webooru
 webooru copied to clipboard
webooru copied to clipboard
神经网络模型(Backbone) - silence_cho - 博客园
自己搭建神经网络时,一般都采用已有的网络模型,在其基础上进行修改。从 2012 年的 AlexNet 出现,如今已经出现许多优秀的网络模型,如下图所示。 主要有三个发展方向:
Deeper:网络层数更深,代表网络 VggNet
Module: 采用模块化的网络结构(Inception),代表网络 GoogleNet
Faster: 轻量级网络模型,适合于移动端设备,代表网络 MobileNet 和 ShuffleNet
Functional: 功能型网络,针对特定使用场景而发展出来。如检测模型 YOLO,Faster RCNN;分割模型 FCN, UNet

其发展历史可以分为三个阶段:

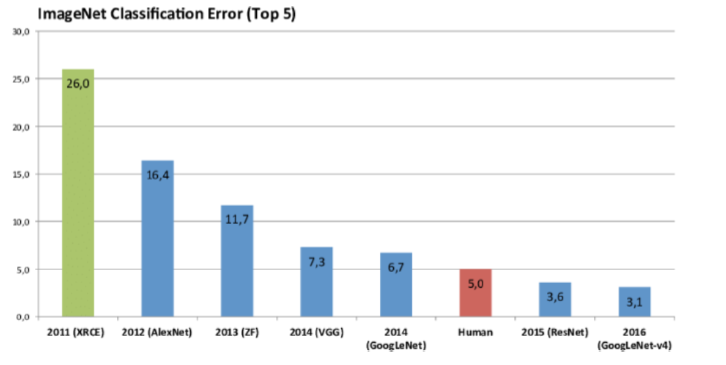
这些模型在 ImageNet 上的表现效果对比如下:
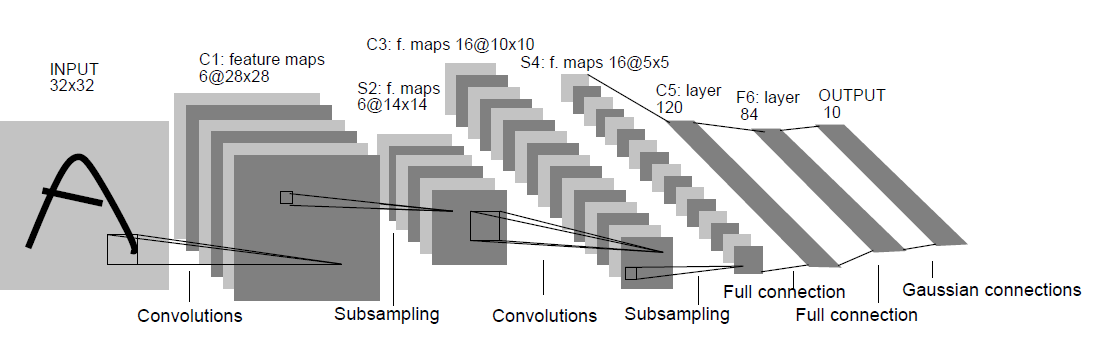
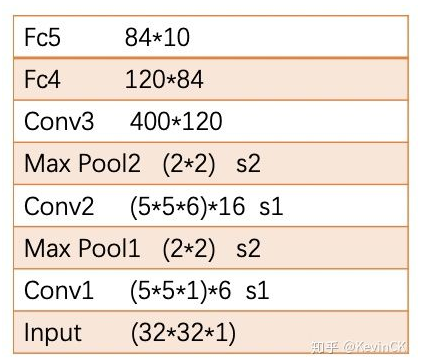
- LeNet-5
LeNet-5 是 LeCun 在 1998 年的论文中Gradient-Based Learning Applied to Document Recognition 提出的网络模型,其结构如下:(其中卷积为 5*5 的 kernel,下采样为 2*2 的 MaxPooling),其结构比较简单,关于 LeNet-5 结构设计的详细分析,参见:参考一,参考二
** 2. AlexNet**
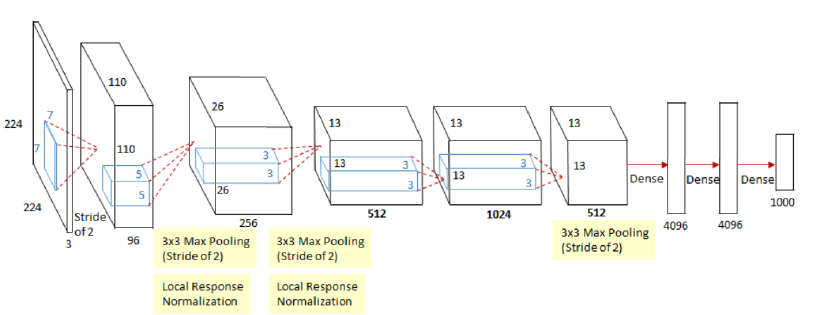
AlexNet 是 Alex Krizhevsky 在 2012 的文章 ImageNet Classification with Deep Convolutional Neural Networks 中提出,其结构模型如下:(分上下两部分卷积,计算力不足,放在两块 GPU 上)
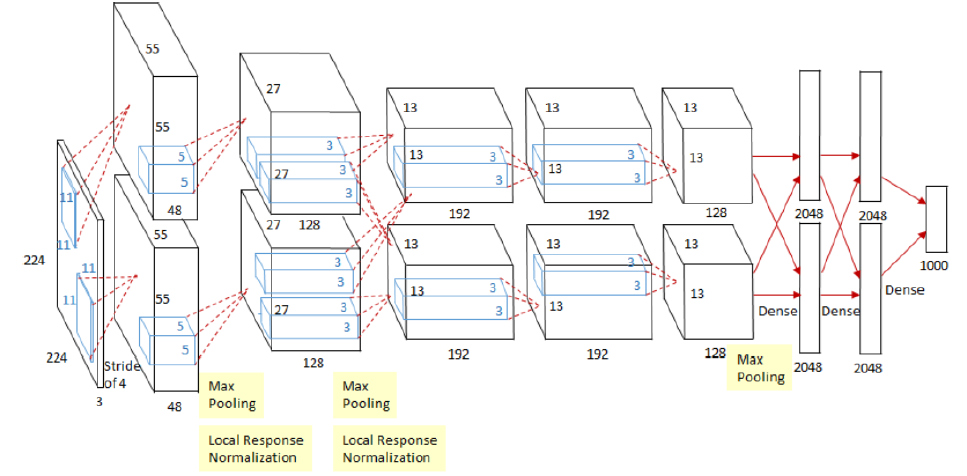

