ml_animated
 ml_animated copied to clipboard
ml_animated copied to clipboard
Use animation to explain machine learning
Machine Learning, Animated
(click on the animations to see actions)

Words and pictures don't do machine learning justice...
Animations do!
Explain Machine Learning through Animation
Machine learning is a powerful tool: it has beaten the world Go champion; it's the brain behind self-driving cars. However, machine learning algorithms are like black boxes and hard to understand.
This free online book is here to help. It summarizes machine learning in three words: initialize; adjust; repeat.
- Step 1: A machine learning model assigns values to parameters (initialize);
- Step 2: It makes predictions based on the parameters and compares predictions with the actual values; it changes the parameters so that the predictions will move closer to the actual values (adjust);
- Step 3: It repeats step 2 until the parameters converge (repeat).
Better yet, the book will use animations to show step by step how machines learn: the initial parameter values, the adjustment in each step, and the final converged parameters and predictions.
Ch1: Create Animations
Create graphs and plots; convert them into animations; combine multiple animations into one.

Ch2: Gradient Descent -- Where Magic Happens
Gradient descent guides the model to adjust parameters so they converge. The learning rate controls how fast to adjust: too fast, the parameters never converge (left of the animation below); too slow, it takes too long to train the model (right side)
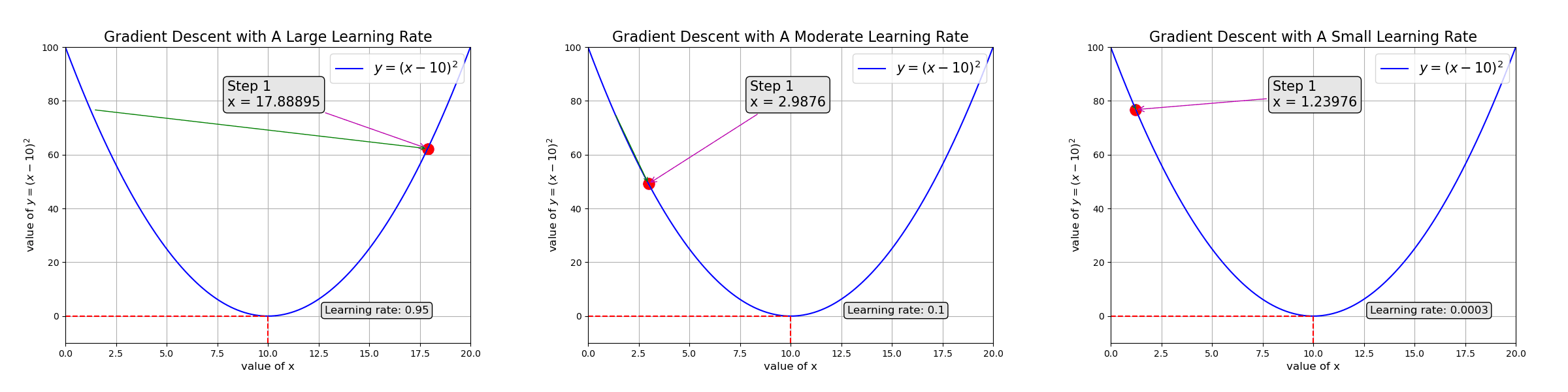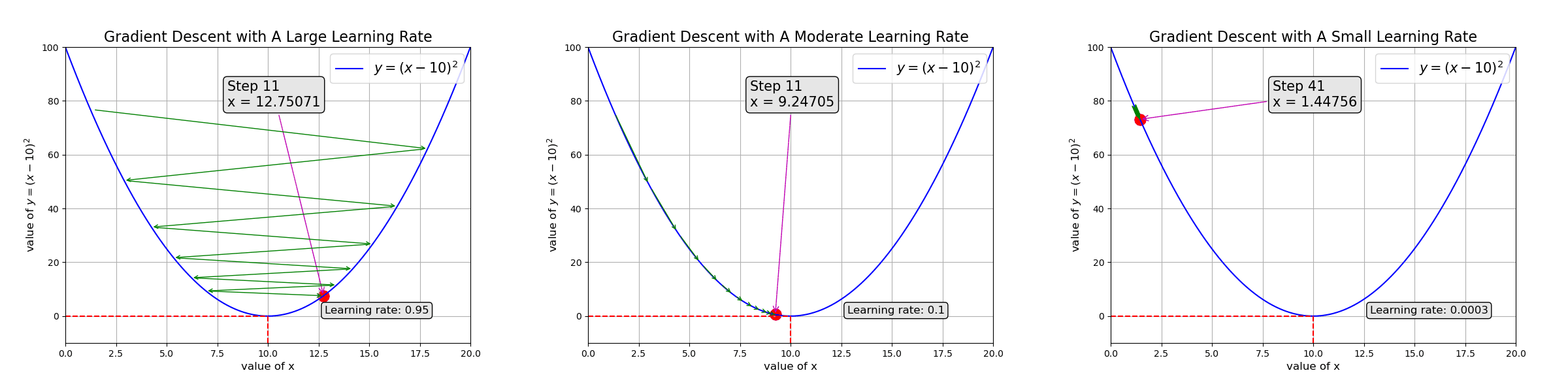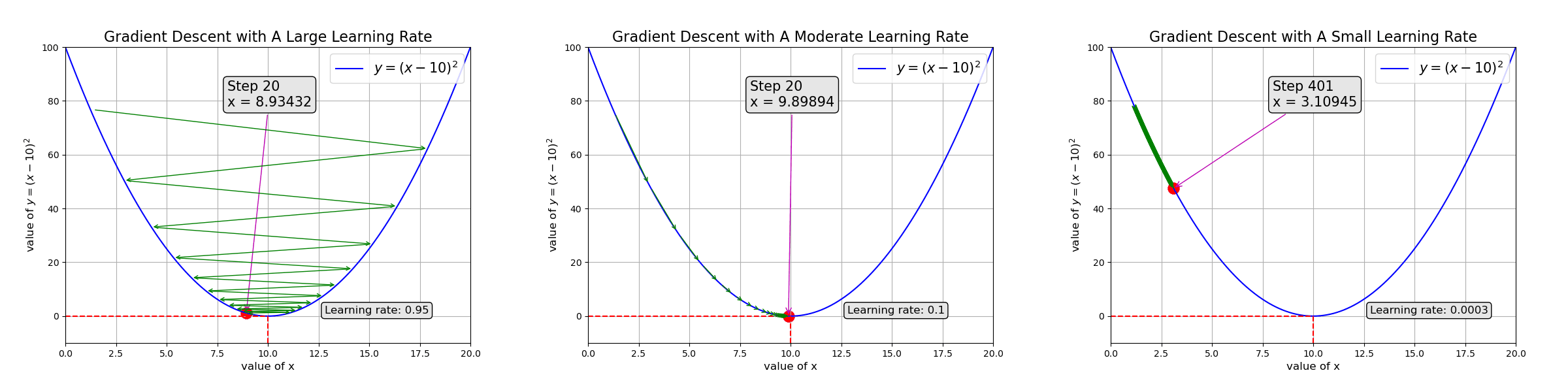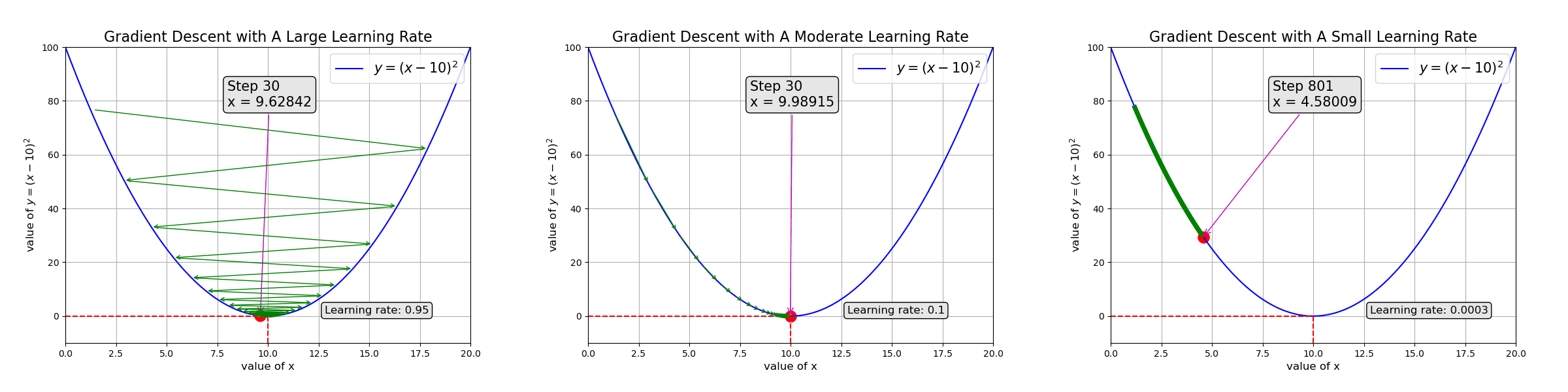
Ch3: Introduction to Neural Networks
See how a neural network learns from ten pairs of values: 𝑋=−40, 𝑌=−40;𝑋=0, 𝑌=32;...;𝑋=100, 𝑌=212. The model first assigns values to w and b in 𝑌=w𝑋+b; it then uses gradient descent to adjust the values of w and b; finally it figures out a linear relation between 𝑋 and 𝑌 that corresponds to the relation between Celsius and Fahrenheit 𝑌=1.8∗𝑋+32. This animation shows the value of w and b in each step:
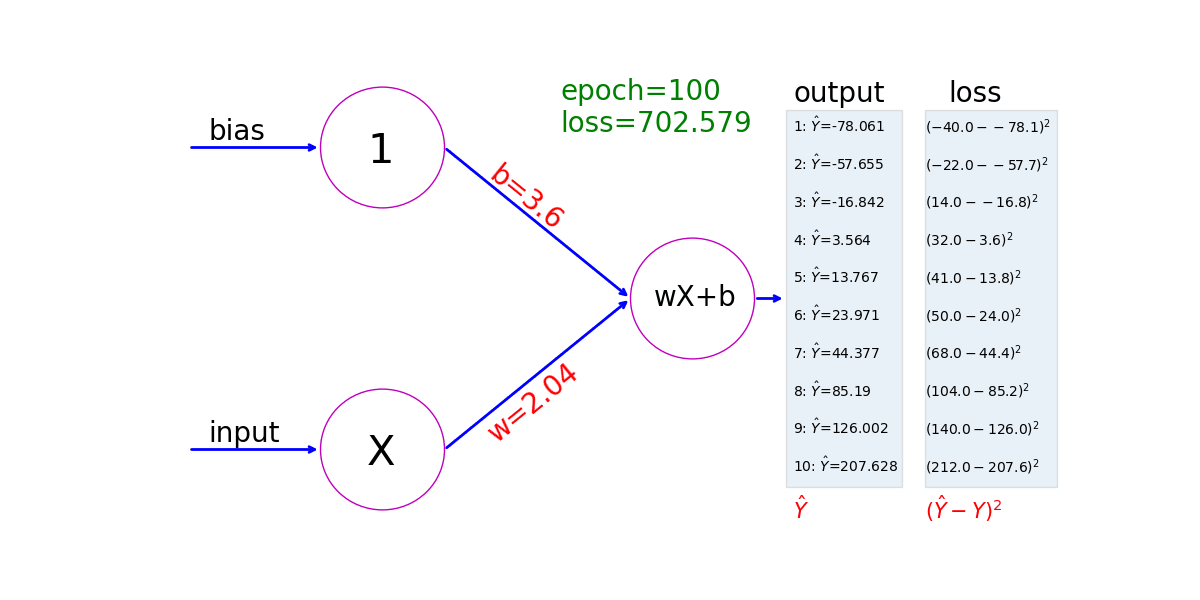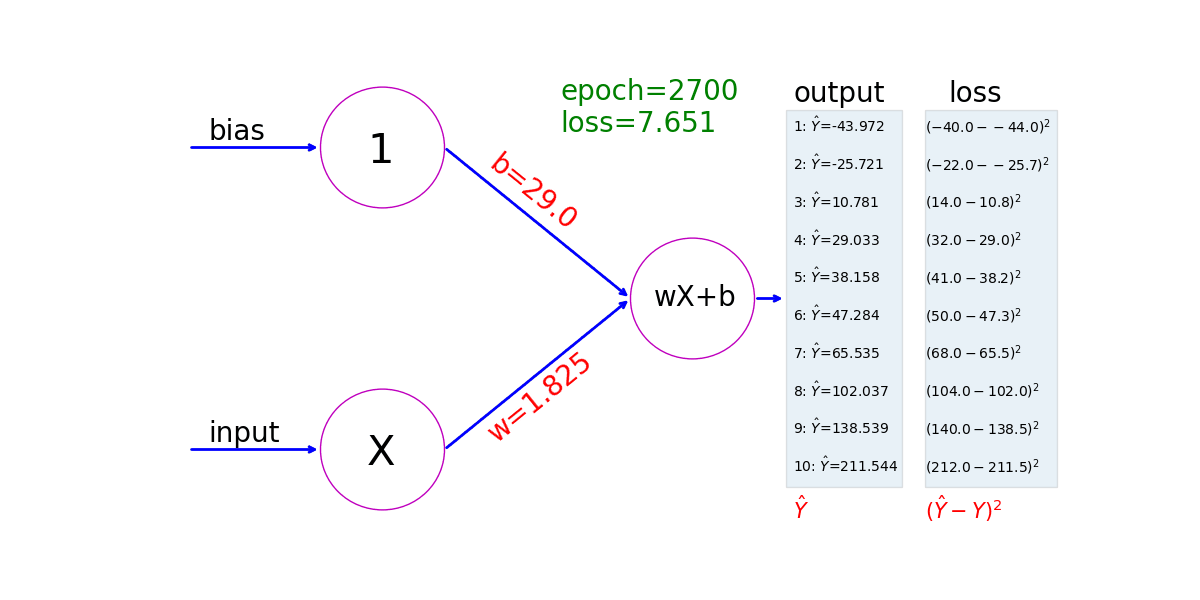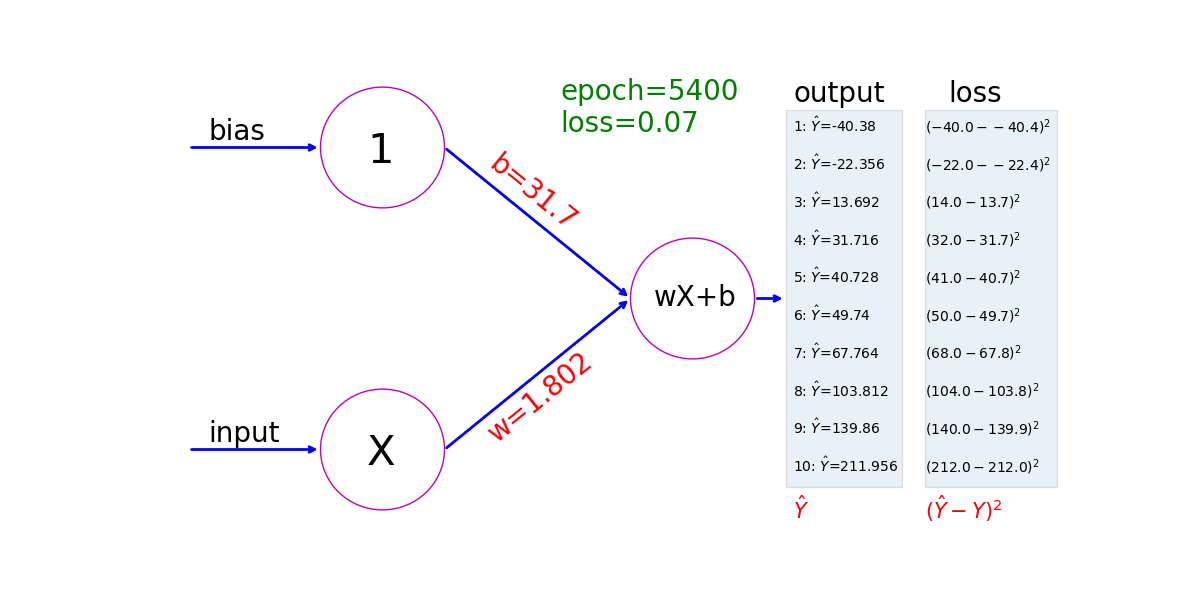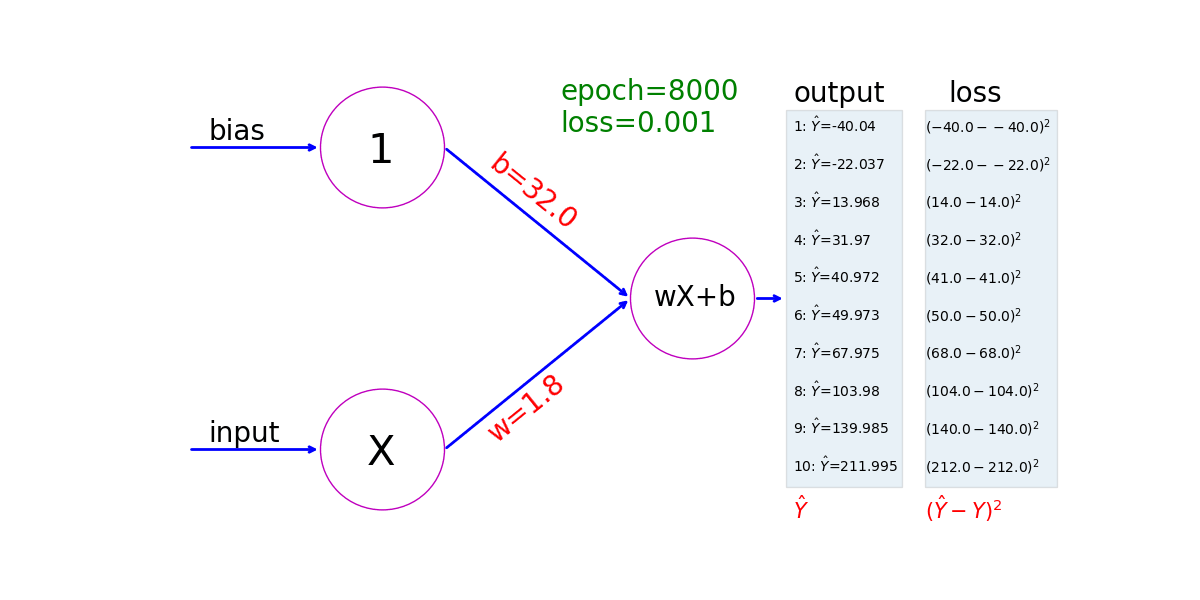
Ch4: Activation Functions
We need activation functions such as ReLU to approximate nonlinear relations (as in the left of the animation); or sigmoid to squash values to the range [0, 1] so it can be interpreted as a probability (as in the right of the animation)
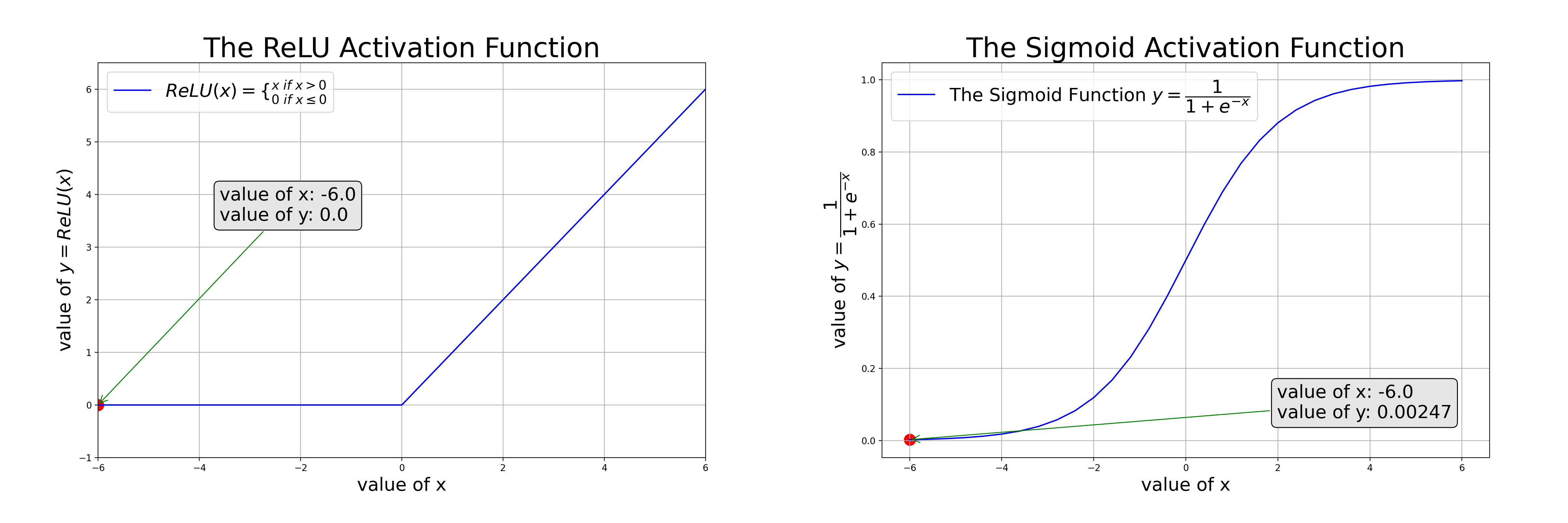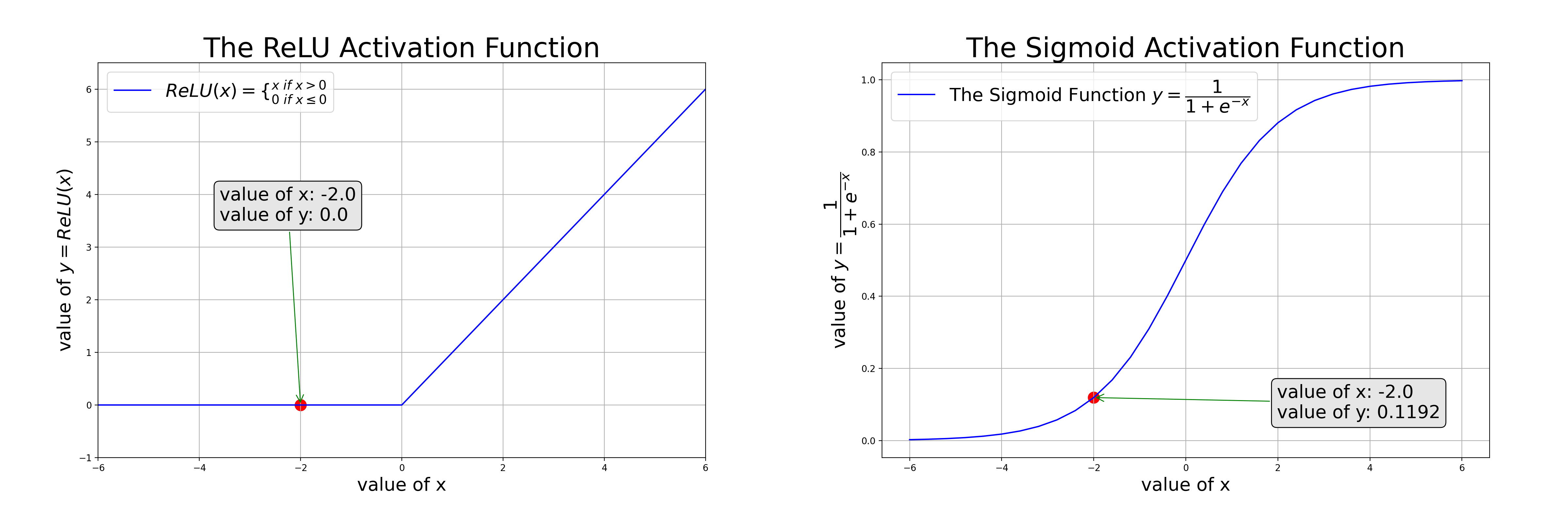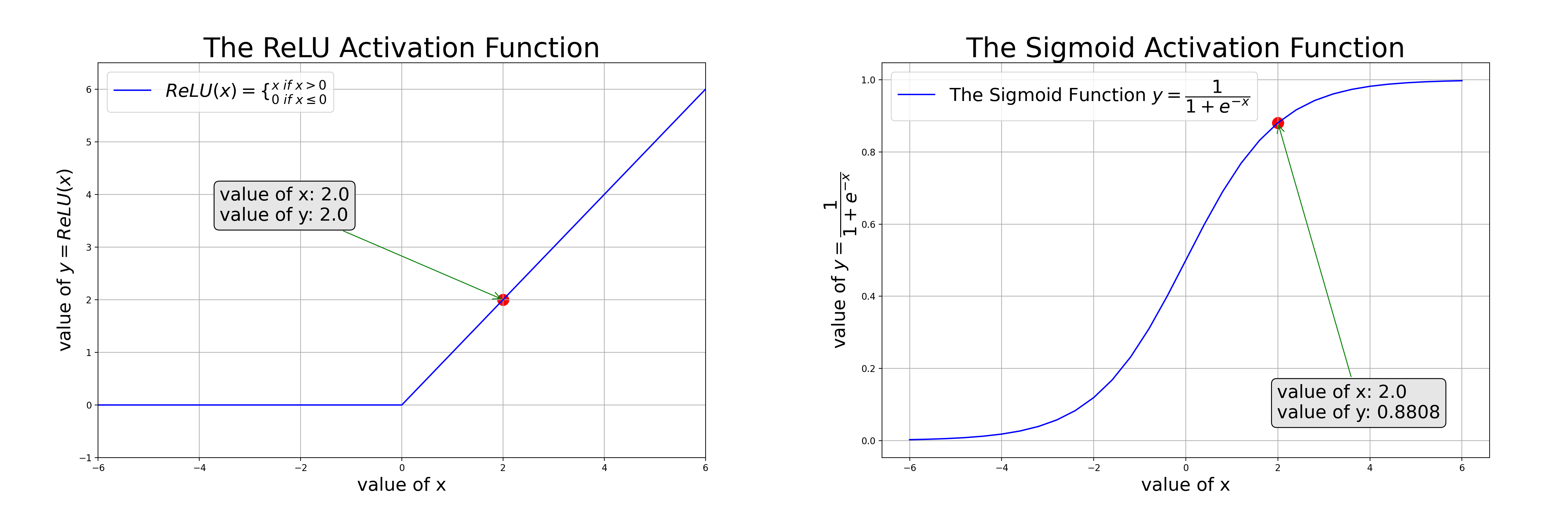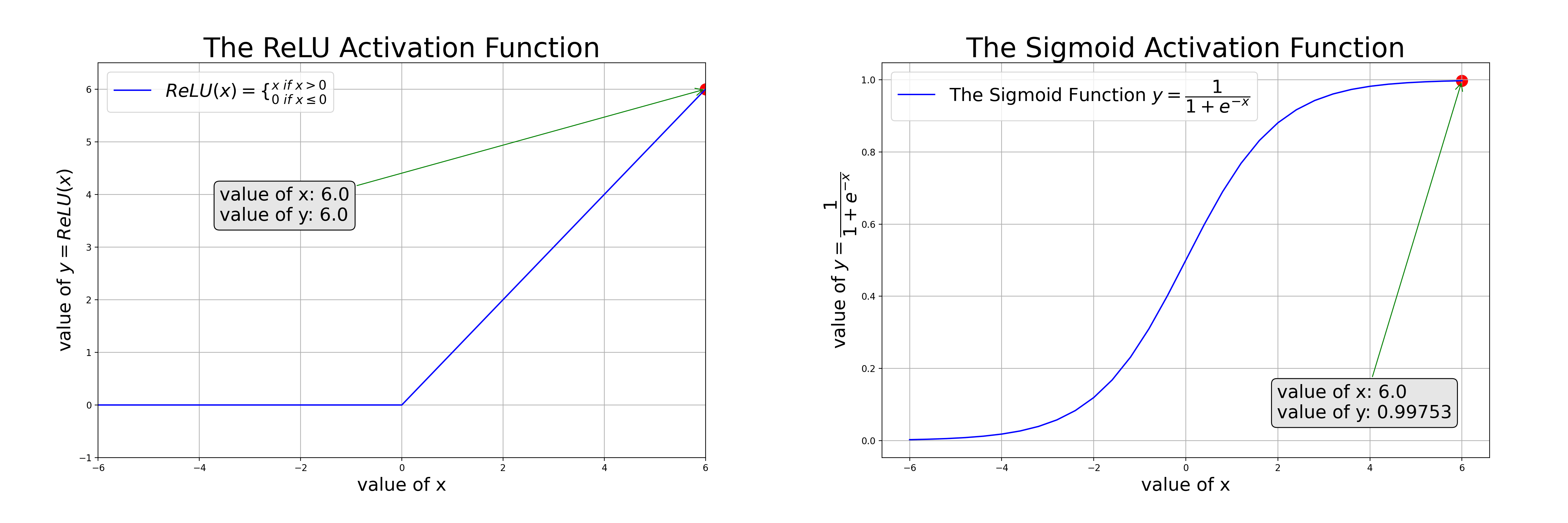
Ch5: Binary Classifications
