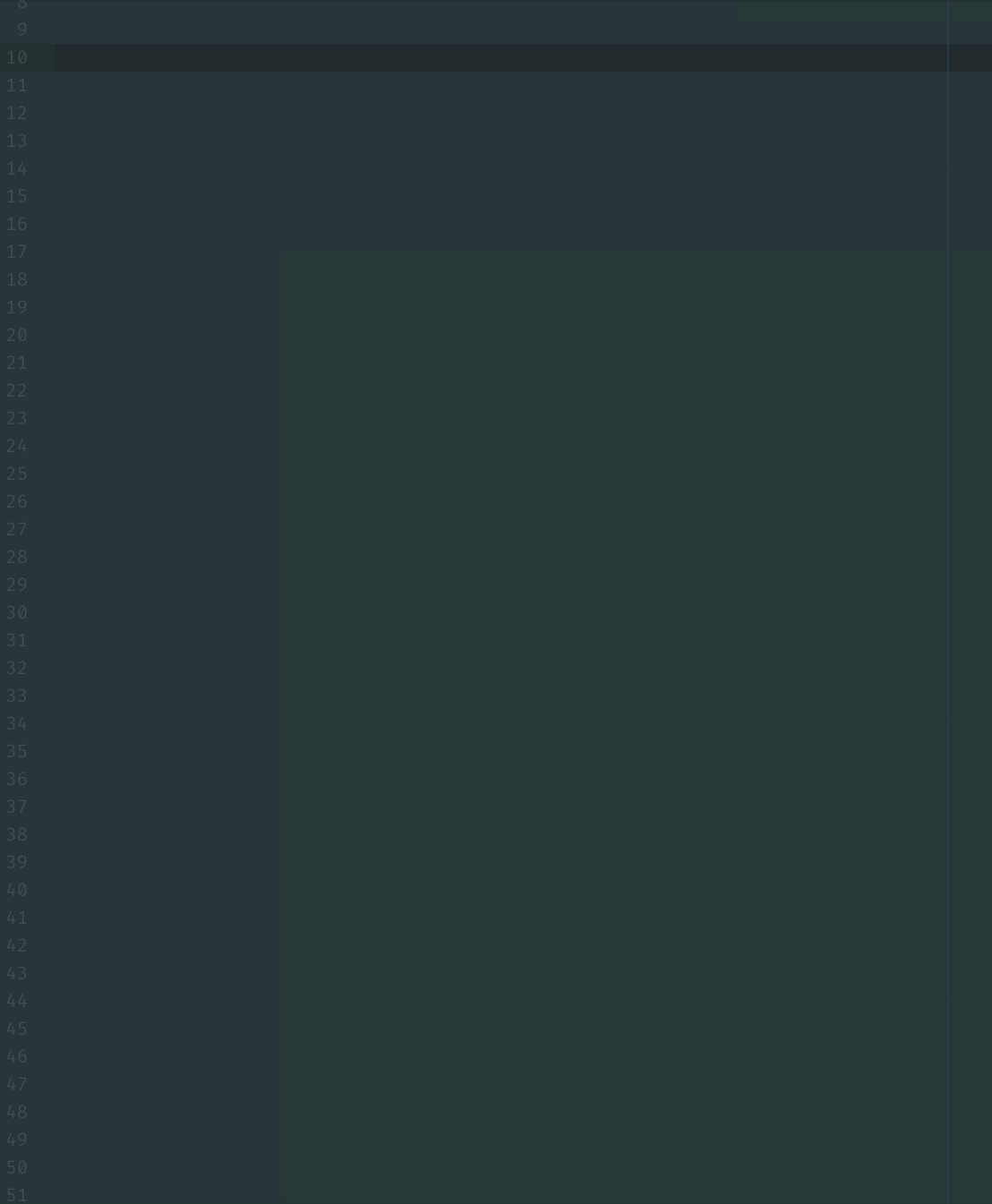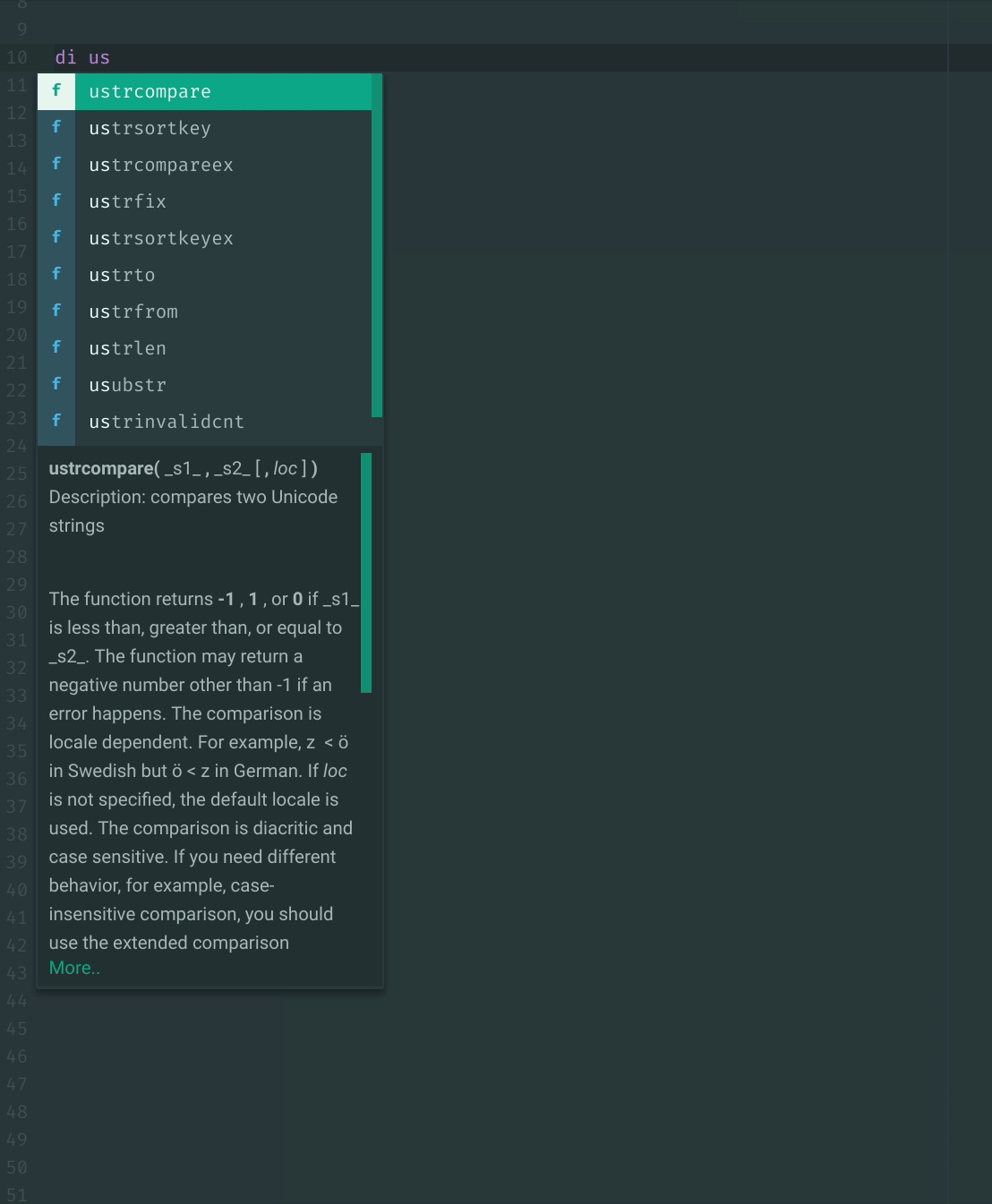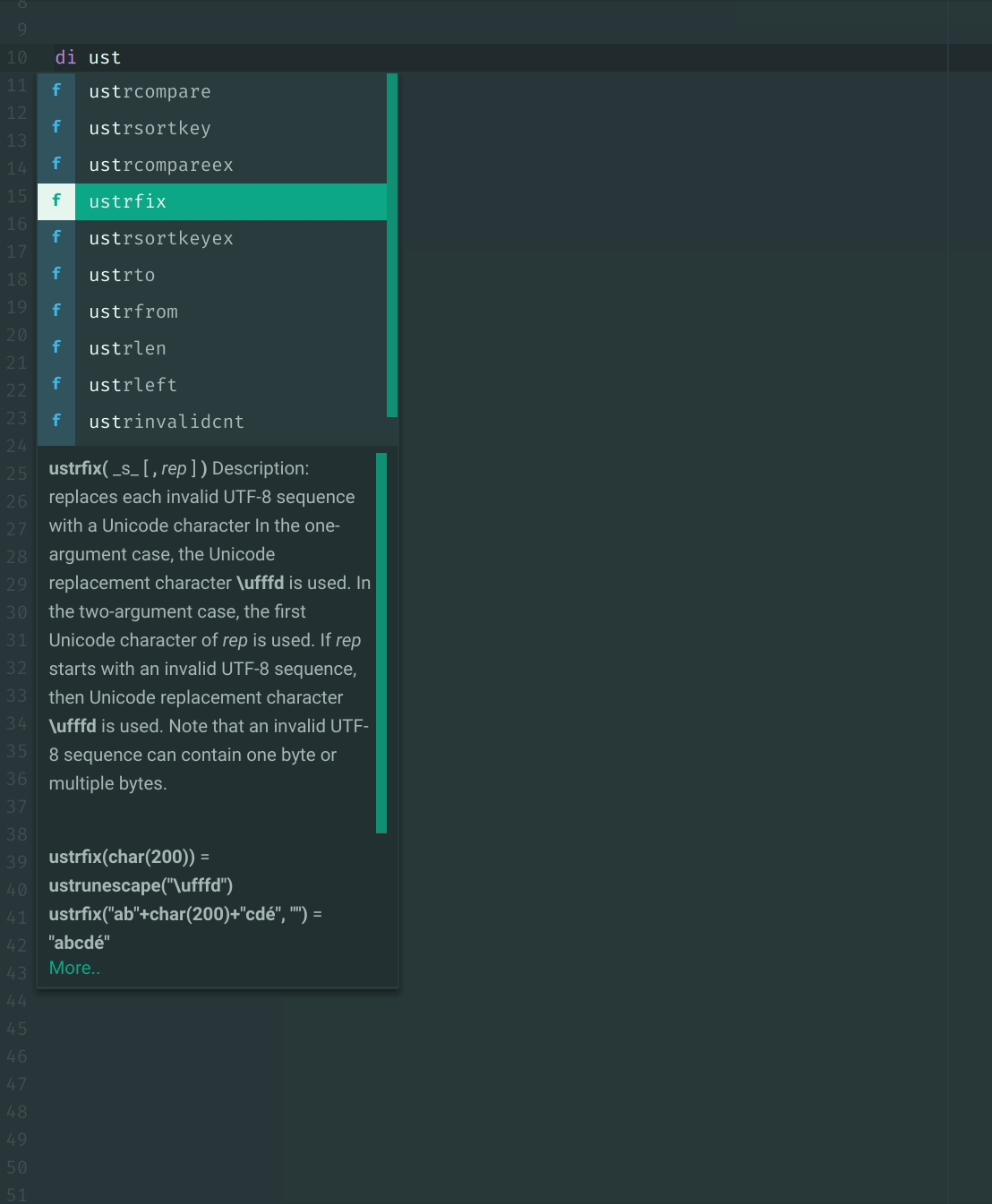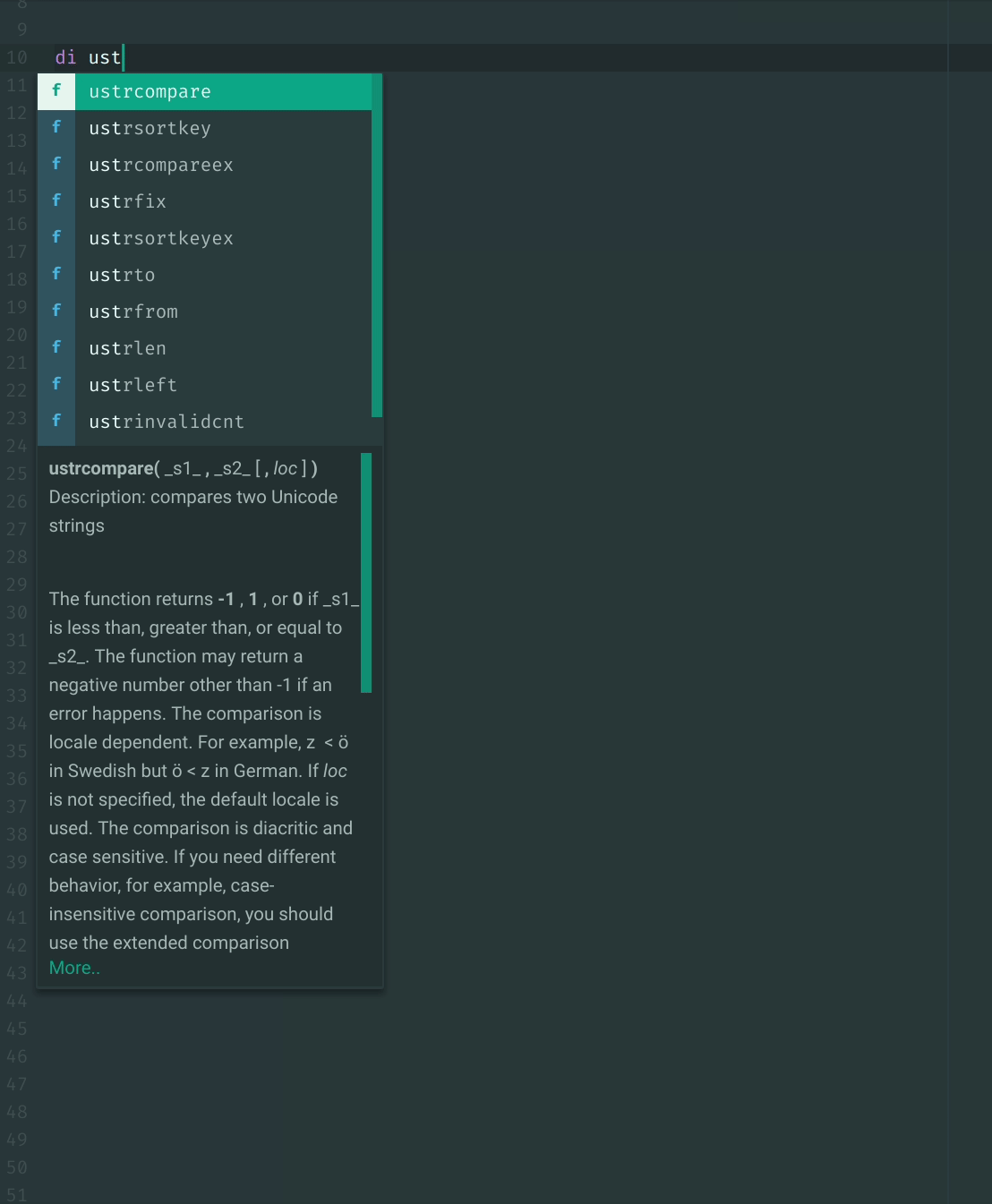
Would it make sense to do this instead of fetching help for code inspection? (With the fetch as a fallback)
I currently convert to Markdown because Atom only takes Markdown (without html tags) as input for the autocomplete descriptions.
Enclose all the things in ```?
By stability you mean because the introspection branch isn't merged yet? I think the idea of the implementation's fine bc it's not a very complicated function. The main thing to iron out is what the behavior ought to be overall.
