some issues about data set
In TrainingSetPreparation.py,
 I wonder whats the format of LFPW or HELEN and how to ensure that images corresponding to data?
I wonder whats the format of LFPW or HELEN and how to ensure that images corresponding to data?
You can google and download 300-w dataset, and see the format.
There is a .pts file with the same name of the corresponding photo, the format of the .pts file can be found in the 300-w website.
Thanks.
In the paper, it trained 2 models: DAN and DAN-Menpo. For DAN, it used only 3148 images, so I wonder
is it enough for the training of CNN?
 And for the first question, I found there are some boundingbox files ended with .pkl.
Did you generate these files? And what I should do is to put the images and .pts in the data file?
And for the first question, I found there are some boundingbox files ended with .pkl.
Did you generate these files? And what I should do is to put the images and .pts in the data file?
3000+ images are not enough to train the model, so DAN conduct several data augmentation techniques like random shift, rotate and mirror.
def GeneratePerturbations(self, nPerturbations, perturbations):
Is this function used for data augmentation?
so how many images will be augmented per image?
I see in the code trainSet.GeneratePerturbations(10, [0.2, 0.2, 20, 0.25])#
Does it mean 10 per images?
and...
Can I speak Chinese?
(我能说中文不?)
plt.savefig("../meanImg.jpg")
``TypeError: integer argument expected, got float
这个是怎么回事呢,meanImg这个矩阵的元素是int,怎么还会报错?
meanImg的每个元素都是int,我将plt.savefig("../meanImg.jpg")改为plt.savefig("../meanImg.png")后,就生成了
 但是不知道为什么。
此外运行trainDAN.py会报这个错:
但是不知道为什么。
此外运行trainDAN.py会报这个错:
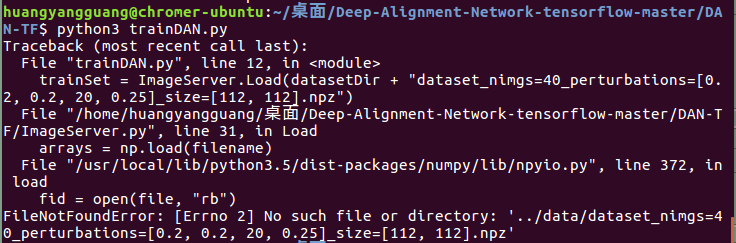
最近想训练这个模型,关于如何运行,是不是先分别run training\testSetPreparation.py这两个文件,生成所需要的.npz然后再去run trainDAN.py?
我在运行testSetPreparation.py时,抛出一个error:
Traceback (most recent call last): File "/home/huangyangguang/PycharmProjects/Deep-Alignment-Network-tensorflow-master/DAN-TF/TestSetPreparation.py", line 20, in <module> commonSet.PrepareData(commonSetImageDirs, commonSetBoundingBoxFiles, meanShape, 0, 1000, False) File "/home/huangyangguang/PycharmProjects/Deep-Alignment-Network-tensorflow-master/DAN-TF/ImageServer.py", line 60, in PrepareData boundingBoxDict = pickle.load(open(boundingBoxFiles[i], 'rb')) UnicodeDecodeError: 'ascii' codec can't decode byte 0xd3 in position 0: ordinal not in range(128)
Emmm,你把commonSetBoundingBoxFiles = ["../data/boxesLFPWTest.pkl", "../data/boxesHelenTest.pkl"]里面对应的pkl改成py3开头的文件即可,我忘了改上去了,不好意思,具体你可以看看data文件夹里py3开头的文件名。
嗯嗯,那这两个也需要改吗? `challengingSetImageDirs = ["../data/images/ibug/"] challengingSetBoundingBoxFiles = ["../data/boxesIBUG.pkl"]
w300SetImageDirs = ["../data/images/300W/01_Indoor/", "../data/images/300W/02_Outdoor/"] w300SetBoundingBoxFiles = ["../data/boxes300WIndoor.pkl", "../data/boxes300WOutdoor.pkl"]`
嗯嗯,按照你说的以后,我得到了以下文件:
 现在的问题是,这四个文件是test和train各两个吗?
具体是怎么使用呢?
比如trainDAN里面:
现在的问题是,这四个文件是test和train各两个吗?
具体是怎么使用呢?
比如trainDAN里面:

恩,我的理解
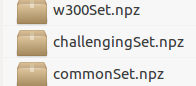 这三个.npz文件用做验证集,然后剩下的那个作为训练集?
现在的问题是感觉我生成的
这三个.npz文件用做验证集,然后剩下的那个作为训练集?
现在的问题是感觉我生成的
 这个训练集里面怎么只有100个数据。。。
那个
这个训练集里面怎么只有100个数据。。。
那个 trainSet.GeneratePerturbations(10, [0.2, 0.2, 20, 0.25])#位移0.2,旋转20度,放缩+-0.25这句是用来数据扩充的吗?那么该如何使用呢?这个训练集的数据量肯定是不对的。
恩,我发现你把trainingSetPreparation.py中trainSet.Save(datasetDir)#保存成字典形式,key为'imgs','initlandmarks','gtlandmarks'这句给注释掉了,无法生成对应的训练集的.npz
此外我run trainDAN.py, 抛出这个错误:
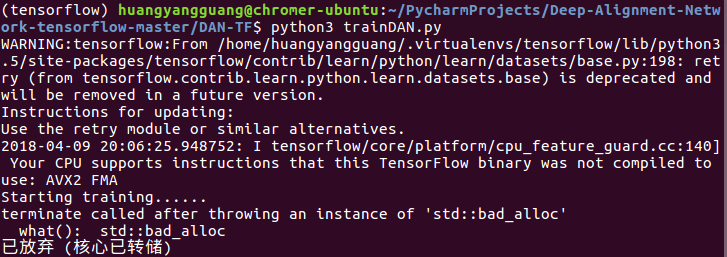

 不知道如何找到你说的1.5.0
不知道如何找到你说的1.5.0
似乎跟validation set有关,在trainDAN.py里面,送入validation set的.npz文件不能太大,我试了一下,有四个.npz文件,其中大小5~7M的都可以train,但是几十M的就会报这个错误。 (我目前没有使用GPU,等明天换到服务器上试试) 另外我有个问题想咨询一下:我现在电脑上有不同的tensorflow的GPU版本,但是要用你的1.5.0gpu版本的tensorflow,在不卸载之后版本的tensorflow情况下,如何操作? 就是担心1.5.0的cuda和cudnn和我之前的不一样。
@Chromer163 跟validationset有关的话,可能是因为数据经模型前传占内存过大,你可以每次测试的时候少一些数据,因为虽然数据几十兆,但是经过网络以后就很大了。
Hi, 我将TrainingSetPreparation.py:13 修改为trainSet.PrepareData(imageDirs, None, meanShape, 100, 100000, True) 生成的训练数据有60960个和DeepAlignmentNetwork原始项目的训练集大小一样,gtx 1080下一次迭代5分钟,我改了batchsize=64。 想咨询一下Landmark68Test函数你没有实现对吧? 这个是zjjMaiMai实现的版本里的吧。 有什么可视化结果的代码吗? @mariolew
@hengshanji 可视化结果就run出landmark的值来,然后画出来即可,绘图的代码与tensorflow没有关系,你用原作者的代码绘图也可以的。