See how a neural network with sigmoid activation learns from image-label pairs. During the course of training, the model weights gradually change and the prediction on a picture of a horse goes closer and closer to 1 (as in the left of the animation) and the prediction on a picture of a deer goes closer and closer to 0 (as in the right of the animation).
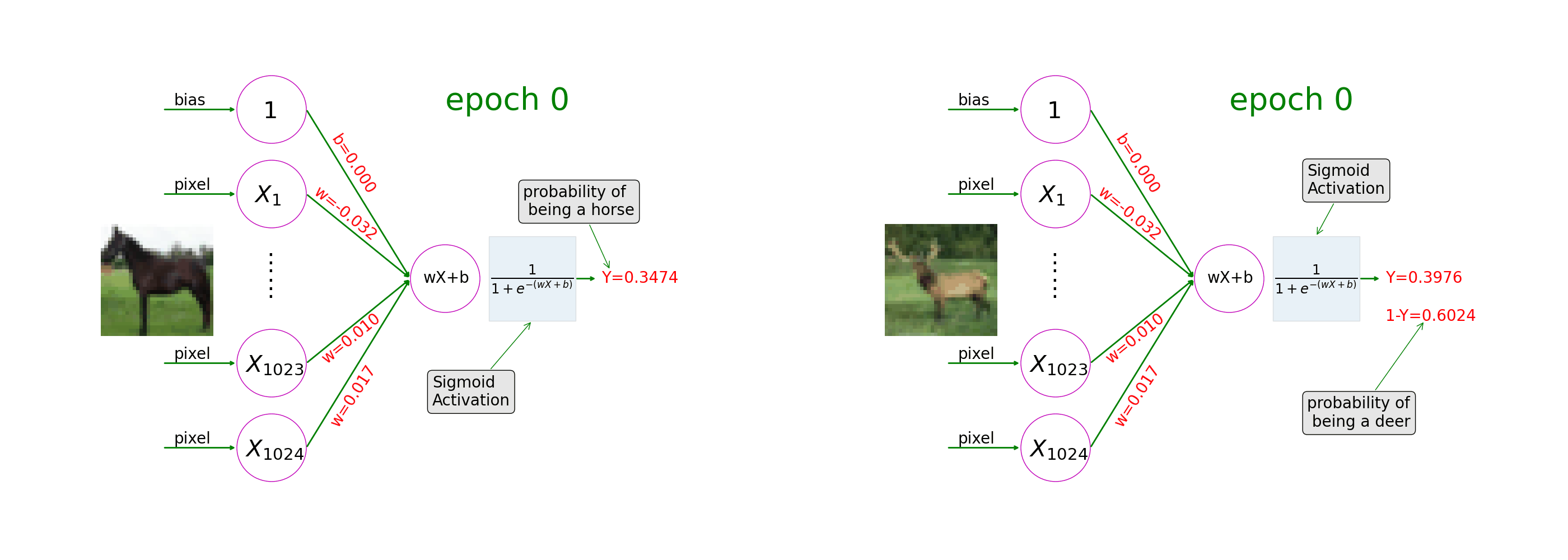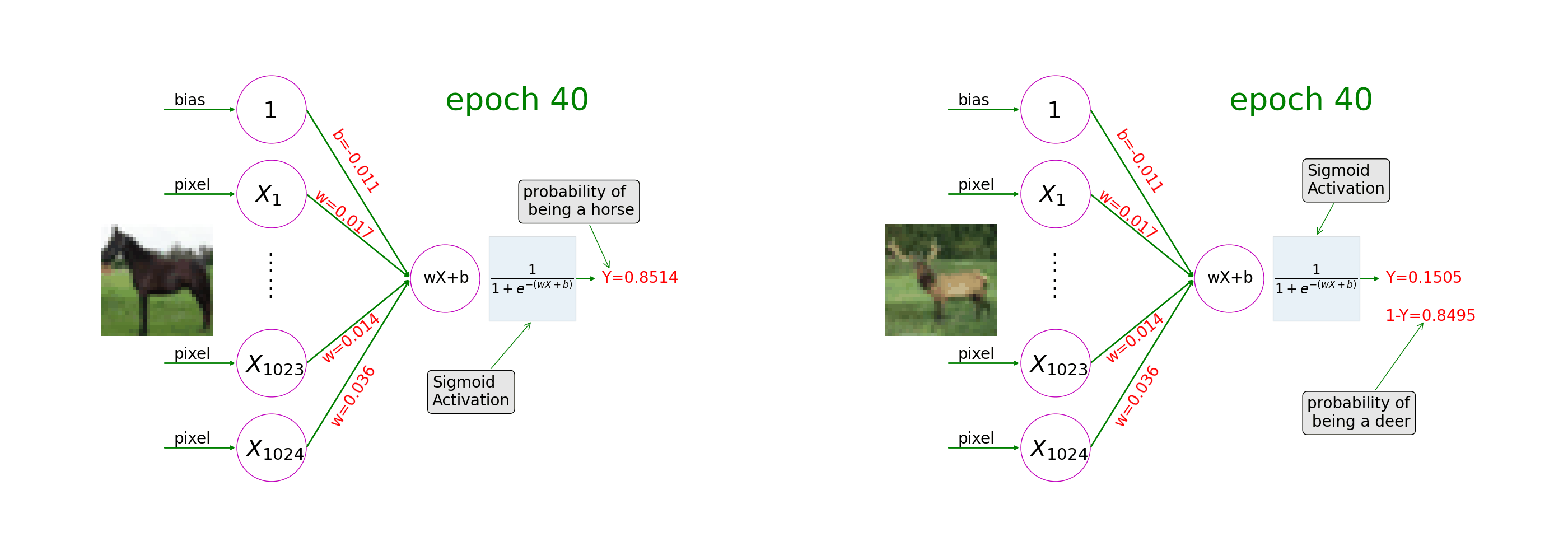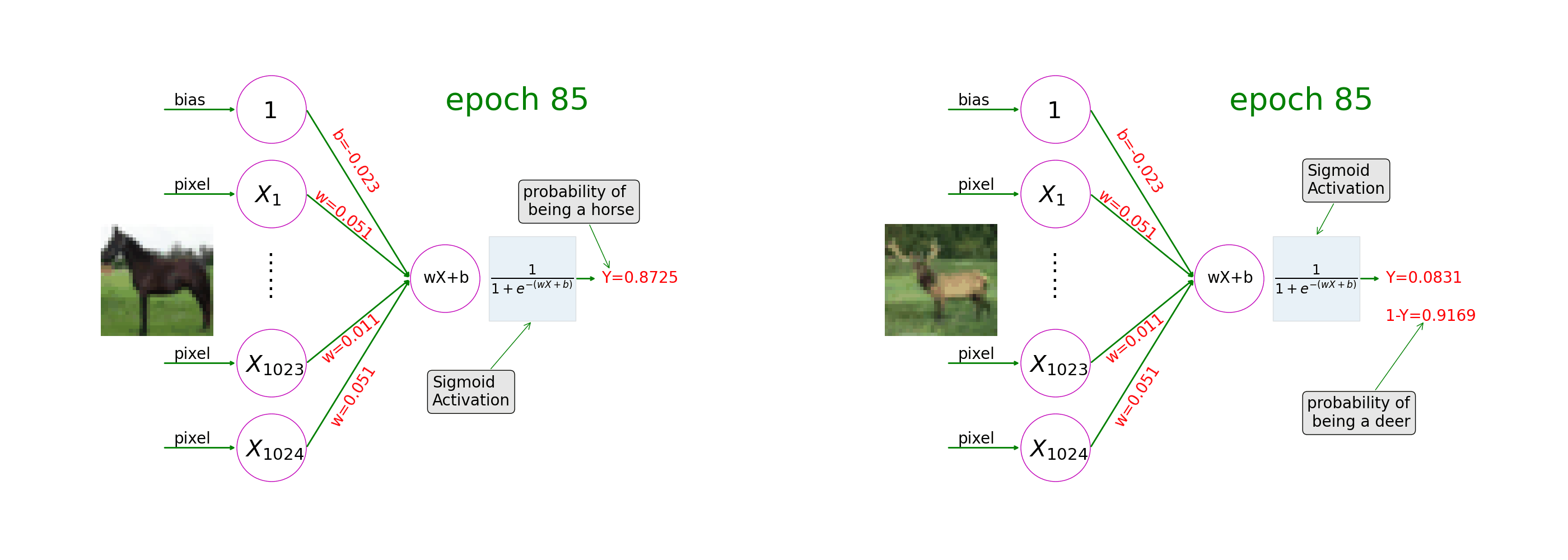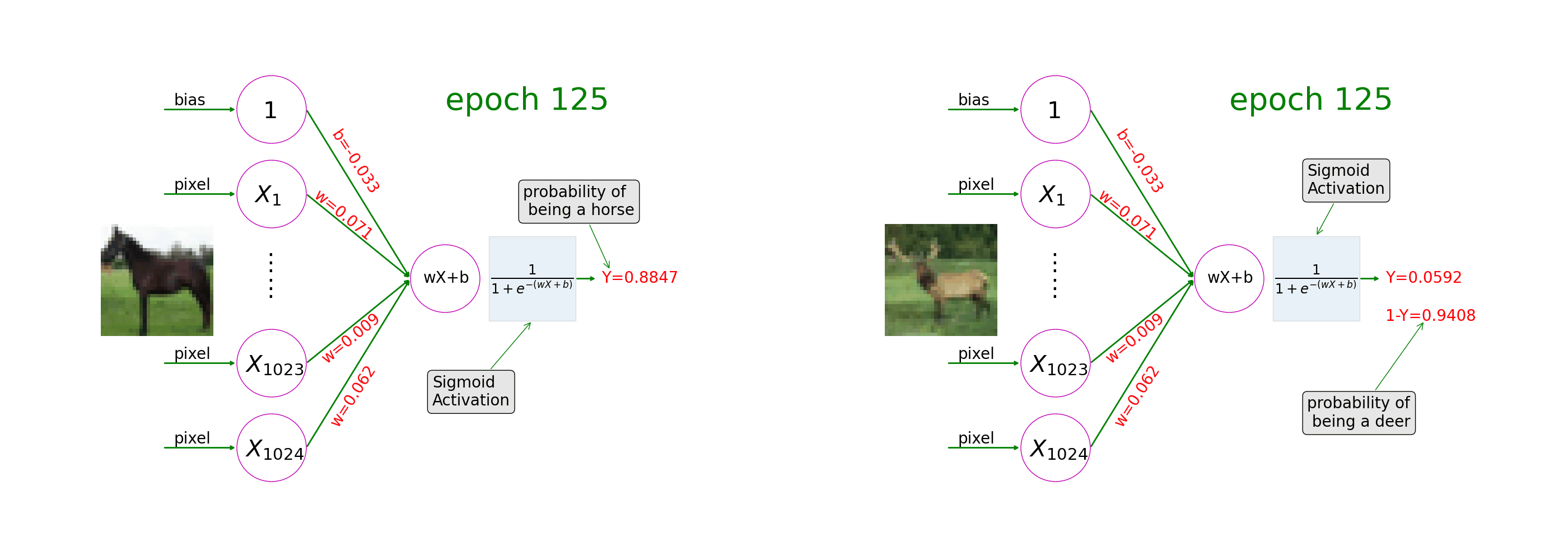
Ch6: Convolutional Neural Networks
Learn how convolutional layers extract features from images. See a 3 by 3 filter scans over a 3 by 3 image with zero-padding (as in the left of the animation) and a 2 by 2 filter scans over a 6 by 6 image with stride=2 (as in the right of the animation)
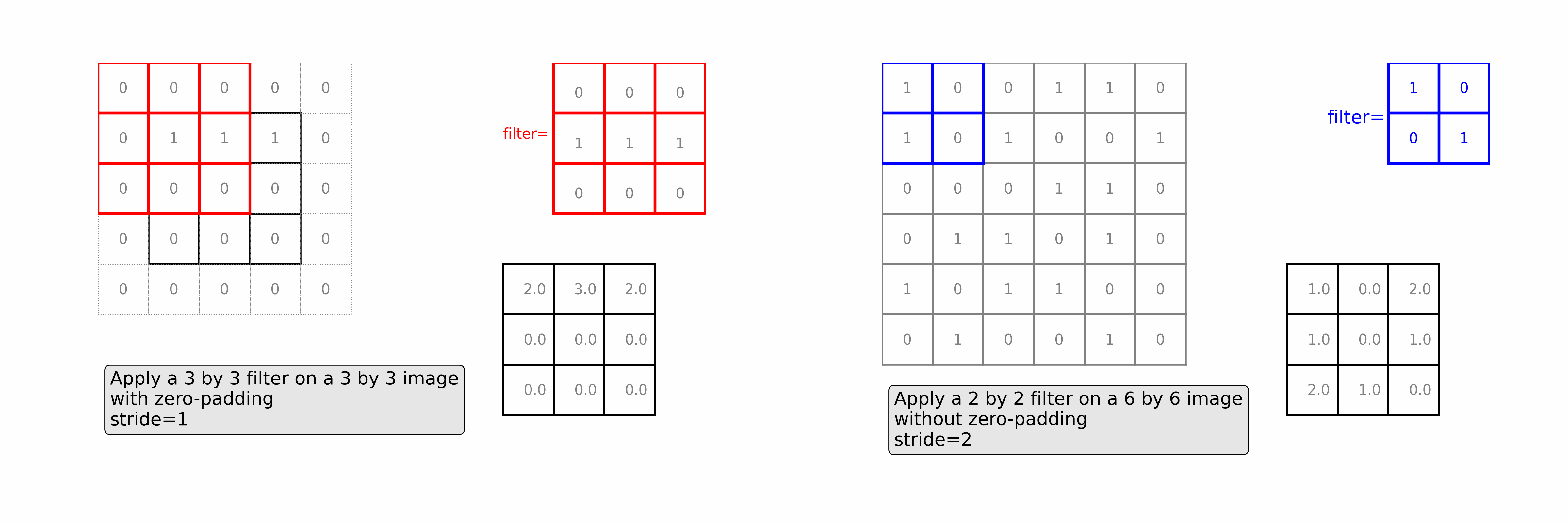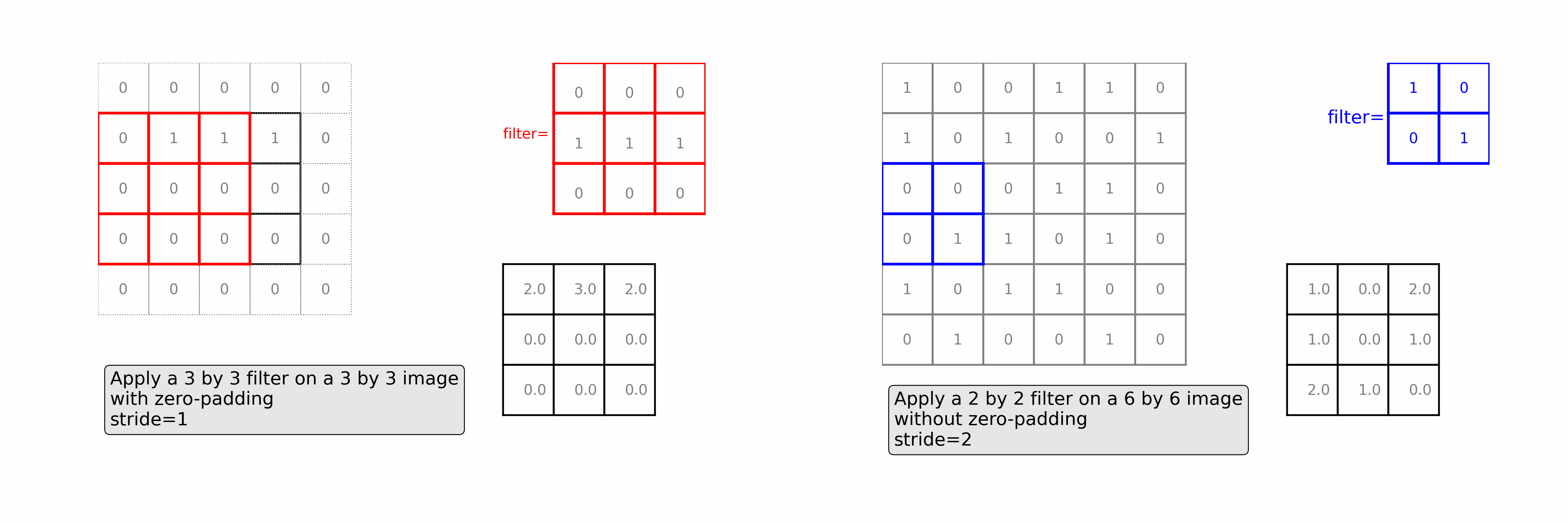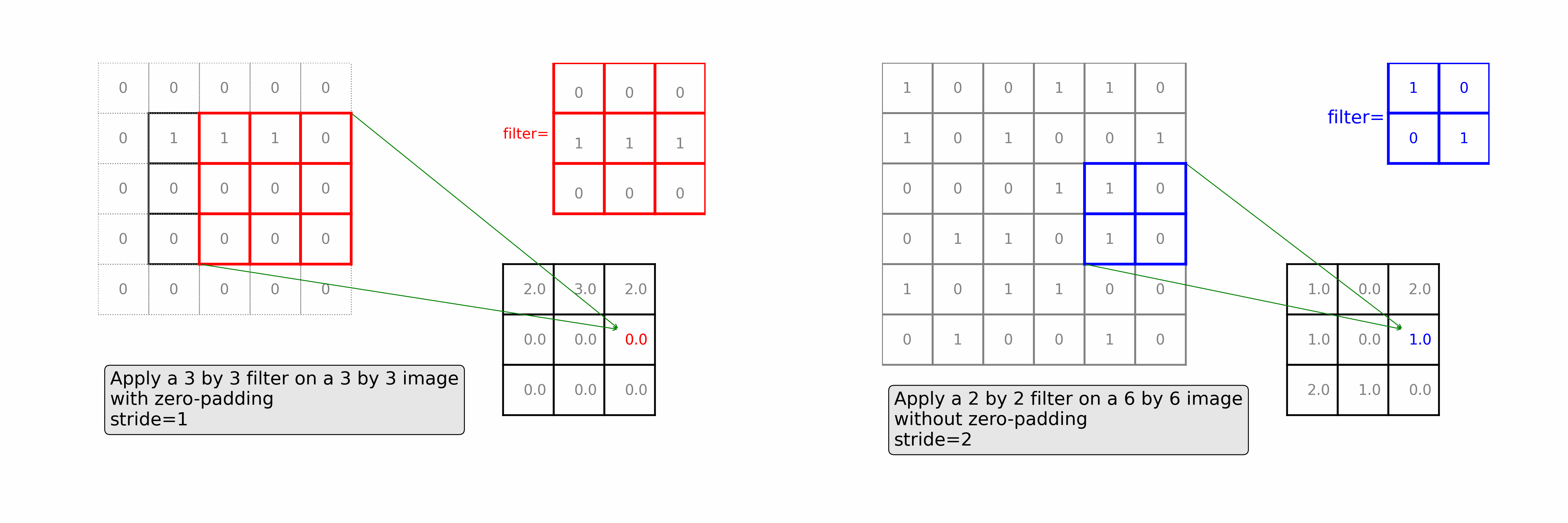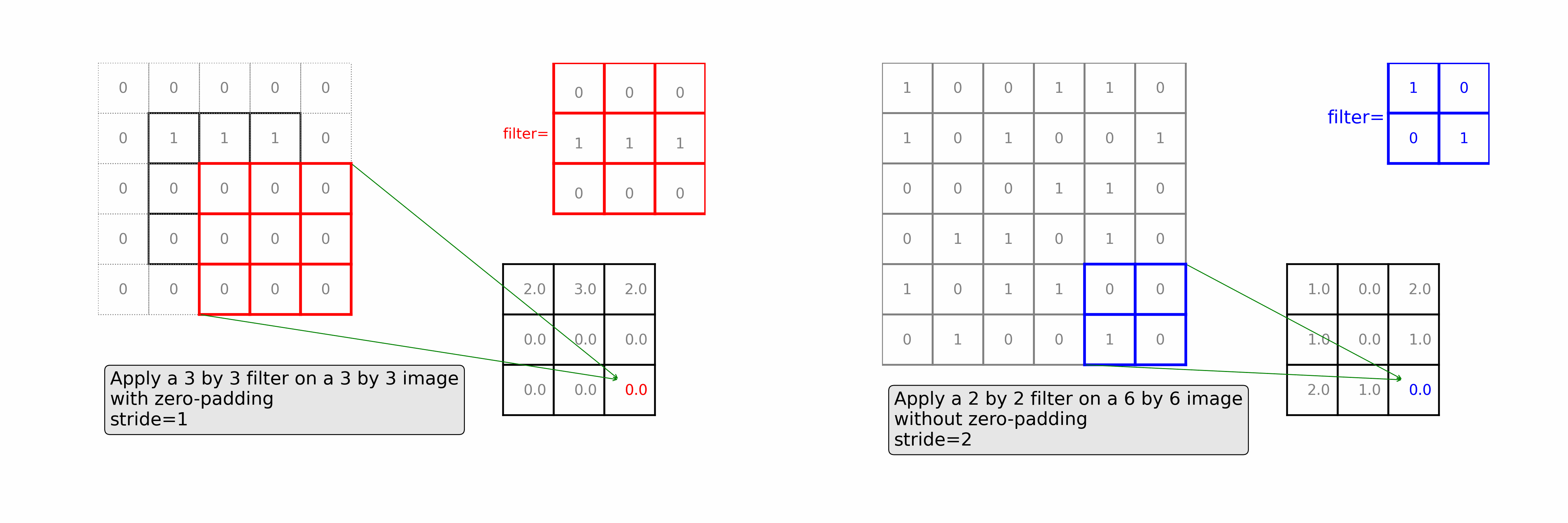
Ch7: Multi-Class Image Classifications
Understand how image augmentation and convolutional layers help neural networks learn from image-label pairs. As the training progresses, the 10th value of the prediction on a picture of a truck goes closer and closer to 1 and the rest to 0 (as in the left of the animation); the 7th value of the prediction on a picture of a frog goes closer and closer to 1 (as in the right of the animation).