Enclose all the things in ```?
Well right now some things are correctly bold and links work, which is nice. It's just that some _word_ instances aren't correctly turned into emphasis by Marked. I'm not sure why.
By stability you mean because the introspection branch isn't merged yet?
No I was referring to the stability of this help file parsing.
I've been working on command help file scraping code... From scraping all the terms under ado/base/a, I've found the following list of terms:
['adoupdate',
'alpha',
'ameans',
'anova',
'anovadef',
'append',
'arch',
'areg',
'arfima',
'args',
'arima',
'asclogit',
'asmixlogit',
'asmprobit',
'asroprobit',
'assert',
'set autotabgraphs']
For each of these I have the corresponding HTML, so that I can see what is underlined/bolded/(un)necessary:
<p>
<b><u>an</u></b><b>ova</b> <a href="/help.cgi?varname"><i>varname</i></a> [<i>termlist</i>] [<a href="/help.cgi?if"><i>if</i></a>] [<a href="/help.cgi?in"><i>in</i></a>] [<a href="/help.cgi?anova#weight"><i>weight</i></a>] [<b>,</b> <i>options</i>]
</p>
I was recommended getcmds over in Statalist. Apparently it was written by a StataCorp person, and it basically loops over everything in ado (and the user's local ado folders):
net install getcmds, from(http://www.stata.com/users/jpitblado
getcmds using installed.txt, all
This makes a list of every installed command, but I think it's using the same idea as your scrapping (while it does list more commands under a, not all are useful). It might be good to compare lists; it also doesn't do functions (or, obviously, fetch HTML help).
Interesting. It does show that there's value to looping over files with .ado suffixes and not just files with .sthlp suffixes.