webooru
 webooru copied to clipboard
webooru copied to clipboard
使用HaarCascade进行人脸识别_wutao1530663的博客-CSDN博客_haarcascade
![]()
wutao02 2017-10-20 13:19:22  8550
8550  收藏 14
收藏 14
最后发布: 2017-10-20 13:19:22 首发: 2017-10-20 13:19:22
前言
学完了 deeplearnning.ai 的卷积神经网络课程之后,为了更直观的理解人脸识别,我想使用 openCV 来实现人脸识别。(以下为译文)
目的
- 我们将学习基于 Haar 特征的人脸识别分类器的一些基础知识
- 我们还会将人脸识别扩展到人眼识别等
基础
基于 Haar 特征的 cascade 分类器 (classifiers) 是 Paul Viola 和 Michael Jone 在 2001 年,论文”Rapid Object Detection using a Boosted Cascade of Simple Features” 中提出的一种有效的物品检测 (object detect) 方法。它是一种机器学习方法,通过许多正负样例中训练得到 cascade 方程,然后将其应用于其他图片。
现在让我们来看以下人脸识别是如何工作的。首先,算法需要许多正样例 (包含人脸的图片) 和负样例 (不包含人脸的图片) 来训练分类器。然后我们要从这些图片中获取特征 (extract features)。如下所示为 Haar 特征获取的方式。和卷积核 (conventional kernel) 类似,每个特征由白方块下的像素和减去黑方块的像素和来得到。
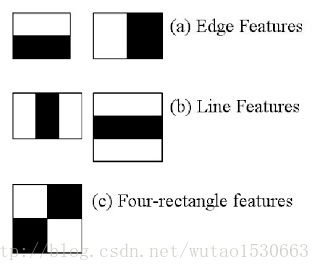
每个核 (kernel) 所有可能的尺寸和位置计算得到了大量特征。(想象一下有多少特征?24x24 尺寸的滑动窗口特征数就超过 160000)。对于每个特征我们都需要计算白方块和黑方块的像素和。为了解决大量计算的问题,有人引入了积分图像 (intergal images) 的概念。它大大简化了像素和的计算,大约只需要像素数目数量级的运算,每次运算只涉及到 4 个像素。很棒吧?这让一切都变得超级快。
在我们计算的所有特征中,大部分特征是无关紧要的。比如下图这个例子。 顶上一行表示两个不错的特征,第一个特征似乎是根据眼睛所在位置通常比脸颊和鼻子更黑来选择,而第二个特征选择的依据则是眼睛比鼻梁要黑。因此,相同的窗口用于脸颊或者其他部位时就没有意义了。那么我们如何从超过 16 万个的特征中选择最好的特征呢?我们可以使用 Adaboost 来实现。

因此,我们将每个特征都应用于所有训练集图片中,对于每个特征,找出人脸图片分类效果最好的阈值。显然,分类会有误分类,我们选择分类错误率最小的那些特征,也就是说这些特征可以最好的将人脸图片和非人脸图片区分开。(实际上没有那么简单,每个图片初始时给定相同的权重。每次分类后,提升被分类错误图片的权重。然后再根据新的权重分类,计算出新的错误率和新的权重,直到错误率或迭代次数达到要求即停止 (译注: 实际上就是 Adaboost 的流程))。
最终的分类器是这些弱分类器的加权和。之所以称之为弱分类器是因为每个分类器不能单独分类图片,但是将他们聚集起来就形成了强分类器。论文表明,只需要 200 个特征的分类器在检测中的精确度达到了 95%。最终的分类器大约有 6000 个特征。(将超过 160000 个特征减小到 6000 个,这是非常大的进步了)
假设现在你有一张图片,使用 24x24 的滑动窗口,将 6000 个特征应用于图片来检测图片是否为人脸。嗯…. 这是不是有点效率低下,浪费时间?确实是的,不过作者自有妙计。
事实上,一张图片中大部分的区域都不是人脸。如果能找到一个简单的方法能够检测某个窗口是不是人脸区域,如果该窗口不是人脸区域,那么就只看一眼便直接跳过,也就不用进行后续处理了,这样就能集中精力判别那些可能是人脸的区域。
为此,有人引入了 Cascade 分类器。它不是将 6000 个特征都用在一个窗口,而是将特征分为不同的阶段,然后一个阶段一个阶段的应用这些特征 (通常情况下,前几个阶段只有很少量的特征)。如果窗口在第一个阶段就检测失败了,那么就直接舍弃它,无需考虑剩下的特征。如果检测通过,则考虑第二阶段的特征并继续处理。如果所有阶段的都通过了,那么这个窗口就是人脸区域。
作者的检测器将 6000 + 的特征分为了 38 个阶段,前五个阶段分别有 1,10,25,25,50 个特征 (前文图中提到的两个特征实际上是 Adaboost 中得到的最好的两个特征)。根据作者所述,平均每个子窗口只需要使用 6000 + 个特征中的 10 个左右。
以上就是 Viola-Jones 人脸识别的工作原理简述,阅读其论文可以得到更多的细节。
OpenCV 中的 Haar-cascade 检测
OpenCV 既可以作为检测器也可以进行训练。如果你打算训练自己的分类器识别任意的物品,比如车,飞机等。你可以用 OpenCV 创造一个。完整的细节在:Cascade Classifier Training¶中。
这里我们只说如何使用它的检测器功能。OpenCV 已经包含许多训练好的分类器,比如脸、眼、微笑等。这些 XML 文件存储在 opencv/data/haarcascades / 文件夹中。让我们用 OpenCV 创建一个脸部和眼部检测器吧!
首先我们需要加载需要的 XML 分类器。然后在灰度模式下加载我们的输入文件。
import numpy as np
import cv2
face_cascade = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')
eye_cascade = cv2.CascadeClassifier('haarcascade_eye.xml')
img = cv2.imread('sachin.jpg')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
现在我们就能从图片中找到人脸了。如果识别出人脸,会以 Rect(x,y,w,h) 的形式返回脸部的位置,然后我们可以用一个矩形网格标识人脸,然后在这个矩形网格之间应用眼部识别 (因为眼睛一定在脸上!)
结果如下图所示。(译注: 使用 OpenCV 自带的人脸识别时,当人脸角度有些倾斜时很难识别到人脸,以后有机会希望可以研究并解决这个问题)

https://blog.csdn.net/wutao1530663/article/details/78294349