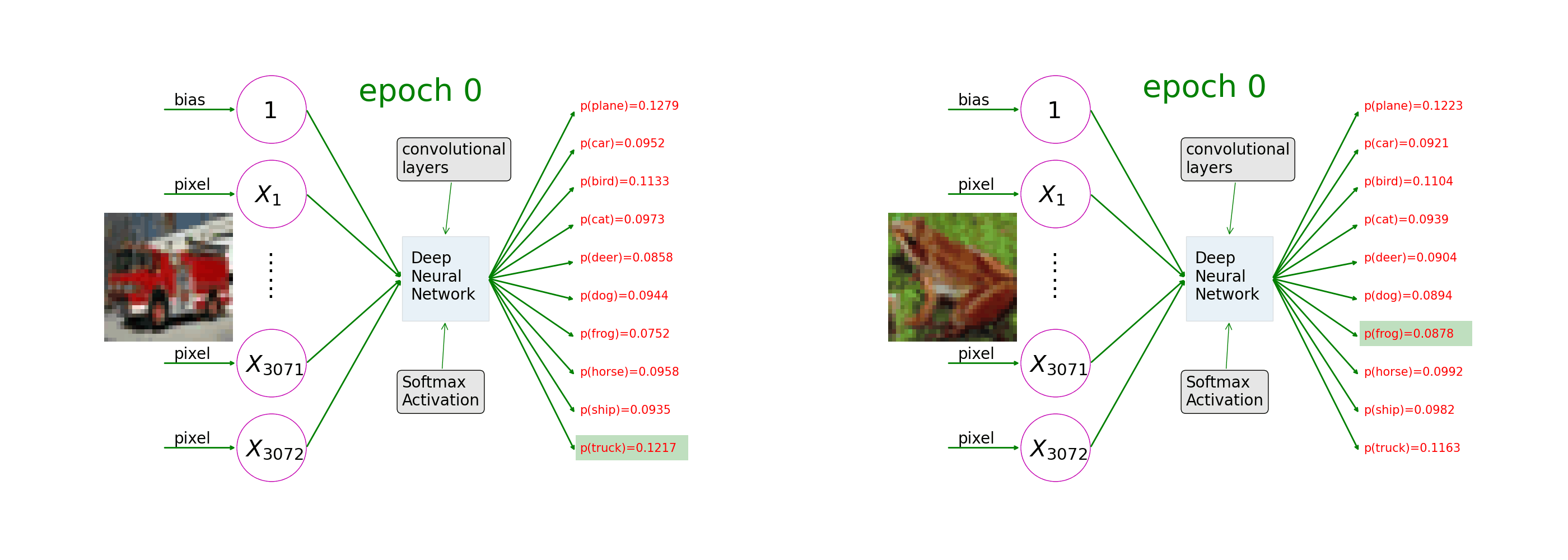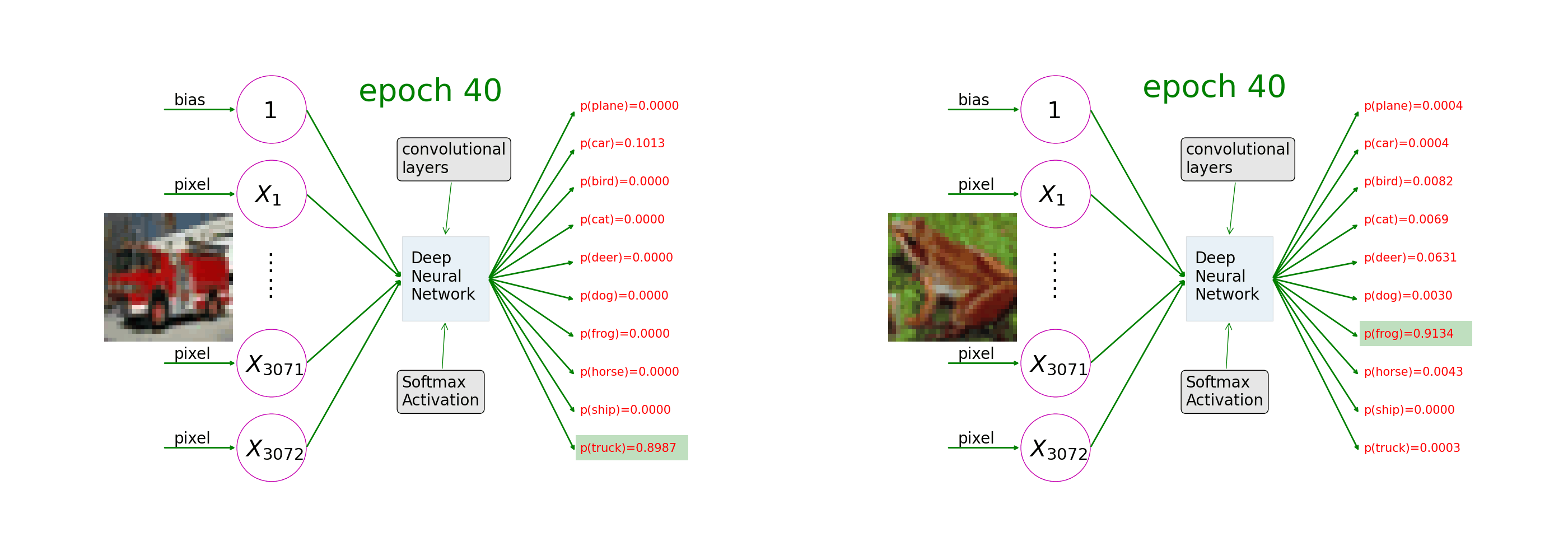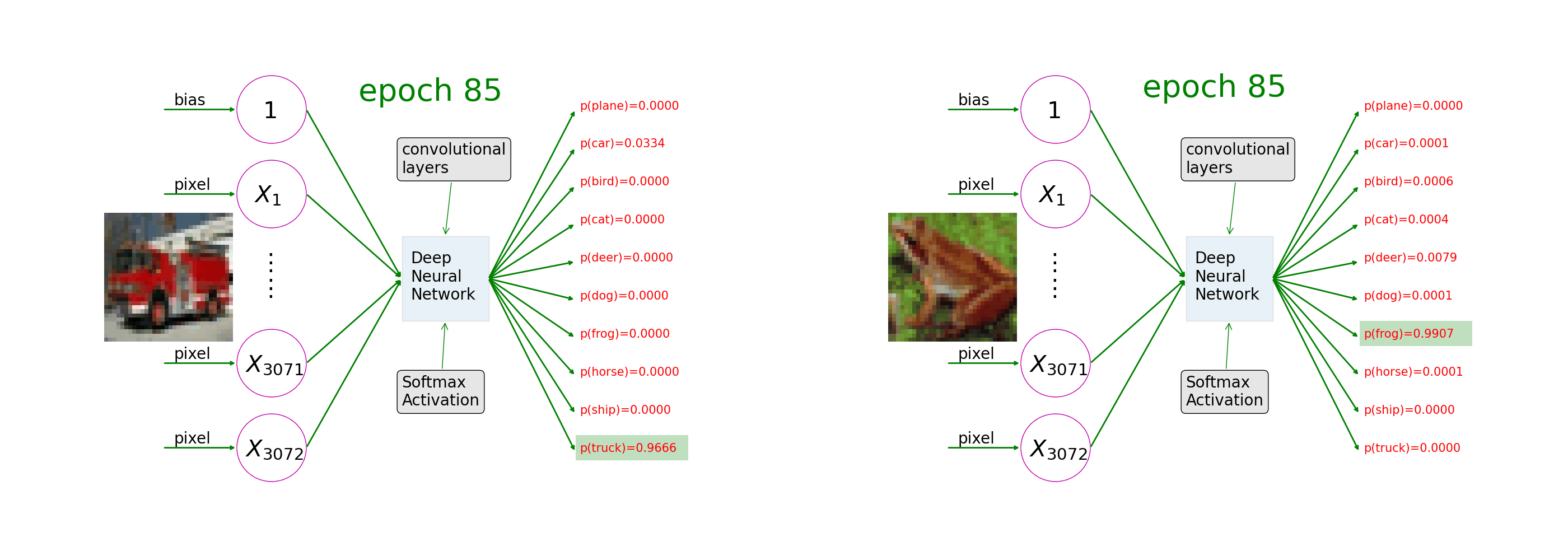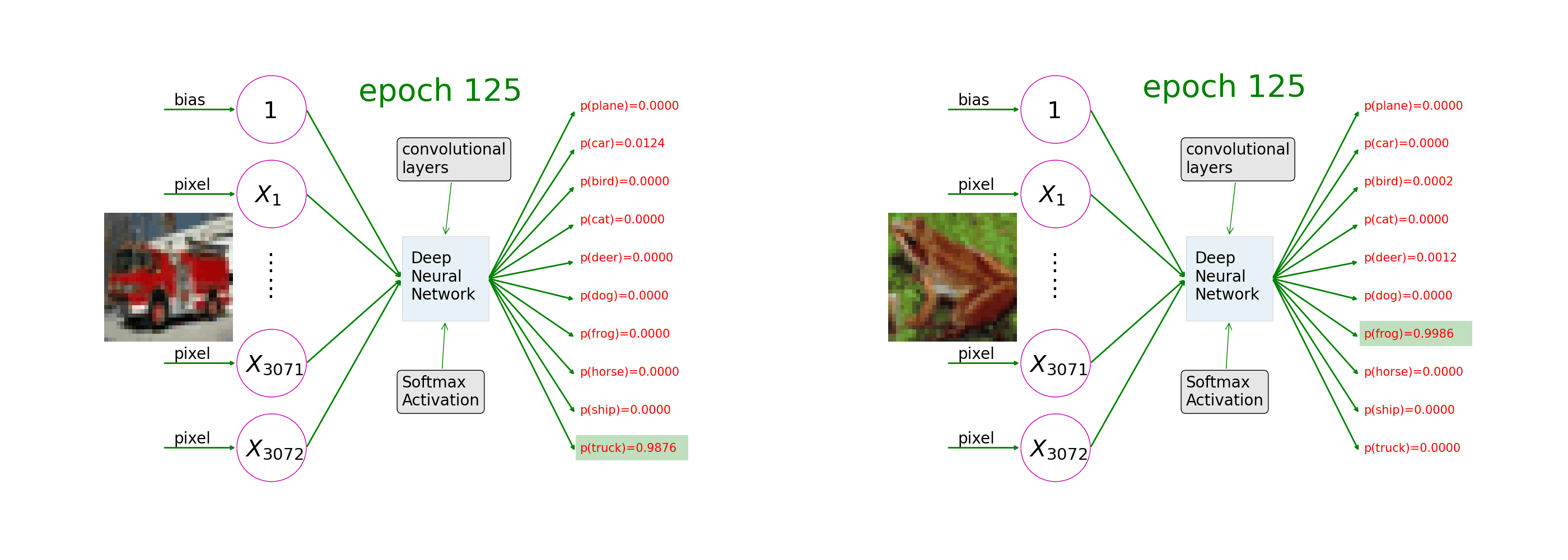
Ch8: Apply Deep Learning to the Frozen Lake Game
Design deep learning game strategies and for the Frozen Lake game in OpenAI Gym. See how the agent uses the trained model to make decisions on what's the best next move. The deep neural network predicts the probability of winning if the agent were to take a certain action hypothetically. The agent picks the action with the highest probability of winning, step by step.

Ch9: Apply Deep Learning to Any Situation
Learn how to creatively apply deep learning to any situation. The Cart Pole game in OpenAI Gym poses a challenge since there is no clear definition of winning and losing. You'll classify the last ten steps as losing and the rest as winning; you'll successfully train the model. The animation shows how the game is played with (right) and without (left) deep learning strategies.