(1) Training on Multiple Gpus: 受于当时的算力限制,Alexnet 创新地将图像分为上下两块分别训练,然后在全连接层合并在一起
(2) ReLU Nonlinearity: 采用 ReLU 激活函数代替 Sigmoid 或 tanh, 解决了梯度饱和的问题
(3)Local Response Normalization: 局部响应归一化,
(4) Data Augmentation: 扩增数据,减小过拟合:第一种是 抠图(从 256x256 抠出 224x224)加上水平反转。第二种是 改变 RGB 颜色通道强度。
(5) Dropout: 以一定概率舍弃神经元输出,减小过拟合。
3.ZFNet
ZFNet 是 2013 年的论文Visualizing and Understanding Convolutional Networks中提出,是 2013 年 ILSVRC 的冠军。这篇文章使用反卷积(Deconvnet),可视化特征图(feature map),通过可视化 Alex-net 指出了 Alex-net 的一些不足,最后修改网络结构,使得分类结果提升;是 CNN 领域可视化理解的开山之作,作者通过可视化解释了为什么 CNN 有非常好的性能、如何提高 CNN 性能,然后进行调整网络,提高了精度(参考文章)
ZFNet 通过修改结构中的超参数来实现对 AlexNet 的改良,具体说来就是增加了中间卷积层的尺寸,让第一层的步长和滤波器尺寸更小。其网络结构的两种表示图如下:
相比于 AlexNet 其改进如下:(ImageNet top5 error:16.4% 提升到 11.7%)
(1) Conv1: 第一个卷积层由(11*11, stride=4)变为(7*7,stride=2)
(2) Conv3, 4, 5: 第三,四,五个卷积核的通道数由 384,384,256 变为 512,1024,512
** 3. VGGNet**
VGGNet 是 2014 年论文Very Deep Convolutional Networks for Large-scale Image Recognition 中提出,2014 年的 ImageNet 比赛中,分别在定位和分类跟踪任务中取得第一名和第二名,其主要的贡献是展示出网络的深度(depth)是算法优良性能的关键部分,其结构如下:
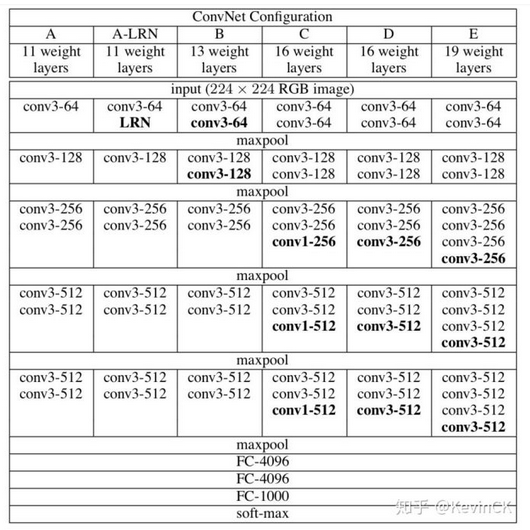
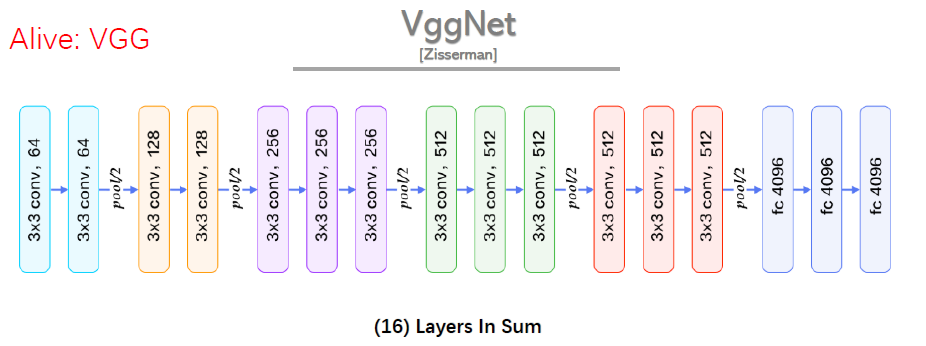
(1) 结构简洁:5 层卷积层、3 层全连接层、softmax 输出层构成,层与层之间使用 max-pooling(最大化池)分开,所有隐层激活单元都采用 ReLU 函数。
(2) 小卷积核和多卷积核:VGG 使用多个较小卷积核(3x3)的卷积层代替一个卷积核较大的卷积层,一方面可以减少参数,另一方面相当于进行了更多的非线性映射,可以增加网络的拟合 / 表达能力。
VGG 的作者认为两个 3x3 的卷积堆叠获得的感受野大小,相当一个 5x5 的卷积;而 3 个 3x3 卷积的堆叠获取到的感受野相当于一个 7x7 的卷积。这样可以增加非线性映射,也能很好地减少参数(例如 7x7 的参数为 49 个,而 3 个 3x3 的参数为 27),如下图所示:

VGGNet 提出的结论:
(1) LRN 层无性能增益(A-LRN):AlexNet 曾经用到的 LRN 层(local response normalization,局部响应归一化)并没有带来性能的提升
(2) 随着深度增加,分类性能逐渐提高(从 11 层到 19 层)
(3) 多个小卷积核比单个大卷积核性能好
4. GoogLeNet
4.1 GoogLeNet V1
GoogLetNet V1 是在 2014 年论文Going deeper with convolutions中提出的,ILSVRC 2014 的胜利者。相比于 VGG,其并不是单纯的将网络加深,还引入了 Inception 模块的概念,最终性能和 VGG 差不多,但参数量更少。
Inception 提出原因:传统网络为了减少参数量,减小过拟合,将全连接和一般卷积转化为随机稀疏连接,但是计算机硬件对非均匀稀疏数据的计算效率差,为了既保持网络结构的稀疏性,又能利用密集矩阵的高计算你性能,Inception 网络结构的主要思想是寻找用密集成分来近似最优局部稀疏连接,通过构造一种 “基础神经元” 结构,来搭建一个稀疏性、高计算性能的网络结构
Inception 的结构如下图所示:

Inception 架构特点:
(1) 加深的基础上进行加宽,稀疏的网络结构,但能产生稠密的数据,既能增加神经网络表现,又能保证计算资源的使用效率
(2) 采用不同大小的卷积核意味着不同的感受野,最后在 channel 上拼接,意味着不同尺度的特征融合
(3) 采用 1*1 卷积,一是减少维度来减少计算量和参数,二是修正线性激活,增加非线性拟合能力(每个 1*1 后都有 ReLU 激活函数)
以 Inception 为基础模块,GoogLeNet V1 的整体网络架构如下(共 22 层):

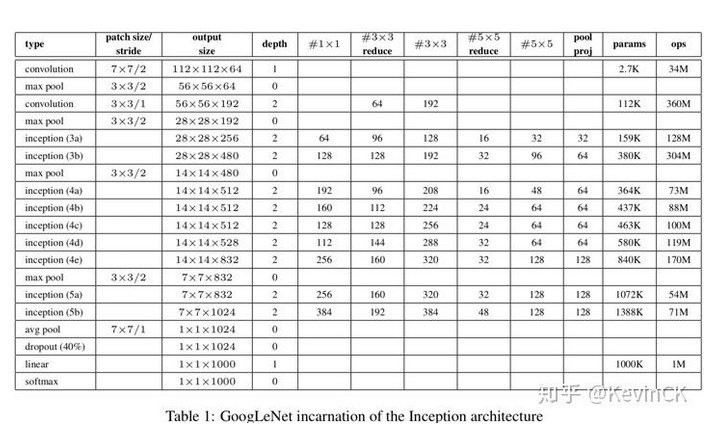
GoogLeNet V1 网络特色:(参考 1, 参考 2)
(1) 采用 Inception 模块化结构,方便添加修改
(2) 采用 Average Pool 来代替全连接层(借鉴 Network in Network),实际在最后一层还是添加了一个全连接层,方便做 finetune。
(3) 另外增加了两个辅助的 softmax 分支 (incetion 4b 和 4e 后面),作用有两点,一是为了避免梯度消失,用于向前传导梯度。反向传播时如果有一层求 导为 0,链式求导结果则为 0。二是将中间某一层输出用作分类,起到模型融合作用。最后的 loss=loss_2 + 0.3 _ loss_1 + 0.3 _ loss_0。实际测 试时,这两个辅助 softmax 分支会被去掉。
4.2 GoogLeNet V2, V3
GoogLeNet V2, V3 是在 2015 年论文 Rethinking the Inception Architecture for Computer Vision 中提出,主要是对 V1 的改进。
GoogLeNet v2 的 Inception 结构和整体的架构如下:
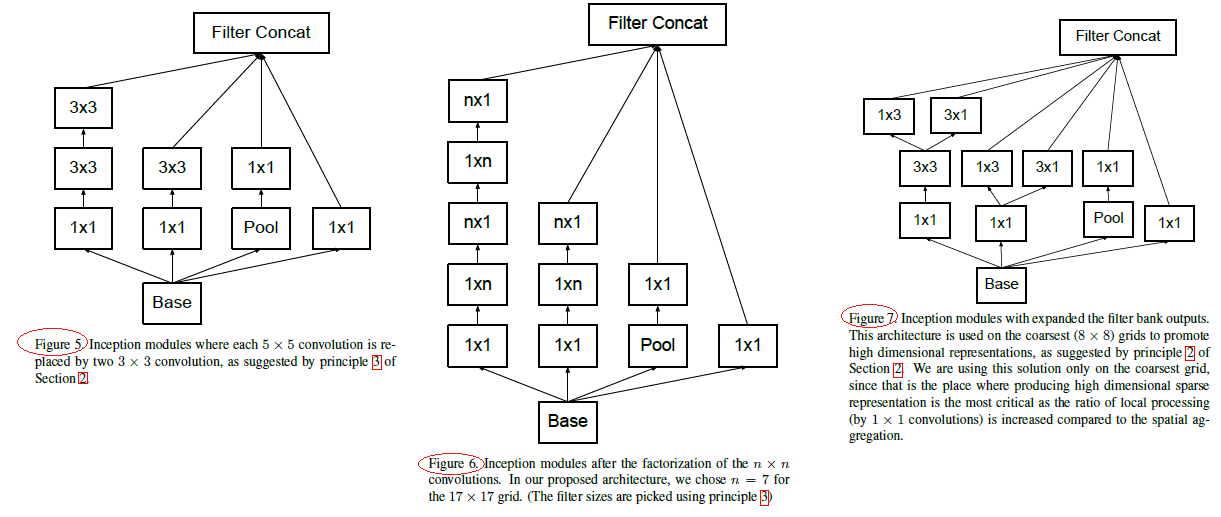
** GoogLeNet V2 网络特点:**
(1) 借鉴 VGG,用两个 3*3 卷积代替一个 5*5 卷积,降低参数量,提高计算速度(如上图 Figure5 中 Inception)
(2) 它们将滤波器大小 nxn 的卷积分解为 1xn 和 nx1 卷积的组合(7x7 卷积相当于首先执行 1x7 卷积,然后在其输出上执行 7x1 卷积,如上图 Figure6 中 Inception),但在网络的前期使用这种分解效果并不好,在中度大小的特征图(feature map)上使用效果才会更好(特征图大小建议在 12 到 20 之间)
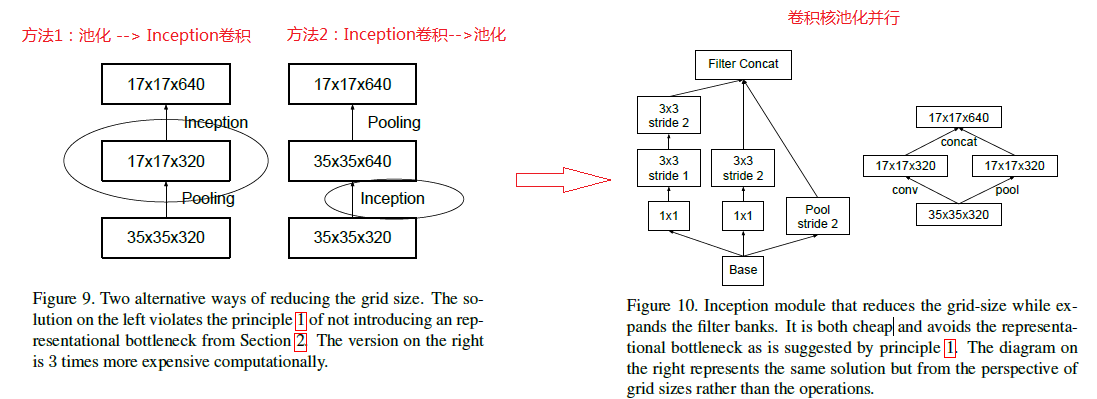
(3) 为了同时保持特征表示并降低计算量,将池化和卷积并行执行再合并,如下图所示:
GoogLeNet V3: V3 包含了为 V2 规定的所有上述改进,另外还使用了以下内容:
(1) 采用 RMSProp 优化器
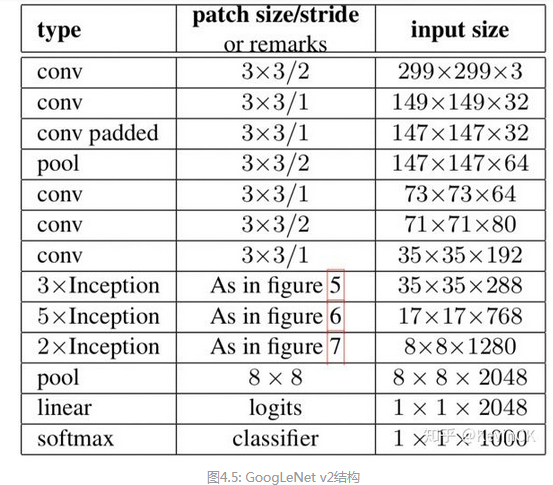
(2) 学习 Factorization into small convolutions 的思想,将 7x7 分解成两个一维的卷积(1x7,7x1),3x3 也是一样(1x3,3x1),这样的好处,既可以加 速计算(多余的计算能力可以用来加深网络),又可以将 1 个 conv 拆成 2 个 conv,使得网络深度进一步增加,增加了网络的非线性,还有值得注 意的地方是网络输入从 224x224 变为了 299x299,更加精细设计了 35x35/17x17/8x8 的模块。
