workboots
 workboots copied to clipboard
workboots copied to clipboard
some questions about methodology
I'm not sure that getting percentiles of the predictions is the same thing as a prediction interval. It think that it is more like a confidence interval of the predictions.
Have you done any simulations to make sure that the statistical properties, like coverage, are correct for cases where we know the answers (e.g. simulation)?
Also, the default number of resamples is excessively low since we are estimating very small parts of the distribution. I know that it is important to have a default that can run easily but I would suggest adding a note to the documentation that around 2000 resamples should be used to get stable results.
Hi @topepo - thanks for your comment!
Yes it looks like there was quite the oversight on my part in that the initial version of predict_boots() essentially recreated the prediction's standard error. I've made a quick update that I'll work on turning into a patch over the weekend. I had tested a few cases to make sure the interval was capturing the expected range when putting this together --- though I had checked w/non-linear models that in hindsight were probably just learning the dataset and gave me quick false optimism in the initial results.
I had waffled back/forth on the default n to use as well. Perhaps larger with a warning should be the default?
This reprex was put together w/the 0.1.1-patches branch to address your first point
library(tidymodels)
#> Warning: package 'tidymodels' was built under R version 4.1.2
#> Registered S3 method overwritten by 'tune':
#> method from
#> required_pkgs.model_spec parsnip
#> Warning: package 'broom' was built under R version 4.1.2
#> Warning: package 'dials' was built under R version 4.1.2
#> Warning: package 'dplyr' was built under R version 4.1.2
#> Warning: package 'ggplot2' was built under R version 4.1.2
#> Warning: package 'infer' was built under R version 4.1.2
#> Warning: package 'modeldata' was built under R version 4.1.2
#> Warning: package 'parsnip' was built under R version 4.1.2
#> Warning: package 'recipes' was built under R version 4.1.2
#> Warning: package 'rsample' was built under R version 4.1.2
#> Warning: package 'tibble' was built under R version 4.1.2
#> Warning: package 'tidyr' was built under R version 4.1.2
#> Warning: package 'tune' was built under R version 4.1.2
#> Warning: package 'workflows' was built under R version 4.1.2
#> Warning: package 'workflowsets' was built under R version 4.1.2
#> Warning: package 'yardstick' was built under R version 4.1.2
library(workboots)
# setup data
data("penguins")
penguins_mod <- penguins %>% drop_na()
# setup parallel processing (windows)
num_cores <- parallel::detectCores()
clusters <- parallel::makePSOCKcluster(num_cores)
doParallel::registerDoParallel(clusters)
# resampled preds
wf <-
workflow() %>%
add_recipe(recipe(body_mass_g ~ flipper_length_mm, data = penguins_mod)) %>%
add_model(linear_reg())
boot_preds <-
wf %>%
predict_boots(
n = 2000,
training_data = penguins_mod,
new_data = penguins_mod
)
# linear model for comparison
mod <- lm(body_mass_g ~ flipper_length_mm, data = penguins_mod)
boot_preds %>%
summarise_predictions() %>%
bind_cols(penguins_mod) %>%
bind_cols(mod %>%
predict(as_tibble(penguins_mod), interval = "predict") %>%
as_tibble()) %>%
ggplot(aes(x = flipper_length_mm)) +
geom_point(aes(y = body_mass_g)) +
# prediction interval from linear model in gray
geom_ribbon(aes(ymin = lwr,
ymax = upr),
alpha = 0.25) +
# bootstrap interval & pred in blue
geom_point(aes(y = .pred),
color = "blue") +
geom_errorbar(aes(ymin = .pred_lower,
ymax = .pred_upper),
color = "blue",
alpha = 0.25) +
geom_smooth(aes(x = flipper_length_mm,
y = body_mass_g),
method = "lm")
#> `geom_smooth()` using formula 'y ~ x'

Created on 2022-03-10 by the reprex package (v2.0.1)
That's great! Thanks so much for doing that. Maybe put the graph in the readme or somewhere visible. Did you mean to use alpha = 0.025?
Perhaps larger with a warning should be the default?
We had the same question when we were writing the bootstrap interval code in rsample. We ended up adding this function to select functions that issues a warning. Feel free to use any of that if you want. Our default is 25 resamples.
One related thing about residuals, and I really don't know the answer this question, is: should we re-predict the same data set to get the residuals or use some sort of holdout to estimate residuals? My intuition says the latter but I really don't know. Know anyone who needs a dissertation topic? 😄
Definitely agree --- the graph ought to go to into the documentation (my first thought is as a vignette but open to suggestion!) --- though I ought to separate out training_data/new_data. alpha = 0.25 is for the geom's transparency --- the default for summarise_predictions() uses 0.025 & 0.975 for the lower/upper bounds. Lots of greek letter overlap!
Thank you for sharing the check function --- I'll take a look in more detail this weekend!
For the residuals, the quick fix follows the method from section 6.2.3 of Bootstrap Methods and their Application by Davison/Hinkley, which fits to a training resample, than randomly selects one of the residuals (w/replacement) to add to each of the model's predictions on new data, then repeats n times (mentioned in this CV discussion that was helpful when putting this together). There's certainly a lot more digging that can be done there --- the paragraph preceding the section also describes estimating (then sampling from) the residual distribution function, but then describes the method of sampling from the "raw" residuals.