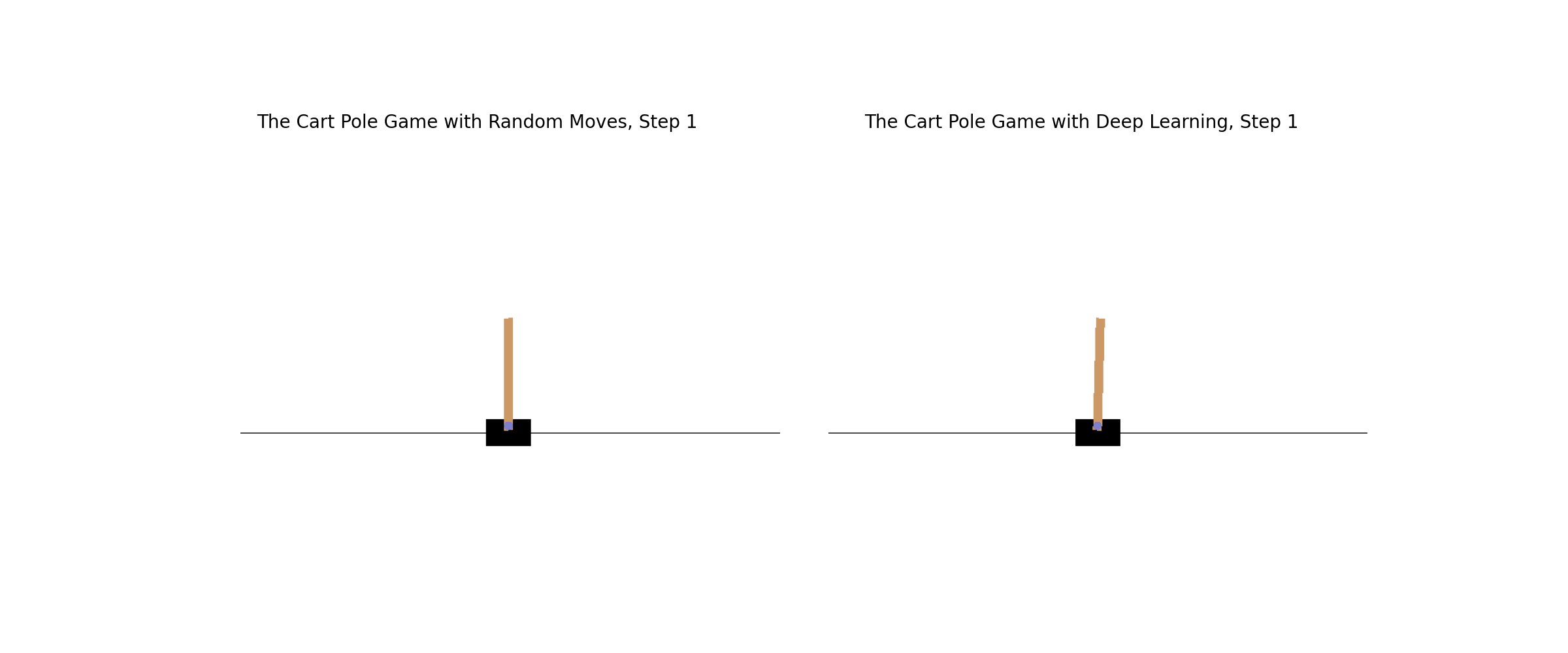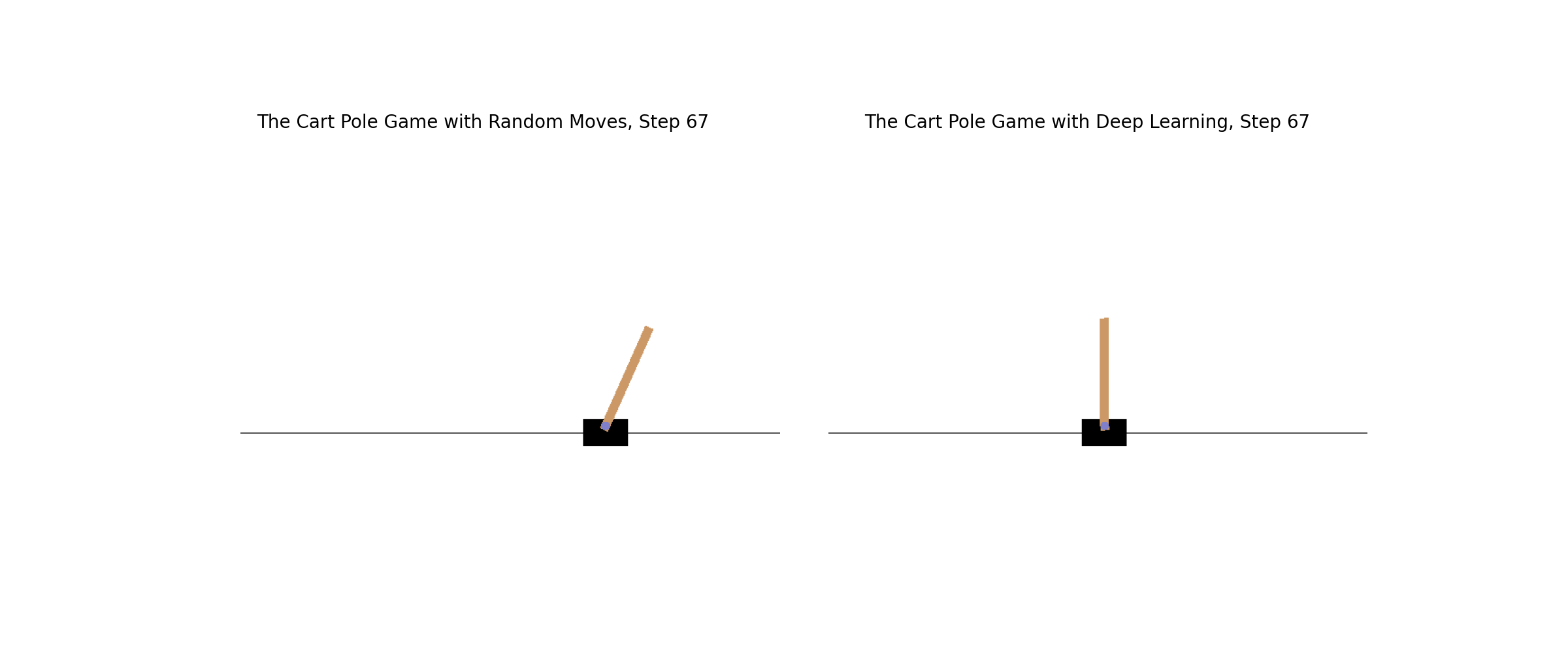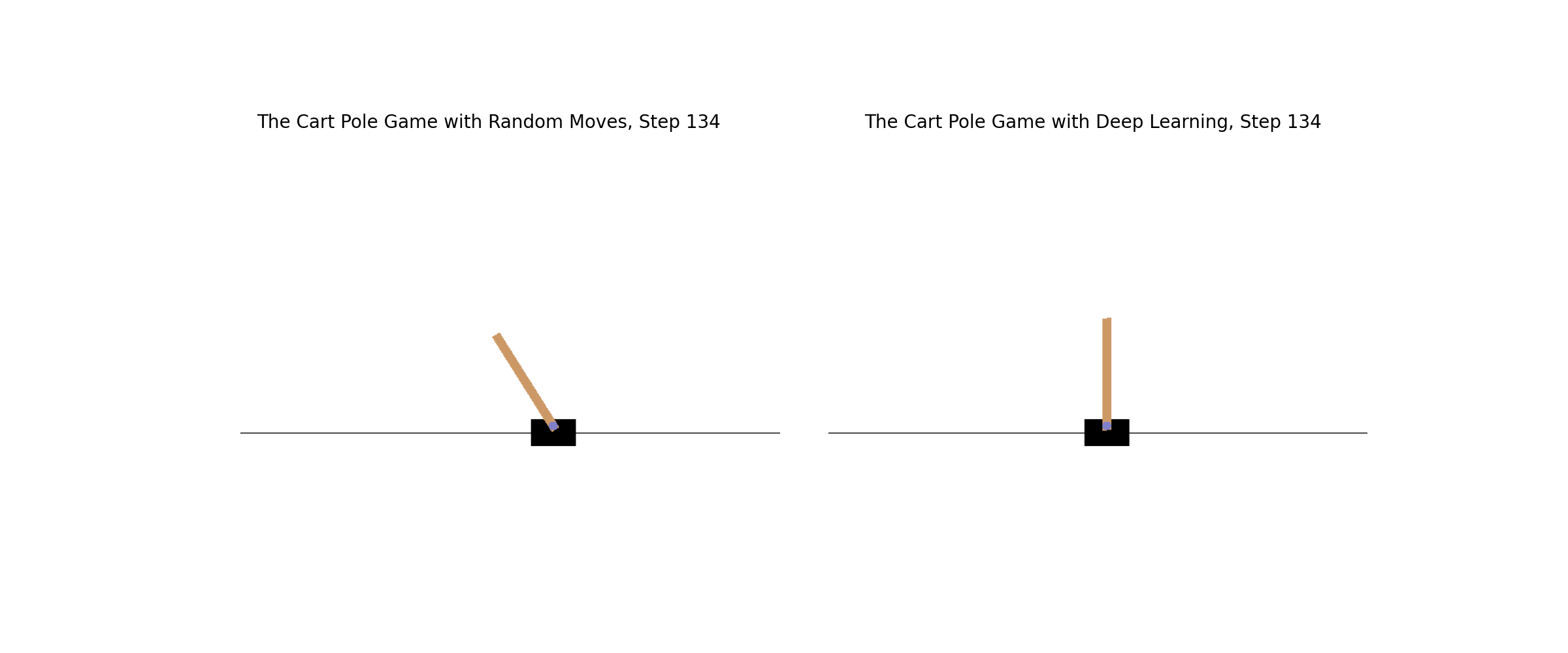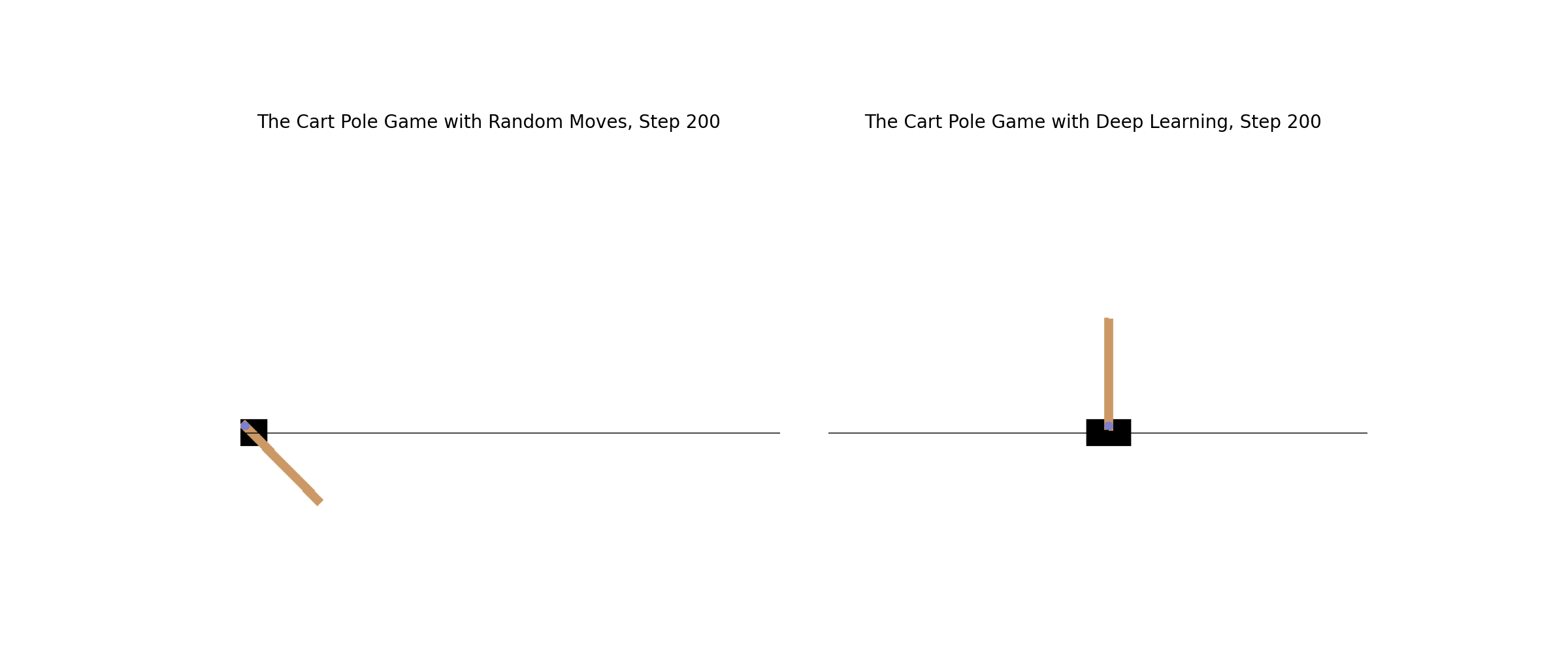
Ch10: Create Your Own Game Environments
Learn to create your own game environments that mimic the OpenAI Gym. The animation below shows your own Frozen Lake game environment, with graphical game boards.
Ch11: Deep Learning Game Strategies: Tic Tac Toe
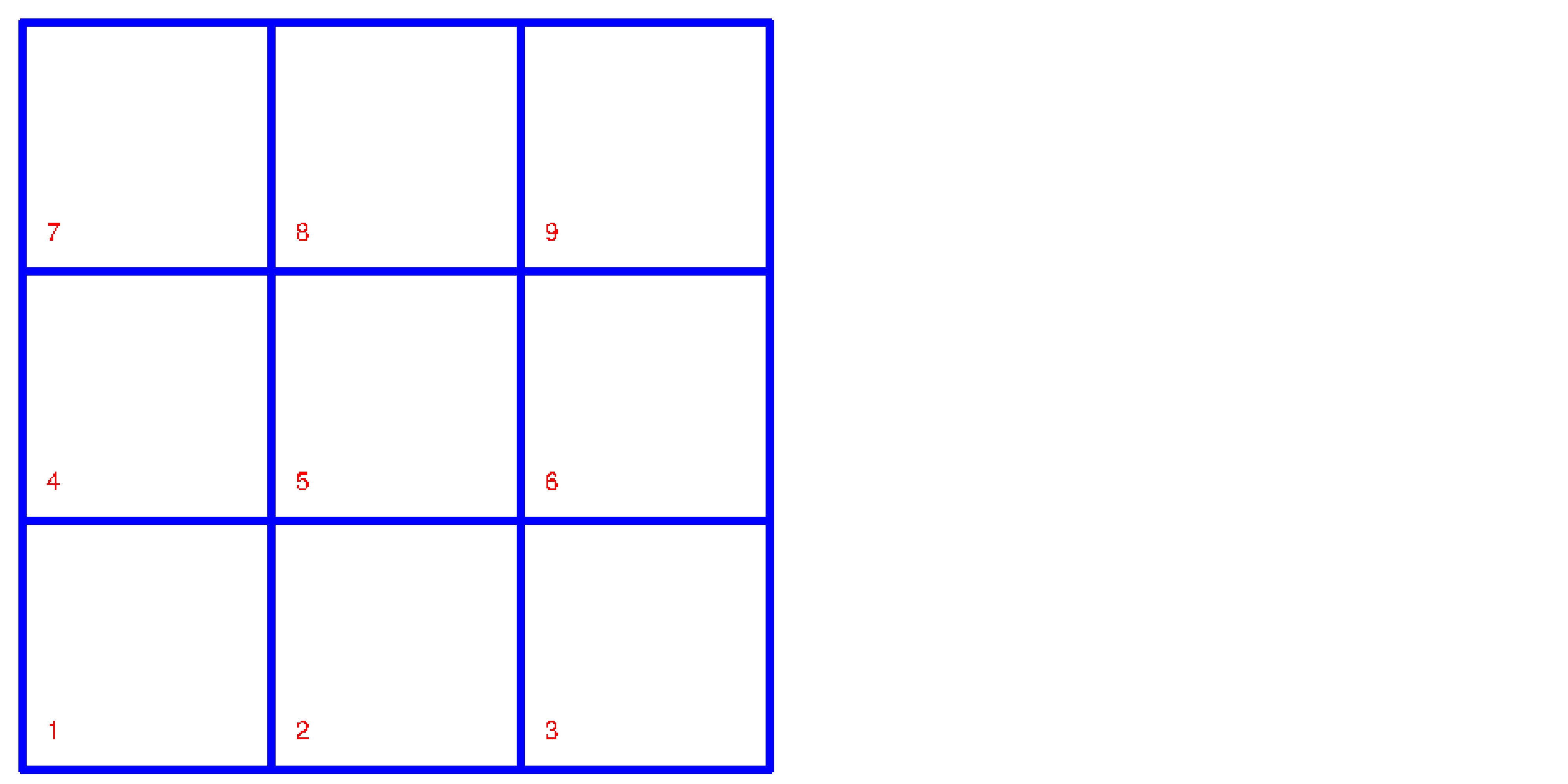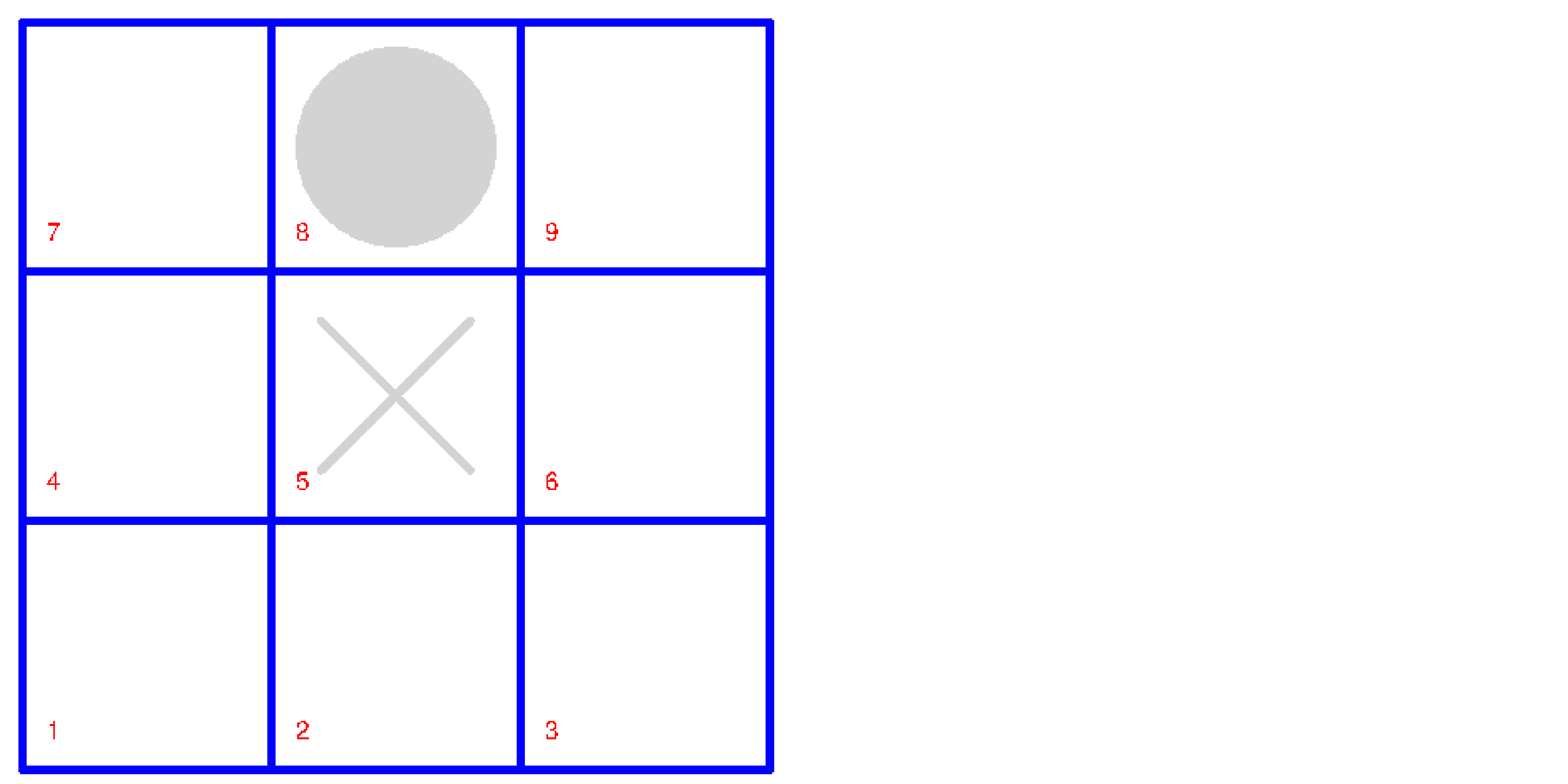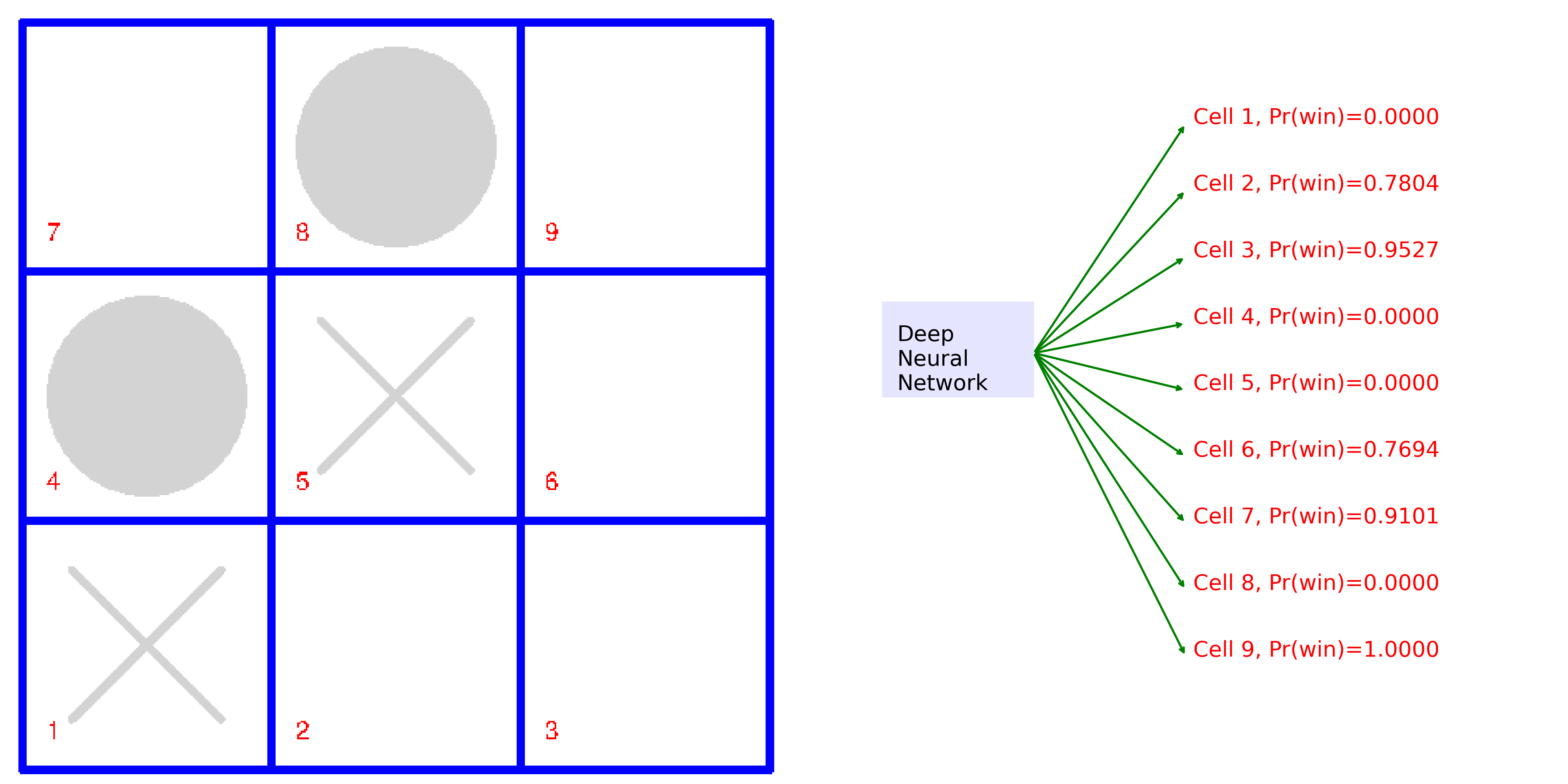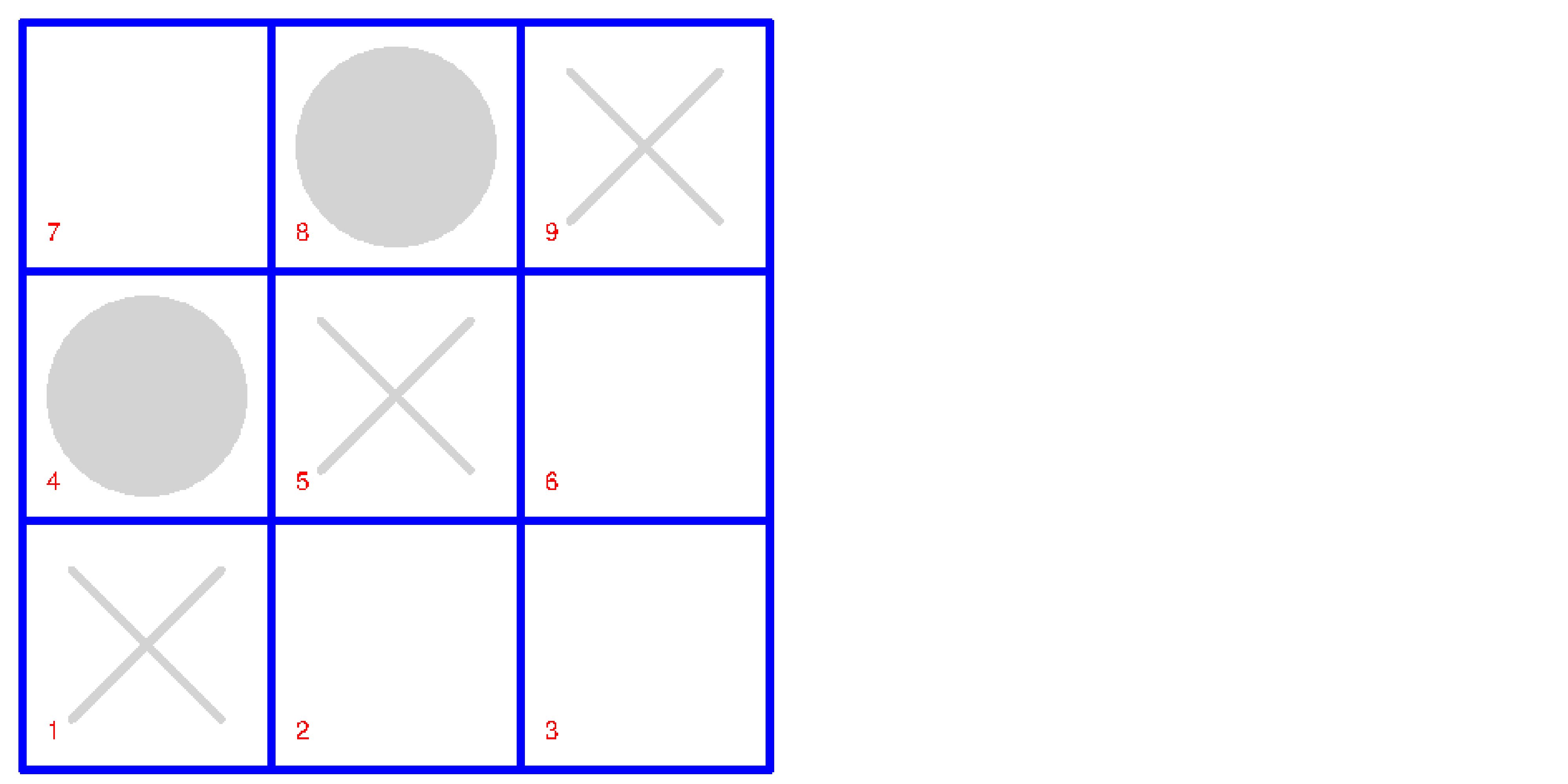
Create a game environment for Tic Tac Toe with all the features of an OpenAI Gym game environment. You'll use deep learning game strategies to play a full game. At each step, the animation shows the game board on the left, and the probability of winning for each next move on the right. The best move is highlighted.
