madobet
![]()
madobet
Python 是非常灵活的语言,其中 `yield` 关键字是普遍容易困惑的概念。 此篇将介绍 `yield` 关键字,及其相关的概念。 ## [](#迭代、可迭代、迭代器 "迭代、可迭代、迭代器")迭代、可迭代、迭代器 ### [](#迭代(iteration)与可迭代(iterable) "迭代(iteration)与可迭代(iterable)")迭代(iteration)与可迭代(iterable) > 迭代是一种操作;可迭代是对象的一种特性。 很多数据都是「容器」;它们包含了很多其他类型的元素。实际使用容器时,我们常常需要逐个获取其中的元素。**逐个获取元素的过程,就是「迭代」**。 \| 1 2 3 4 \| a_list = \[1, 2, 3] for i in...
該不該復育絕種動物,至今還沒有肯定答案。但能肯定的是:如果不加緊腳步保護環境,會有更多動物滅絕。但另一個問題來了,「保護」環境的英文到底該用 conserve、preserve 還是 reserve 呢?這幾個字的意思和用法,你還傻傻分不清嗎?別擔心,今天就跟著希平方好好認識這幾個字,了解它們之間的區別吧! [ ](https://s3-ap-northeast-1.amazonaws.com/hopenglish/wp/wp-content/uploads/2018/10/erve_600.jpg) 圖片來源:[Designed by Asier_relampagoestudio](https://www.freepik.com/free-photo/guy-in-a-blue-jacket-thinking_1020885.htm) ## **conserve / preserve / reserve(動詞)的意思及用法** ### **conserve、preserve 都有「保護」的意思,但程度和方法不太一樣** 作為「保護」時,conserve 跟 preserve 經常被當作同義詞,例如: **Action to conserve / preserve the environment...
NVIDIA 去年发布了一个线上讲座,题目是《 AI at the Edge TensorFlow to TensorRT on Jetson 》。 我们将视频翻译并用笔记的方式分享给大家。 完整内容主要介绍使用 TensorFlow 开发的深度神经网络如何部署在 NVIDIA Jetson 上,并利用 TensorRT 加速到 5 倍。 您将了解到: 1.TensorFlow 性能如何与使用流行模型(如 Inception 和 MobileNet)的 TensorRT...
【阅读时间】7min - 9min 【内容简介】主要解决**什么是正则化,为什么使用正则化,如何实现正则化**,外加一些对**范数**的直观理解并进行知识整理以供查阅 我们总会在各种地方遇到**正则化**这个看起来很难理解的名词,其实它并没有那么高冷,是很好理解的 首先,从**使用正则化解决了一个什么问题**的角度来看:**正则化是为了防止过拟合, 进而增强泛化能力**。用白话文转义,**泛化误差**(generalization error)= 测试误差(test error),其实就是使用训练数据训练的模型在测试集上的表现(或说性能 performance)好不好 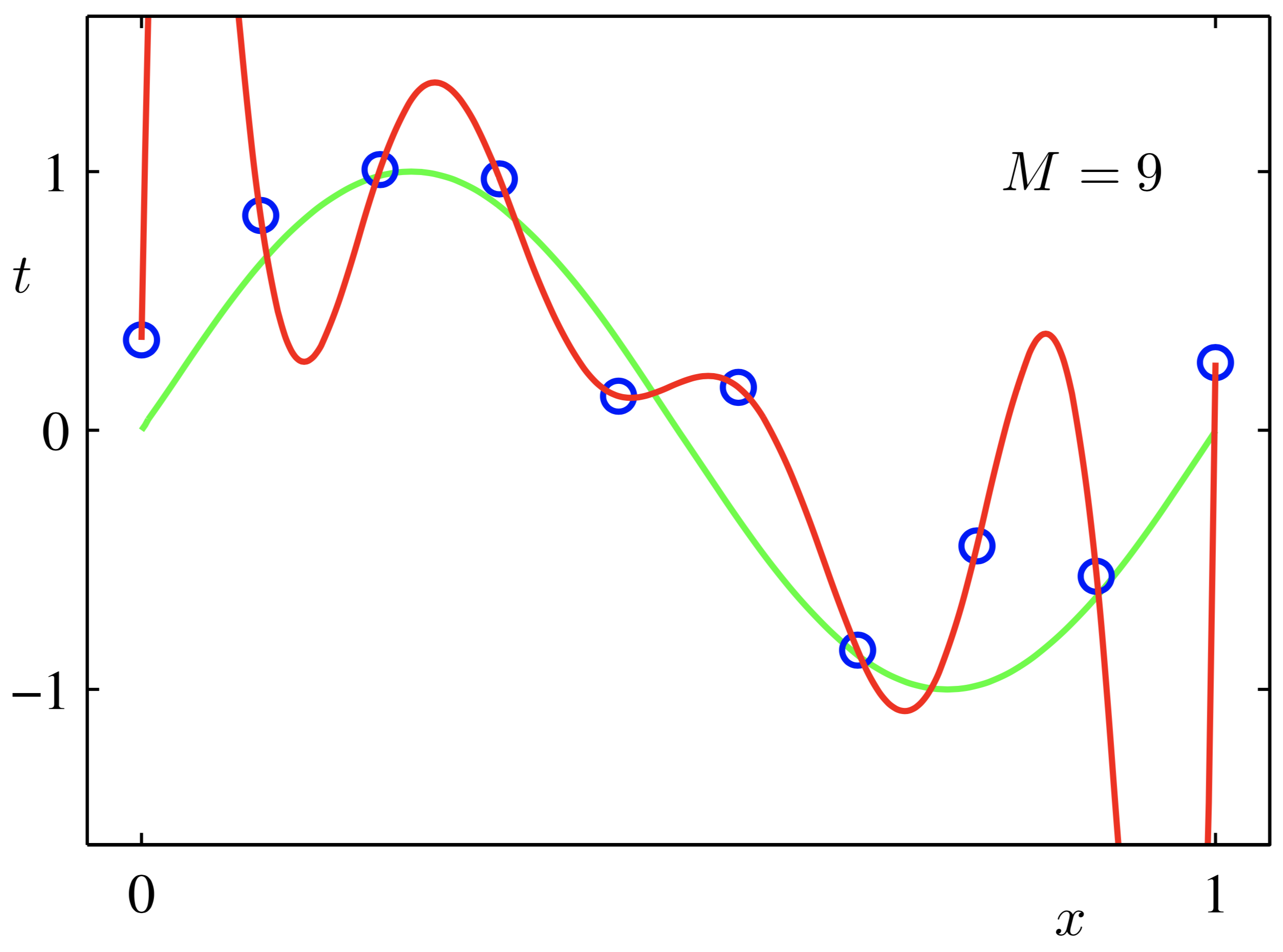 如上图,红色这条 “想象力” 过于丰富上下横跳的曲线就是过拟合情形。结合上图和正则化的英文 Regularizaiton-Regular-Regularize,**直译应该是:规则化**(加个 “化” 字变动词,自豪一下中文还是强)。什么是规则?你妈喊你 6 点前回家吃饭,这就是规则,一个**限制**。