One thing I want to dig into further this weekend is whether it's better to sample from the "raw" residuals directly (resid_i) or from: resid_i - resid_avg (my hunch is the latter). When the average of the residuals is 0, they're the same, but when it's not, the raw residuals will be slightly different. The quick fix just pulls a residual directly, and you can see in the example above that all the bootstrap intervals are slightly lower than the theoretical interval from the linear model in gray. I believe this is because the linear model's residuals are approximately normal but have a slight negative bias whereas the theoretical interval is perfectly normal/centered at 0, but that's something to investigate.
Lots of word salad here --- there's definitely lots of work still to be done on this package! It may be better if I tag the package as "experimental" while working through some of these nuts & bolts !!
library(tidymodels)
# setup data
data("penguins")
penguins_mod <-
penguins %>%
drop_na()
# residuals
resids <- lm(body_mass_g ~ flipper_length_mm, data = penguins_mod) %>%
resid() %>%
as_tibble() %>%
rename(residual = value)
# plot
resids %>%
ggplot(aes(x = residual)) +
geom_density()

Created on 2022-03-11 by the reprex package (v2.0.1)
Ah right about the alpha 🙄
One thing about a lot of the bootstrap theory for model performances - a lot of it was developed when we didn't have a lot of access to software for low-bias models.
A good example is the bootstrap 632 rule, which blends the bootstrap error rate and the apparent error rate. The problem is, as model complexity increases in models like SVMs or neural nets, the apparent error quickly goes to zero and the 632 rule goes way off track.
Here's an example from Applied Predictive Modeling:
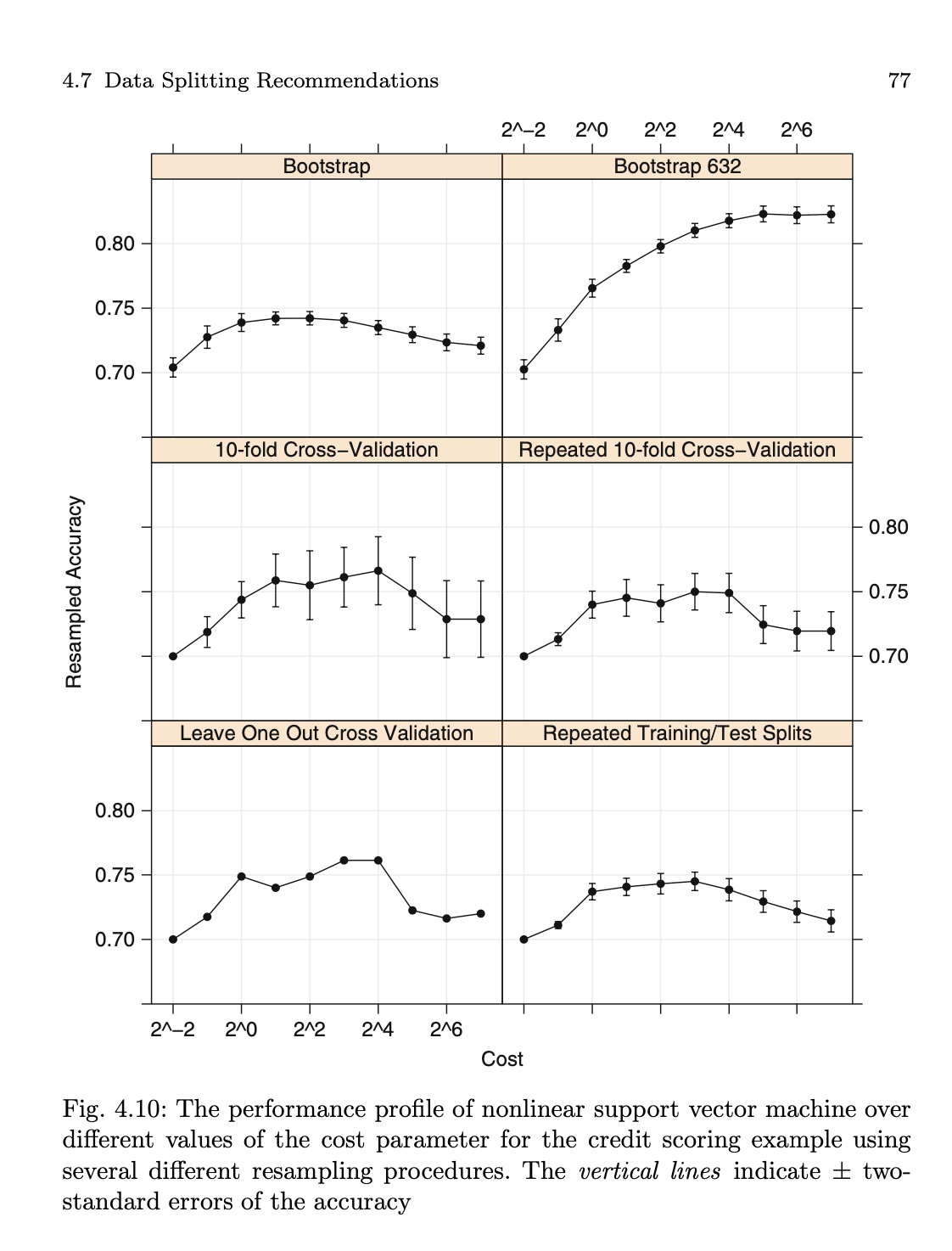
The 632 estimate is diverging because it is overly blending the apparent error rate.
It's not that math is wrong but it I feel like there is a latent assumption in there that many not be true for a lot of models (like random forest).
(edit for grammer)