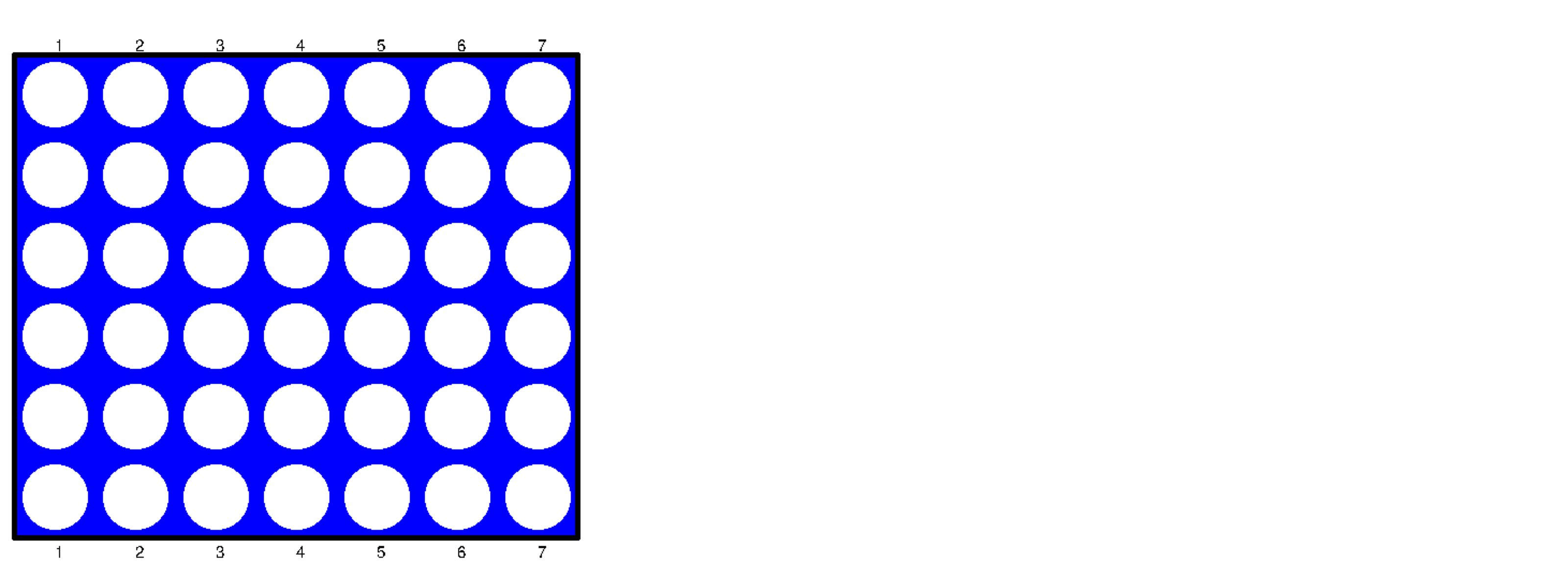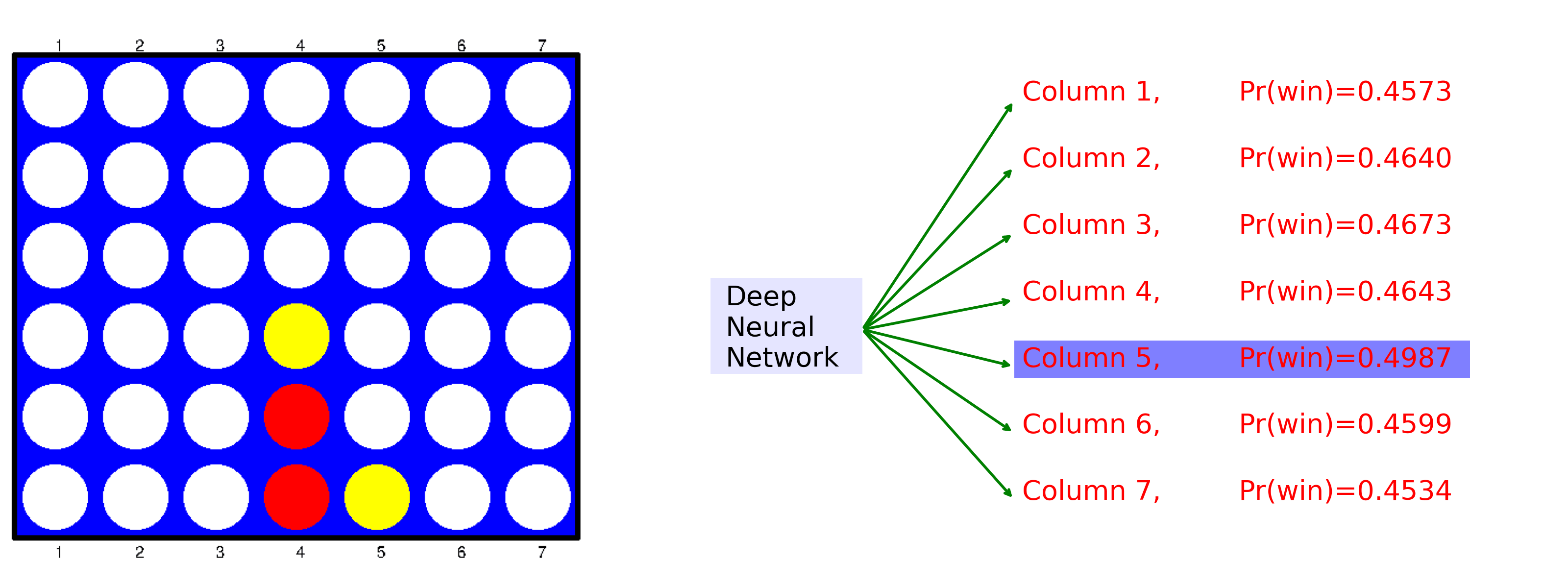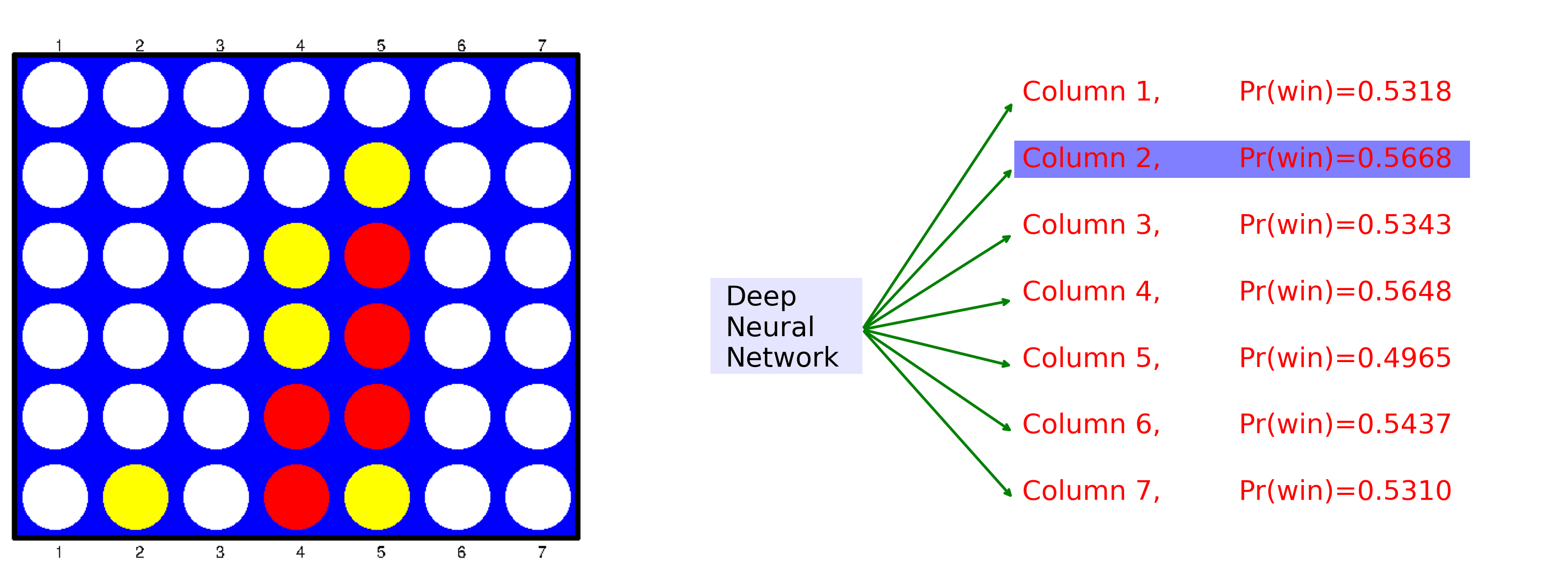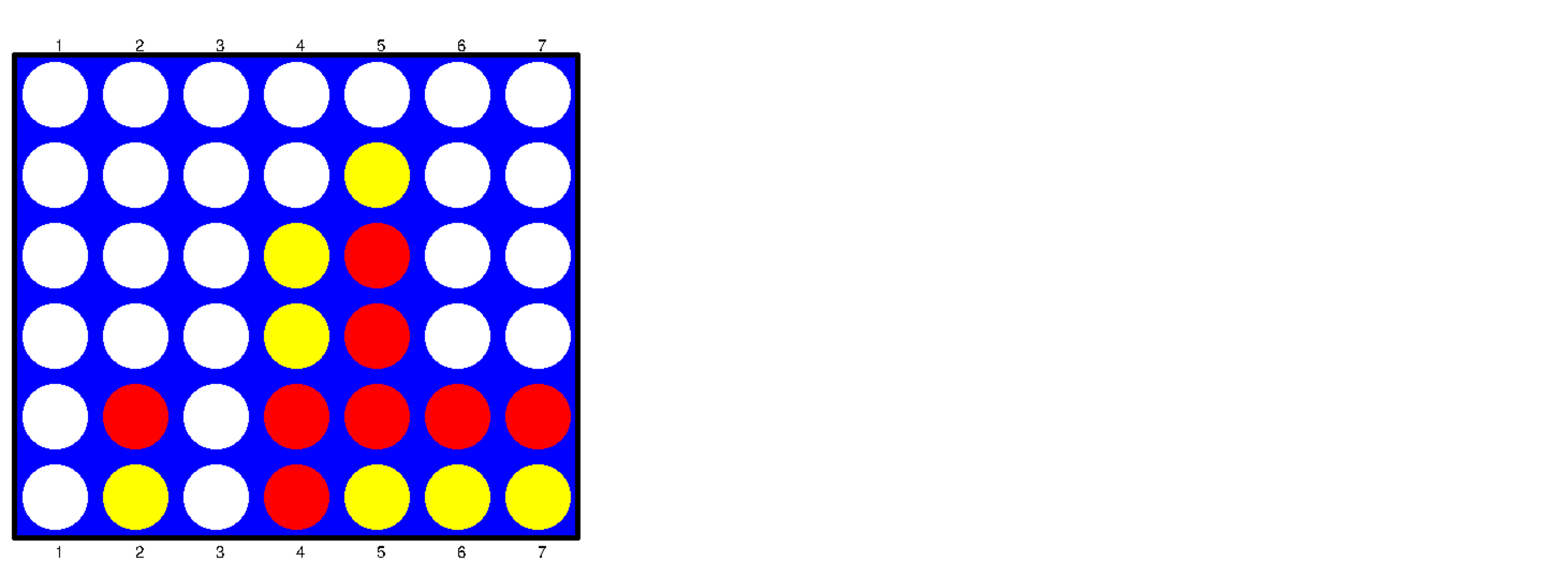
Ch12: Deep Learning Game Strategies: Connect Four
Create a game environment for Connect Four. Use deep learning game strategies to play a full game. At each step, the animation shows the game board on the left, and the probability of winning for each next move on the right. The best move is highlighted.
Ch13: Introduction to Reinforcement Learning
Show in the Frozen Lake game how the tabular Q-learning works in each step of the game. You'll put the game board on the left and the Q-table on the right. You'll highlight the row corresponding to the state and compare the Q-values under the four actions. You'll then highlight the best action.