(3) 在辅助分类器中的使用 BatchNorm。
(4) 采用标签平滑(添加到损失公式中的一种正规化组件,可防止网络对类过于自信。防止过度拟合)
** 4.3 GoogLeNet V4**
GoogLeNet V4(Inception V4) 是在 2016 年的论文 Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning 中提出,主要是利用残差网络(ResNet)来改进 V3,得到 Inception-ResNet-v1,Inception-ResNet-v2,Inception-v4 网络。
5. ResNet
ResNet 是何凯明在 2015 年的论文Deep Residual Learning for Image Recognition 中提出,ResNet 网络提出了残差网络结构,解决了以前深层网络难训练的问题,将网络深度有 GoogLeNet 的 22 层提高到了 152 层。残差网络 (bottleneck) 的结构如下:(参考 1)
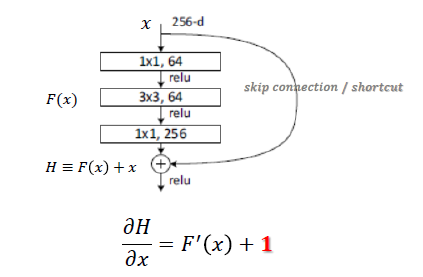
相比传统网络:y=f(x),ResNet Block 公式为:y=f(x) + x,可以称之为 skip connect。有两个点需要思考下:一是其导数总比原导数加 1,这样即使原导数很小时,也能传递下去,能解决梯度消失的问题; 二是 y=f(x) + x 式子中引入了恒等映射(当 f(x)=0 时,y=2),解决了深度增加时神经网络的退化问题。
ResNet 由多个 Residual Block 叠加成的,其结构如下:
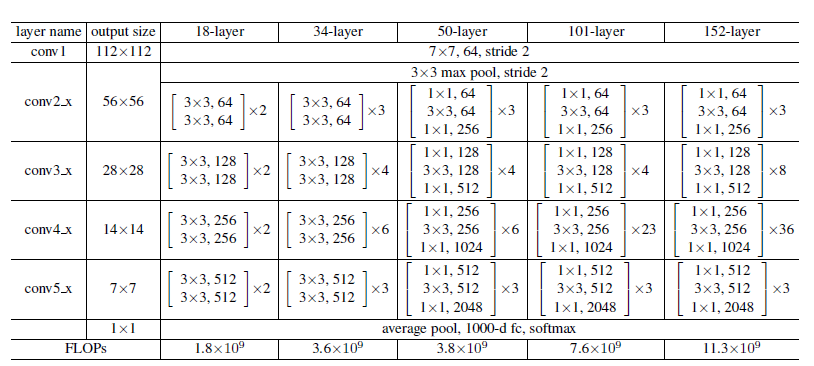
其中 Resnet-18/34 采用的 residual block 和 Resnet-50/101/152 不太一样,分别如下所示:
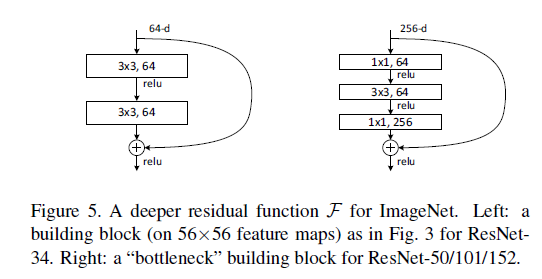
除了残差结构,ResNet 还有两个细节需要关注下:
(1) 第一个卷积层采用了 7*7 的大卷积核,更大的感受野,获取图片更多的初始特征(primary feature) (图片 channel=3,第一层使用大 kernel,增加的参 数量不是很大)
· (2) 短路连接中,输入和输出维度不一致时,不能直接相加(Element-wise add),采用步长为 2 的卷积来减小维度尺寸?
6. DenseNet
DenseNet 网络是在 2017 的论文 Densely Connected Convolutional Networks 中提出,与 ResNet 一致,也采用 shortcut 连接,但是其将前面所有层与后面层密集连接(dense connection), 另外其采用 channel concatenate 来实现特征重用(代替 ResNet 的 Element-wise addition)。其整体网络结构如下图所示: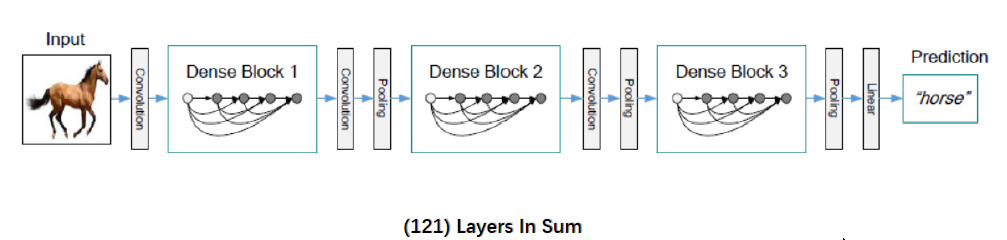
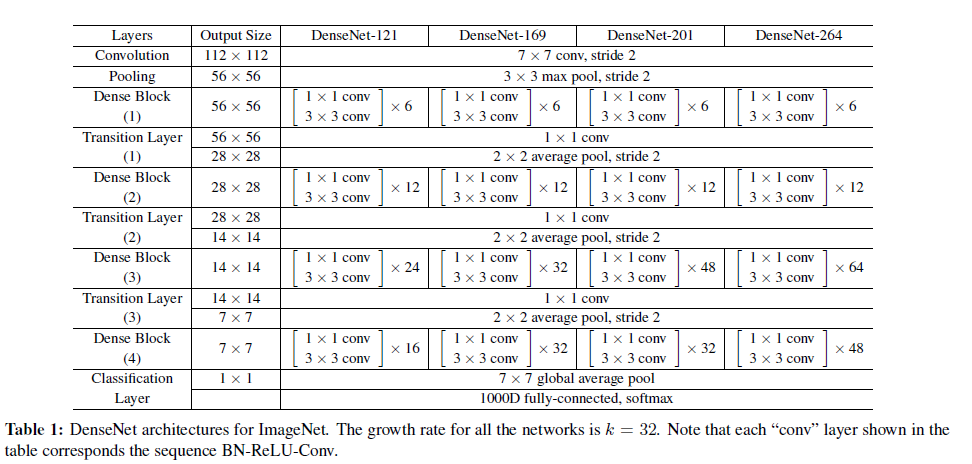
DenseNet 网络包括 Dense Block 和 Transition layer 两个基础模块,Dense Block 类似于 ResNet 中的 residual block,其区别对比如下:

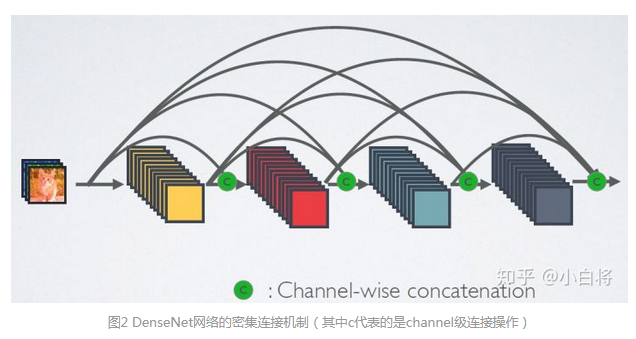
** 由上图可以发现两个主要区别**:(参考 1)
(1) DenseNet 是密集连接,前面层和后面层间都有连接;ResNet 只有相邻层有连接
(2) DenseNet 是 channel-wise concatenation; Resnet 是 Element-wise addition
DenseNet 的 Transition layer 主要是用来降低 feature map 的尺寸,将来自不同层的 feature map 变化为同等尺寸后进行 concatenate,其结构如下:
BN + ReLU+1*1 Conv + 2*2 Average Pool
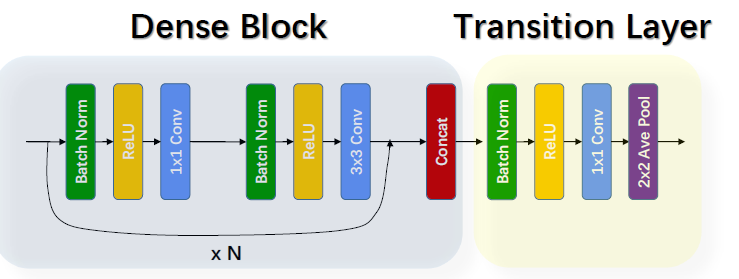
DenseNet 的特点:
(1) 由于密集连接方式,DenseNet 提升了梯度的反向传播,使得网络更容易训练 (每层可以直达最后的误差信号)
(2) 参数更小且计算更高效 (concatenate 来实现特征复用,计算量很小)
(3) 由于特征复用,分类器使用到了低级特征
(4) 需要较大的显存才能运行(所有层都需存储?)
参考:https://zhuanlan.zhihu.com/p/66215918
https://zhuanlan.zhihu.com/p/22038289
上述都是些大型的经典网络,运行较慢,需要的较大的算力,而轻量级网络则采用不同的设计和模型架构,来应对移动端设备上的使用,目前主要的轻量级网络包括 SqueezzeNet, MobileNet 和 ShuffleNet,其发展历史如下:

这些网络实现轻量级的主要方法如下:
(1) 优化网络结构: shuffle Net
(2) 减少网络的参数: Squeeze Net
(3) 优化卷积计算: MobileNet(改变卷积的顺序); Winograd(改变卷积计算方式)
(4) 删除全连接层: Squeeze Net; LightCNN
** 7. SqueezeNet**
SqueezeNet 是在 2017 年的论文 SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size 中提出, squeezeNet 的模型压缩策略主要有三个:(Idea from GoogLeNet) (参考 1)
(1) 多使用 1*1 的卷积,少使用 3*3 的卷积,减少参数量
(2) 3*3 卷积采用更少的 channel 数
(3) 将降采样后置,即推迟使用 Pooling,从而增加感受野,尽可能多的获得 feature
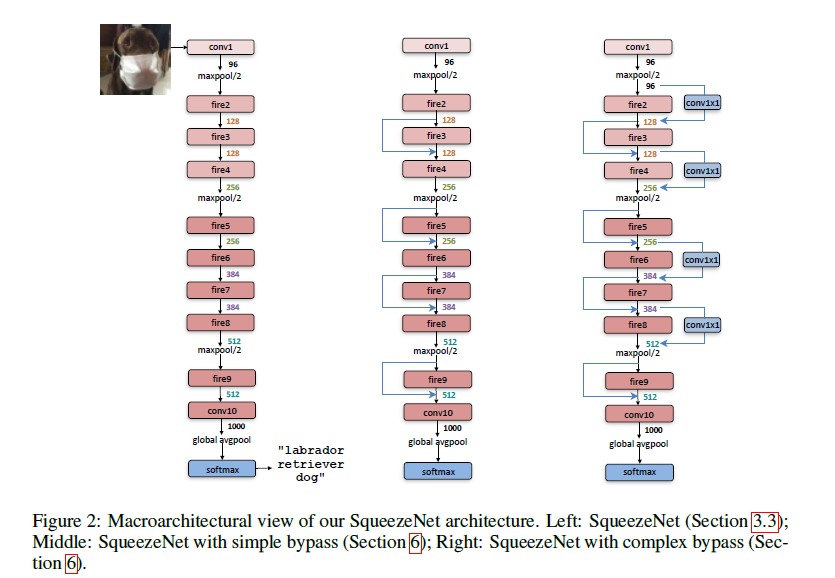
SqueezeNet 的网络基础单元是 Fire Module,多个 fire module 堆叠,结合 pooling 组成 SqueezeNet,如下图所示:(右边两张加入了 shortcut)