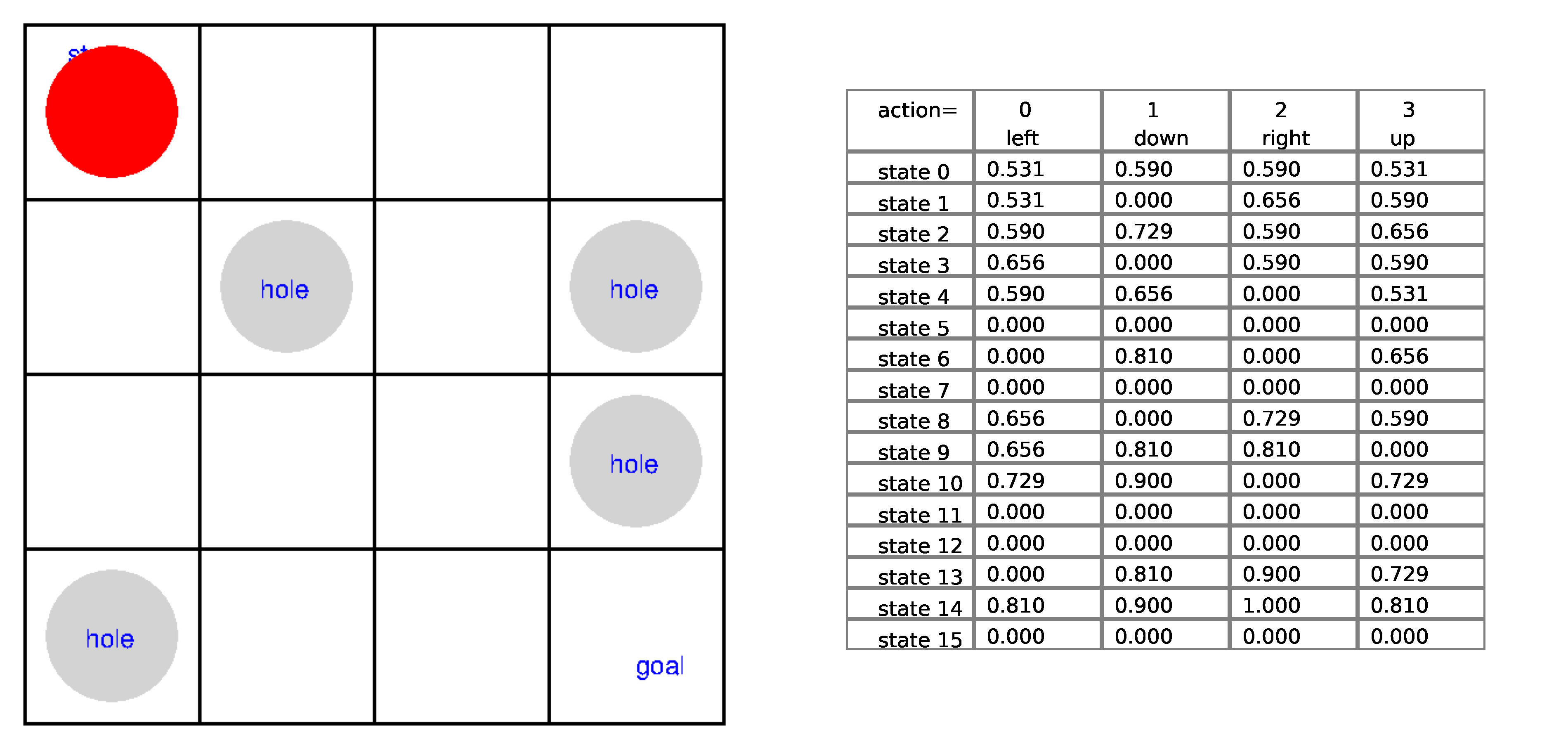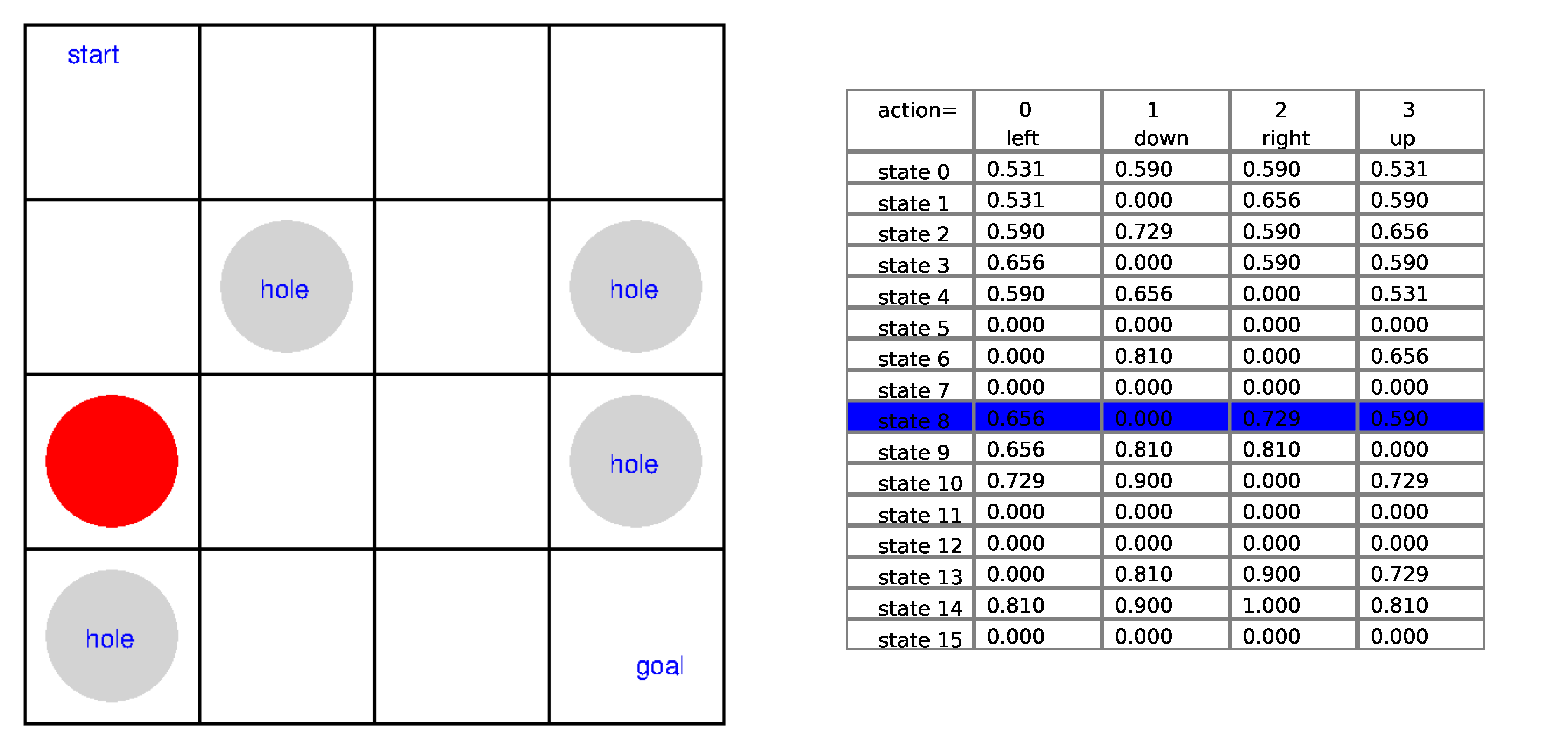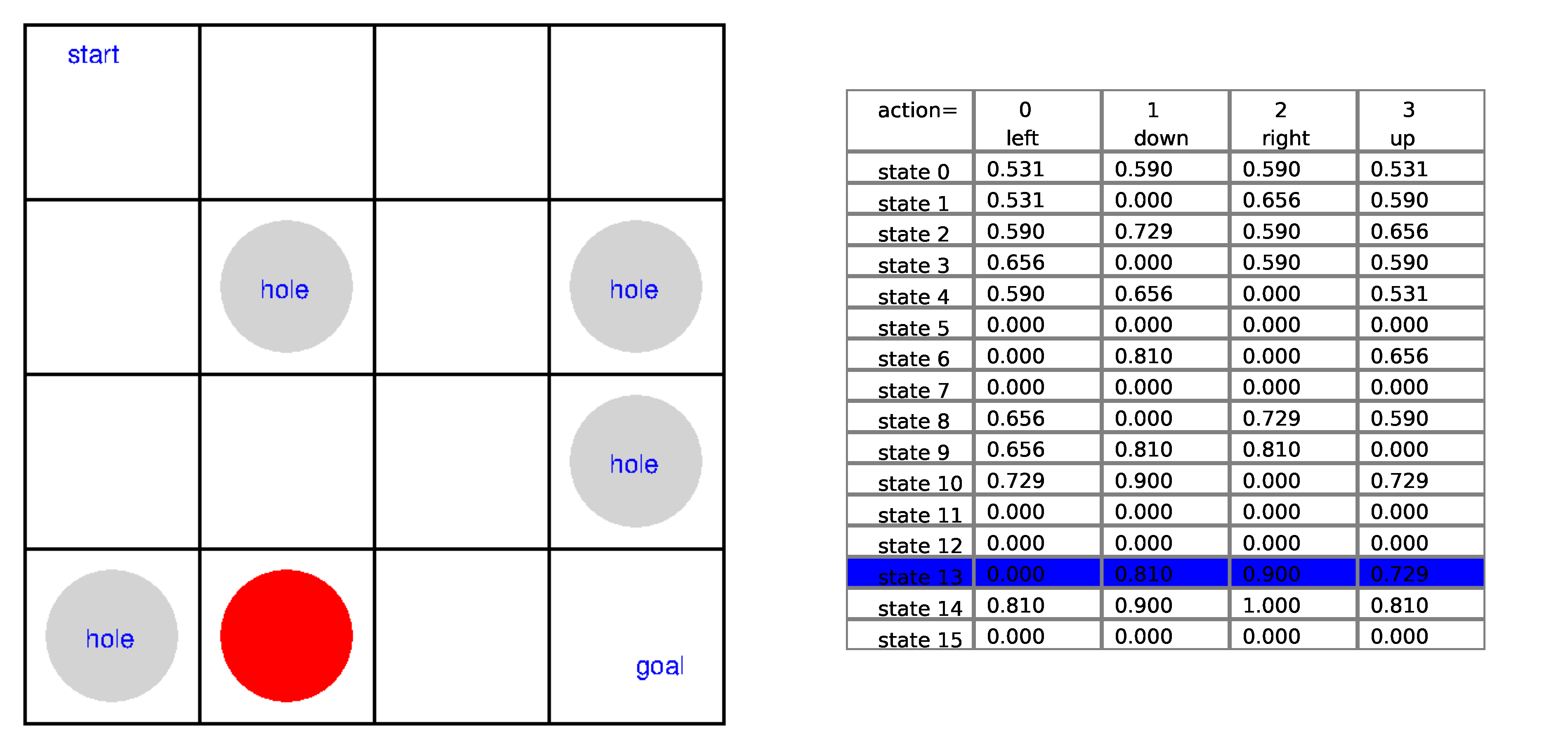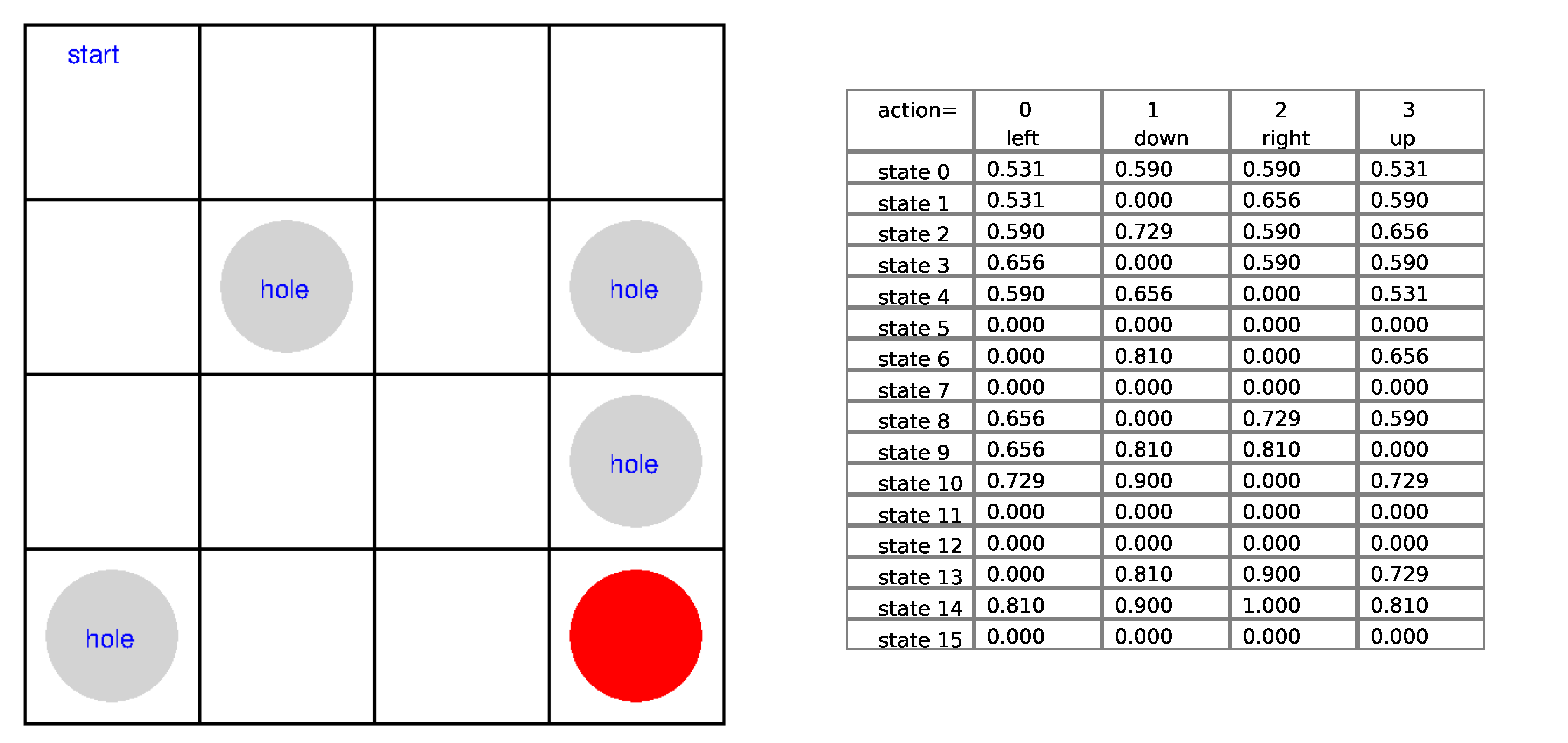
Ch14: Q-Learning with Continuous States
Learn to use a finite number of discrete states to approximate the infinite number of continuous states. Create an animation to compare the mountain car game before and after Q-learning.
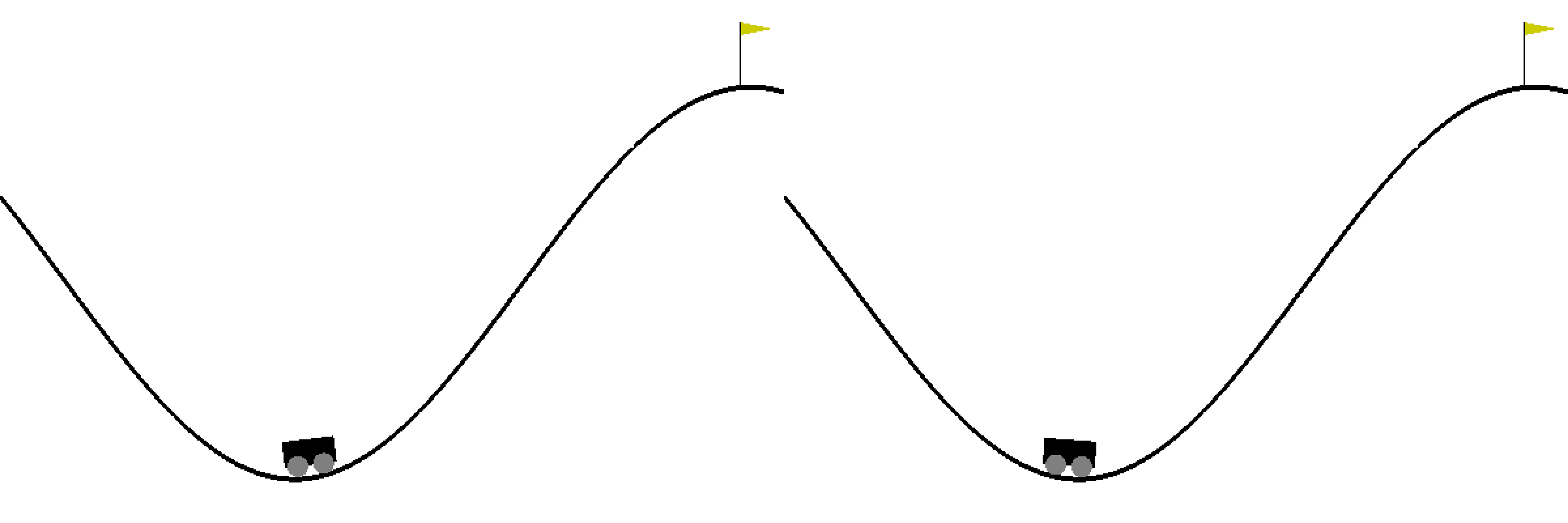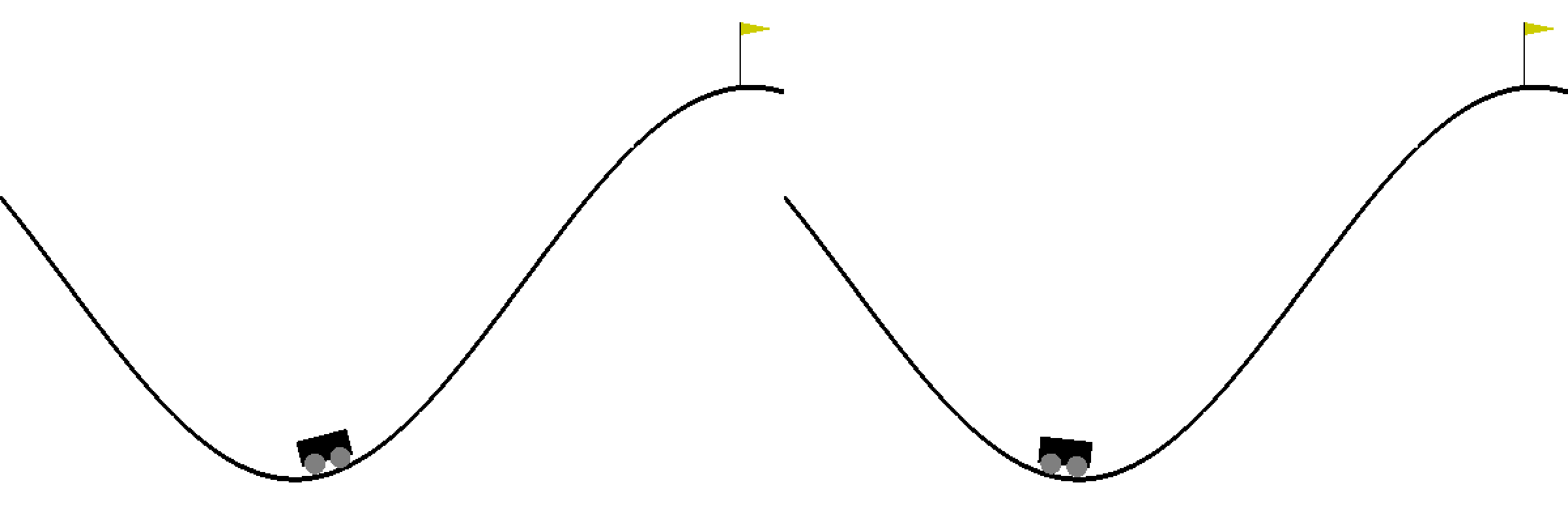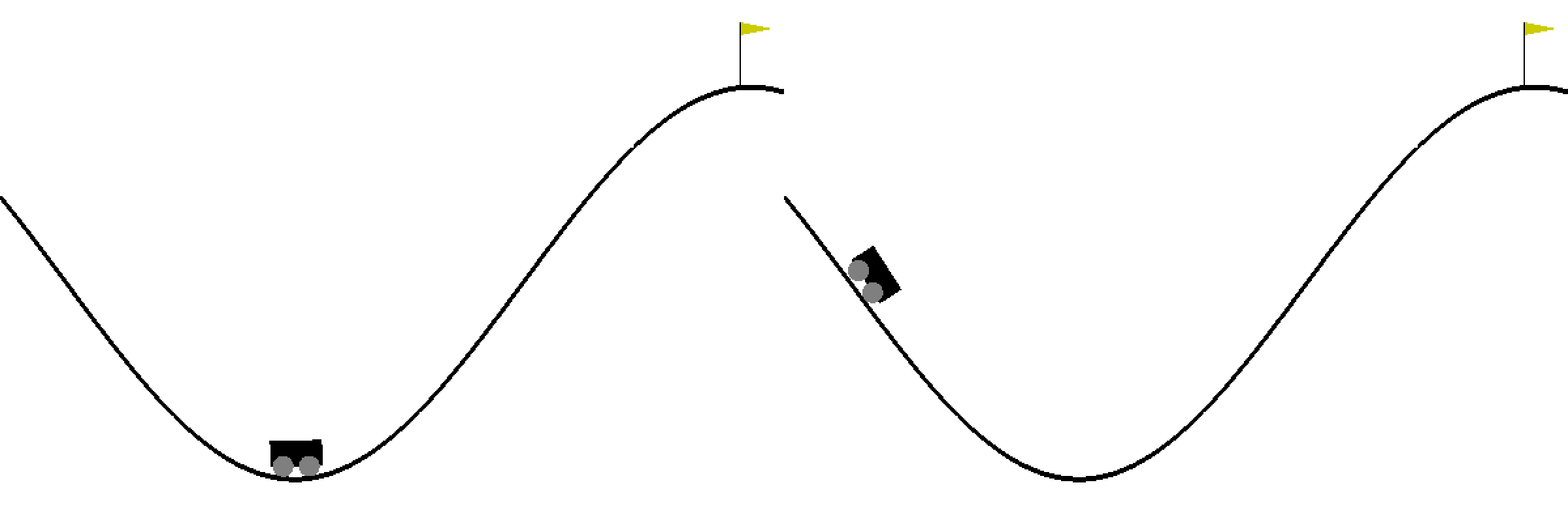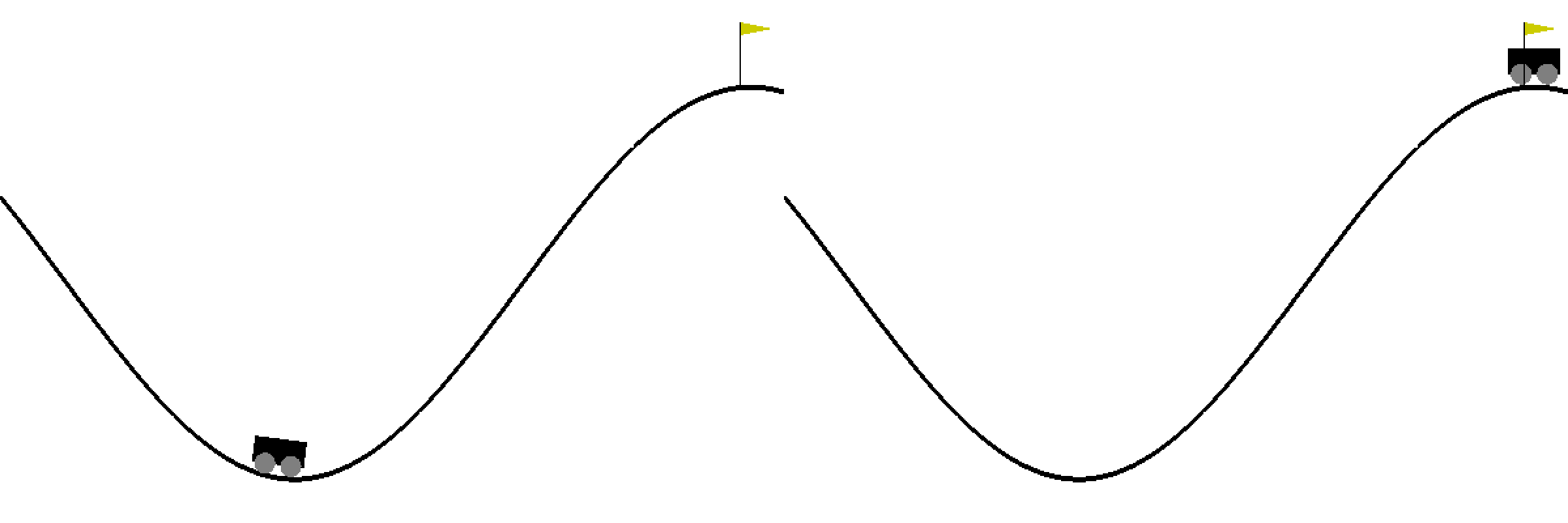
Ch15: Deep Q-Learning
When the number of possible scenarios is too large, we use a deep neural network to approximate the Q values. You'll put the graph of the cart pole on the left. You'll draw on the right the Q-values of moving the cart left and moving the cart right, respectively. The move with higher Q-value is then highlighted in red.
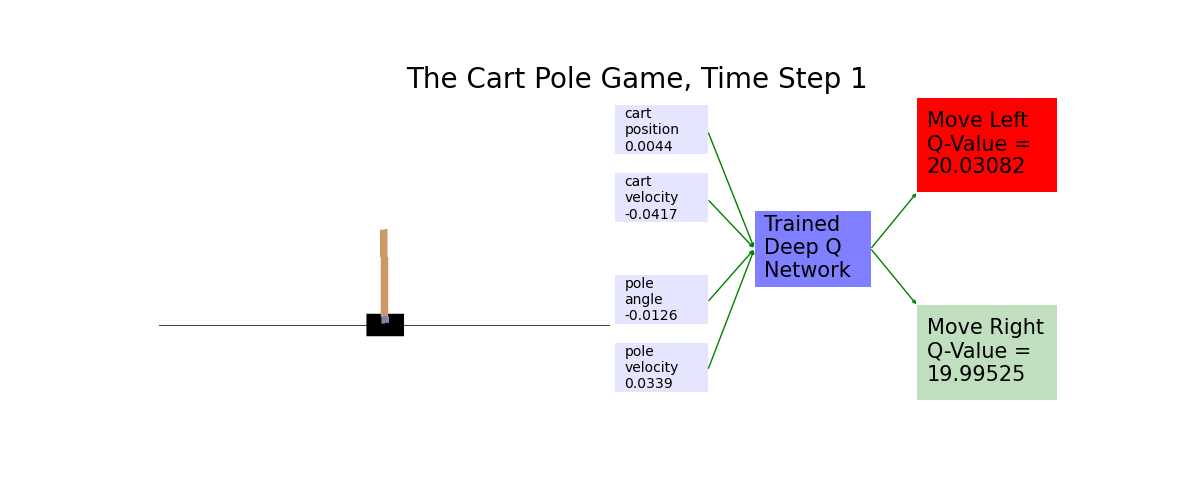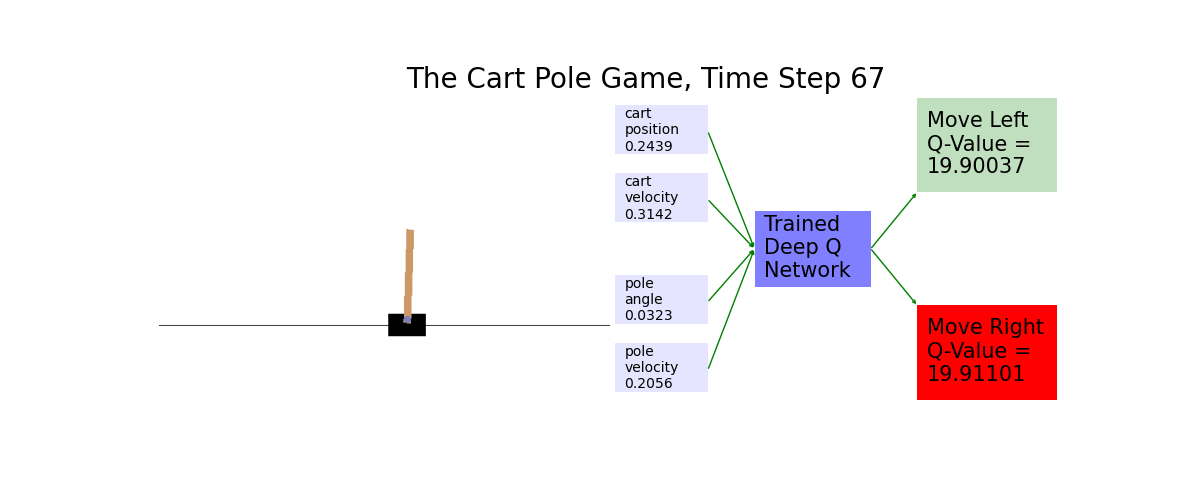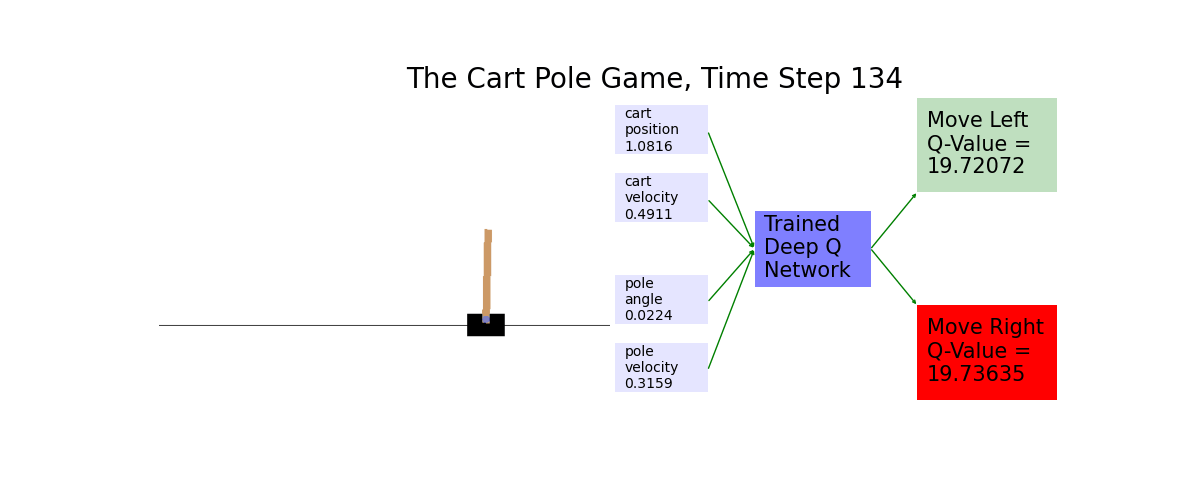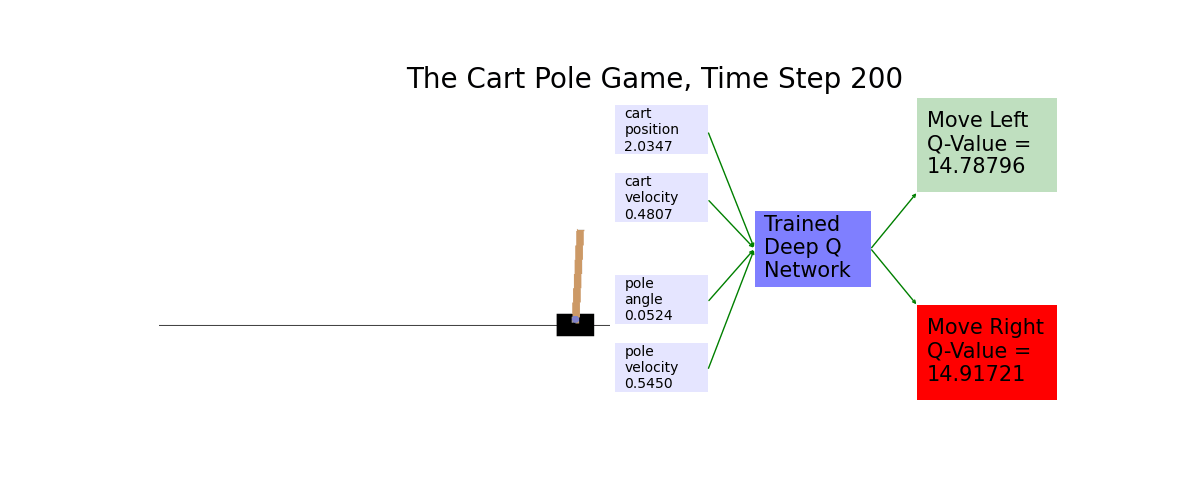
Ch16: Play Atari Pong with Policy Gradients
Use policy gradients to train an agent to play Atari Pong. The left side shows what happens if the agent chooses random moves. The right side shows when the agent is trained with policy gradients. The trained agent plays perfectly, earning a score of 21-0.

Ch17: Play Breakout with Policy Gradients
Extend the policy gradients approach to Atari Breakout. The agent learns to send the ball to the back of the wall to score more efficiently.

Ch18: Double Deep Q Learning
Deep Q learning has a well-known problem of overestimating Q values. To overcome this, we need to use double Q learning. The double deep Q learning can play Atari Games very efficiently. You can see that the agent has sent the ball to the back of the wall five consecutive times. It's clear that the agent has "learned" to do this on purpose because this is a more efficient way of earning rewards than aiming at the bricks directly:
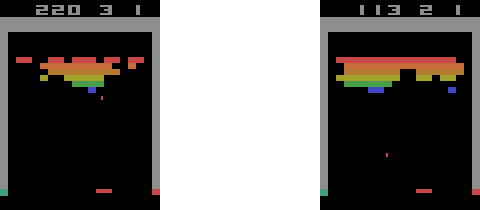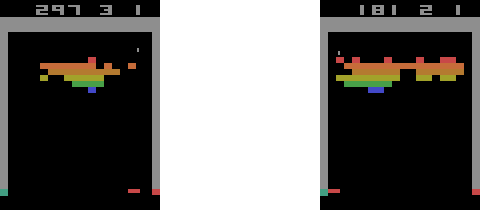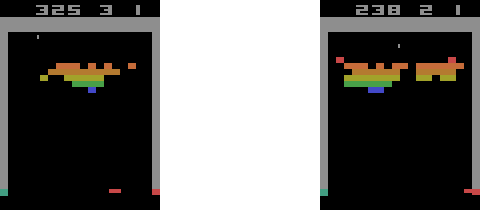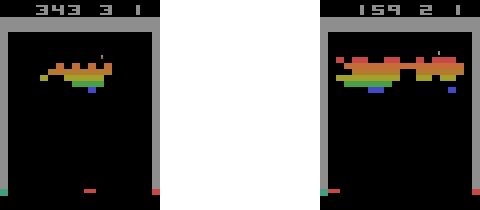
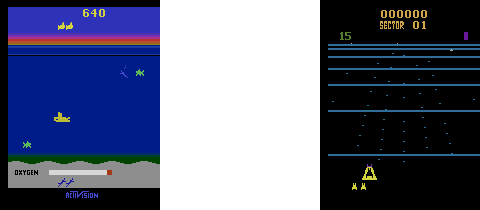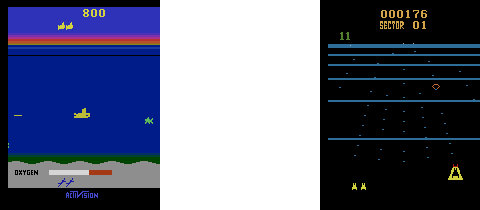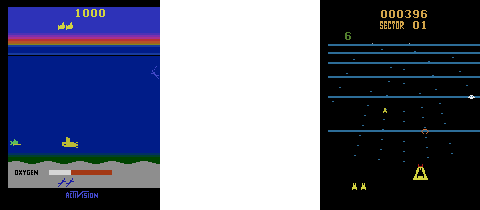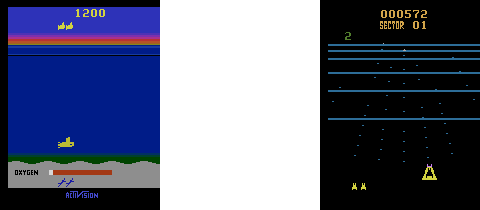
Ch19: Space Invaders with Double Deep Q Learning
Apply double deep Q learning to Space Invaders. The trained agent eliminates all invaders. You'll also learn how to enhance the quality of the graphs so that the animation has four times the resolution as the original OpenAI Gym videos.
Ch20: Scale Up Double Deep Q Learning
You'll learn to scale up the double deep Q network to play any Atari game. To make this point clear, you'll define a function that trains any Atari game with the same deep Q network. All you need is to put in the name of the game as the only argument in the function. Below are trained Seaquest and Beam Rider games.