Fire Module 又包括两部分:squeeze layer 和 Expand layer,如下图所示:
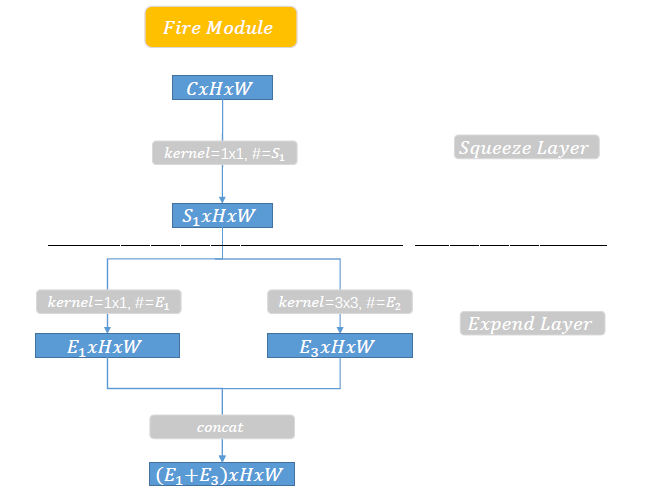
** squeeze layer**:主要是 1*1 的卷积,对网络 channel 进行压缩,卷积核的个数为 S1
expand layer:1*1 的卷积个数为 E1,3*3 的卷积个数为 E3(上图中 E2 应该为 E3),然后进行 concate。
论文中关于 E1, E3,S1 的关系描述如下:

** 8. MobileNet**
8.1 MobileNet V1
MobileNet V1 是在 2017 年 Google 的论文 MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications 中提出,其主要压缩策略是深度可分离卷积 (Depthwise separable Convolution),其包括两步,如下图所示:

(1) 深度卷积:将卷积拆分为单通道的形式,在不改变输入特征图像的深度的情况下,对每一通道进行卷积操作,得到和输入特征图通道数一致的输出特征图。如下图,输入 12×12×3 的特征图,经过 5×5×1×3 的深度卷积之后,得到了 8×8×3 的输出特征图。输入个输出的维度是不变的 3。

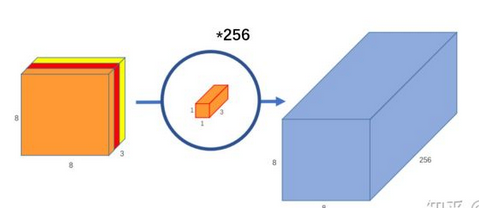
(2)逐点卷积:即 1*1 的卷积,对深度卷积得到的特征图进行升维,如下图,8×8×3 的特征图,通过 1*1*3*256 的卷积,输出 8*8*256 的输出特征图。
参数量和计算量对比:
深度可分离卷积和传统卷积相比操作和参数更少,如下图所示,可以发现深度可分离卷积操作数和参数都是传统卷积的(1/N +1/Dk2), 采用 3*3 卷积时大约是 1/9。(但模型精度大概只降低 1%)

模型结构对比:
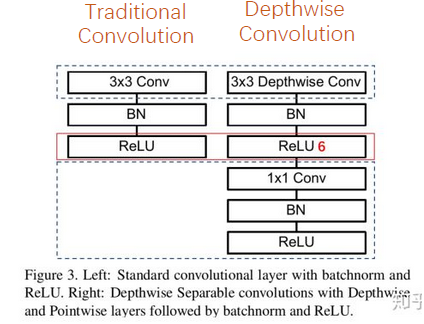
深度可分离卷积单元相比传统卷积多一个 ReLU6 激活函数和 1*1 卷积层,对比如下图:
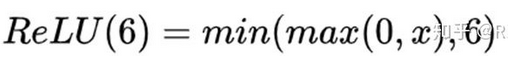
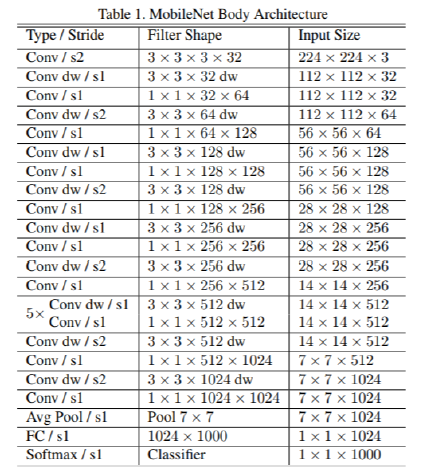
MobileNet V1 网络的整体架构如下图, 多个深度卷积的堆叠(s2 表示步长为 2),: (参考 1)
MobileNet V1 还可以引入结构超参数来进一步压缩网络,主要是在 kernel 的深度和尺寸两方面,如下图:

** 8.2 MobileNet V2**
MobileNet V2 是在 2018 年的论文 MobileNetV2: Inverted Residuals and Linear Bottlenecks 中提出,对 V1 的卷积单元进行了改进,主要引入了 Linear bottleneck 和 Inverted residuals。
(1) Linear bottleneck : 在原始 V1 训练时容易出现卷积层参数为空的现象,这是由于 ReLU 函数:对低维度做 ReLU 运算,很容易造成信息的丢失。而在高维度进行 ReLU 运算的话,信息的丢失则会很少(参考);因此去掉卷积单元中最后一个 ReLU 函数。
(Linear bottleneck: Eltwise + with no ReLU at the end of the bottleneck)
(2) Inverted Residual: 深度卷积本身没有改变 channel 的能力,来的是多少通道输出就是多少通道。如果来的通道很少的话,DW 深度卷积只能在低维度上工作,这样效果并不会很好,所以我们要 “扩张” 通道。既然我们已经知道PW 逐点卷积也就是 1×1 卷积可以用来升维和降维,那就可以在 DW 深度卷积之前使用 PW 卷积进行升维(升维倍数为 t,t=6),再在一个更高维的空间中进行卷积操作来提取特征,随后再进行降维。
(Inverted Residual: expand - transfer - reduce)
对比下 V2 和 ResNet 的结构,如下图:可以发现 V2 是先升,卷积,降维,和 ResNet(降维,卷积,升维)相反,因此成为 Inverted residual.
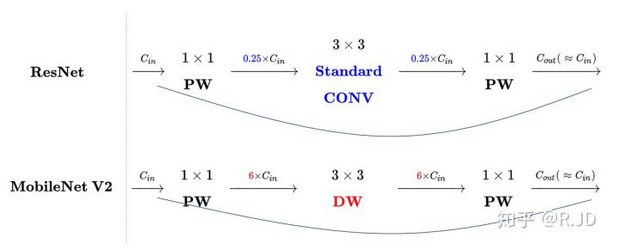
Linear bottleneck 和 Inverted Residual 解释:
对比下 V1 和 V2 的卷积结构单元,如下图:V2 将最后一层的 ReLU6 换成了 Linear,并引入了 shortcut 进行升维和将维 (最右边的 stride=2 减小尺寸,所以没有 shortcut)。
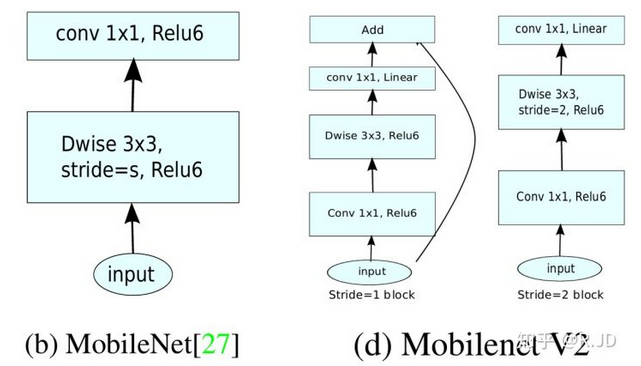
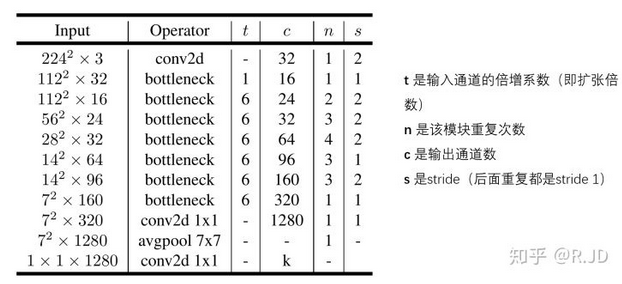
MobileNet V2 的整体结构如下图:
8.3 MobileNet V3
MobileNet V3 在 2019 年的论文Searching for MobileNetV3 中提出,还没啃完,有空来填坑。
** 9 ShuffleNet**
9.1 shuffleNet V1
shuffleNet V1 是 2017 年在论文ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices 中提出的,其主要压缩思路是 group convolution 和 channel shuffle。(参考 1,参考 2)
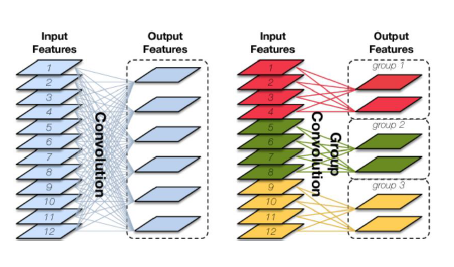
(1) group convolution(分组卷积): 分组卷积的思路是将输入特征图按通道数分为几组,然后采用不同的卷积核再对各个组进行卷积,这样会降低卷积的计算量。传统的卷积是卷积核在所有通道上进行卷积,算全通道卷积,而分组卷积算通道上的稀疏卷积,如下图所示。(mobileNet 算是一种特殊的分组卷积,分组数和通道数一样)
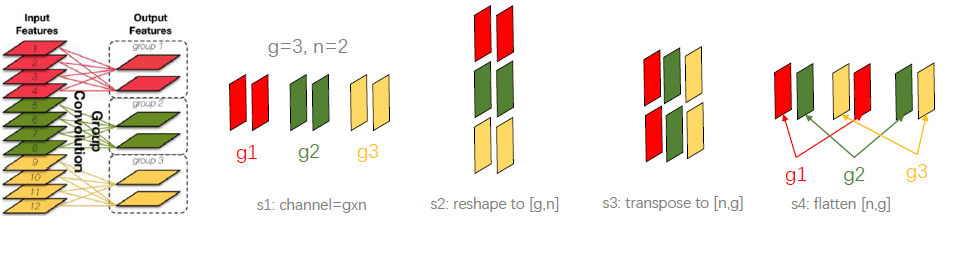
(2)channel shuffle(通道混洗) : 分组卷积以一个问题是不同组之间的特征图信息不通信,就好像分了几个互不相干的路,大家各走各的,会降低网络的特征提取能力。MobileNet 是采用密集的 1*1pointwise convolution 进行通道特征融合,计算量较大。channel shuffle 的思路是对分组卷积之后的特征图的排列顺序进行打乱重新排列,这样下一个分组卷积的输入就来自不同的组,信息可以在不同组之间流转。channel shuffle 的实现步骤如下图所示:reshape--transpose-flatten
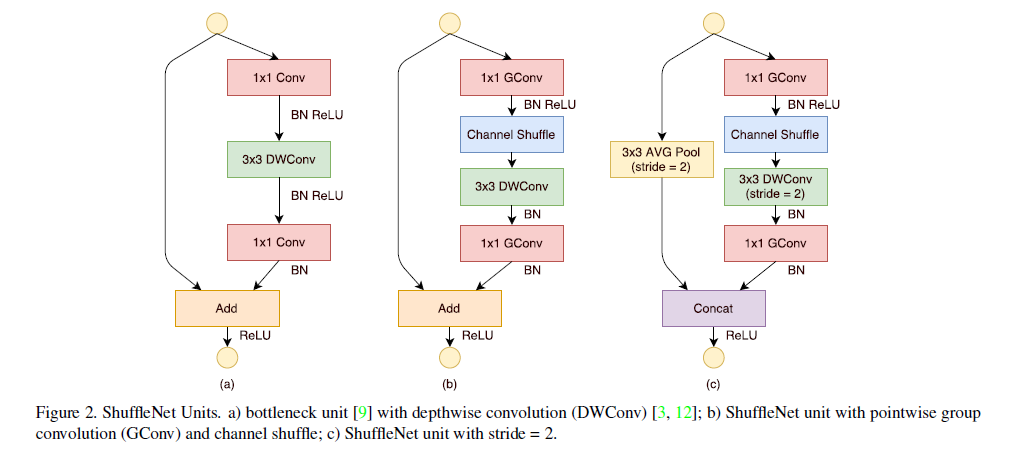
shufflleNet V1 网络的基本单元如下图所示,相比 a 图中,b 图将 1x1 的密集卷积换成分组卷积,添加了一个 channel shuffle,另外 3x3 的 depthwise convolution 之后没有使用 ReLU 激活函数,图 c 中则采用 stride=2,同时将 elment-wise add 换成了 concat。
shuffleNet V1 特点,以及和 ResNet 和 mobileNet 的对比如下:

ShuffleNet V1 的整体架构如下,每个 stage 都是 shuffleNet 基本单元的堆叠。

9.2 shuffleNet V2
shuffleNet V2 是 2018 年在论文ShuffleNet V2: Practical Guidelines for Ecient CNN Architecture Design中提出的, 论文中针对设计快速的轻量级模型提出了四条指导方针(Guidelines):
(1)G1: 卷积层的输入和输出特征通道数相等时 MAC 最小,此时模型速度最快

(2)G2: 过多的 group 操作会增大 MAC,从而使模型速度变慢

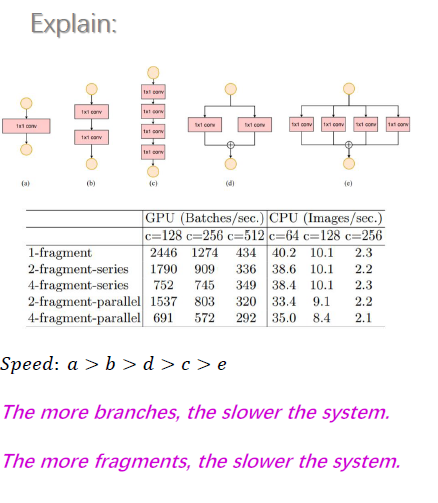
(3) G3: 模型中的分支数量越少,模型速度越快
(4) G4:element-wise 操作所带来的时间消耗远比在 FLOPs 上的体现的数值要多,因此要尽可能减少 element-wise 操作。

论文中接着分析了其他网络模型违背了相应的原则方针,如下图所示:

针对上述四条 guidelines,论文提出 shuffleNet V2 的基本单元,如下图:
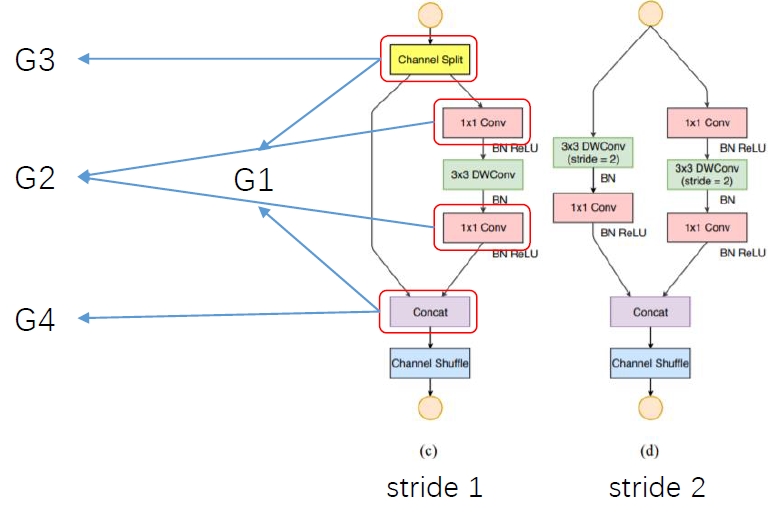
(1) channel split 然后 concat,保证输入输出 channel 一致,遵循准则 1?
(2) 去掉 1*1 的分组卷积 (channel split 相当于分组了),遵循准则 2
(3) channel split 和将 channel shuffle 移动到后面,遵循准则 3?
(4) 利用 concat 代替 add,遵循准则 4
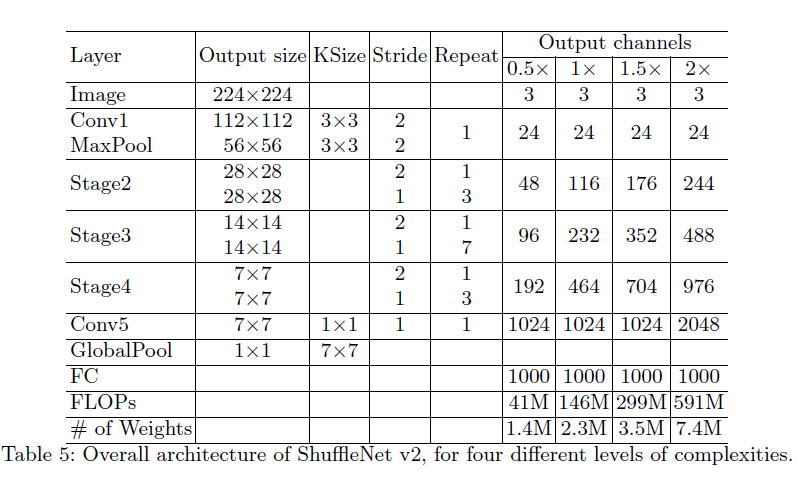
最后 shuffleNet V2 的整体架构如下:
参考:https://baijiahao.baidu.com/s?id=1589005428414488177&wfr=spider&for=pc
https://www.cnblogs.com/silence-cho/p/11620863.html