同理,在这里,**规则化就是说给需要训练的目标函数加上一些规则(限制),让他们不要自我膨胀**。正则化,看起来,挺不好理解的,追其根源,还是 “正则” 这两字在中文中实在没有一个直观的对应,如果能翻译成**规则化**,更好理解。但我们一定要明白,搞**学术,概念名词的准确是十分重要**,对于一个**重要唯一确定的概念**,为它安上一个不会产生歧义的名词是必须的,正则化的名称没毛病,只是从如何理解的角度,要灵活和类比。 我的思考模式的中心有一个理念:**每一个概念**,**被定义**就是为了去**解决一个实际问题(问 Why&What),接着寻找解决问题的方法(问 How)**,这个 “方法” 在计算机领域被称为 “算法”(非常多的人在研究)。我们无法真正衡量到底是提出问题重要,还是解决问题重要,但我们可以从不同的**解决问题的角度**来思考问题。一方面,**重复**以加深印象。另一方面,具有**多角度的视野**,能让我们获得更多的灵感,真正做到**链接并健壮自己的知识图谱** **对于线性模型来说,无论是 Logistic...
> 人工智能时代下机器学习(machine learning)的相关发明与传统计算机程序发明有显著不同,究竟专利申请人在撰写该类别的专利请求项与说明书时,要如何呈现才能符合专利充分揭露要件? 本文依序从(1)该人工智能或机器学习的发明应用于或解决何种问题、(2)该发明使用何种模式结构(model structure)、(3)该模式结构使用何种算法(algorithm)施以训练、(4)该用于施以训练(training,或称测试)的算法被给予何种数据(data)、(5)该数据受何种超参数(hyperparameters)规制、(6)综合以上软件阶层如何与硬件结合等概念问题解构并说明之。  图片来源:CanStockPhoto. 美国法院将专利法第 112 条第 (a) 项的充分揭露要件区隔为「可据以实现」和「书面说明」两个独立要件,要求专利申请人于说明书应详实揭露发明内容,使所属技术领域具有通常知识者(PHOSITA)得制造及使用该发明技术,各请求项也必须为说明书所支持,所请范围不得超出说明书揭露的内容[\[1\]](#1)。针对软件设计领域具体来看,充分揭露要件对软件发明的要求可着重于(1)检视该发明请求项是否叙述所请软件发明具备的功能,(2)说明书是否阐明如何达到前述请求项对该软件发明具备的功能划出的权利范围。 **机器学习不同于传统计算机程序发明** 未如传统计算机程序发明的运算机制通常可被预测和清楚描绘,机器学习会基于应用基础不同,改变运算过程中的解决方案(solution),故运算过程具不确定性。具体而言,机器学习在运算过程中并非单纯重复地处理数据库问题,其可从接受的数据或经验选取出部份予以优化,故设计者得塑造一具有算法执行的模式(model),并以不同的参数(parameters)给予独立定义;是以,所称「学习」,就是让该模式以设定的算法予以执行。通常设计者会利用「训练用数据」(training data)优化参数,等到训练用数据累积一定程度后,参数价值也因优化结果逐渐提高。换句话说,机器学习的模式是由参数所定义,参数的价值来自训练用数据的持续喂养(feed)、将之优化的结果。因此,不同的训练用的数据或不同的模式设计都将造成机器学习在执行演算后不同的最终结果。 从专利授予的角度言之,机器学习系统的开放性和其缺乏经演绎而不可预测的本质,相较于传统僵化的程序运算对适应新情境或新识别方案时执行效率都较为良好,而这些本质就直接关乎于专利充分揭露要件对请求项和说明书撰写上的要求与检核。 由于一新发明得同时符合不同机器学习的模式结构或训练用算法,故建议该发明可以该模式或算法的「功能特性」请求专利,因此在撰写专利申请时,该专利说明书需完整阐述如何达到该些「功能」或「结果」;更有甚者,由于该些参数价值来自于反复实验性操作而得以优化,因此说明书必须提供足够的解释或范例指引,以证明上述这些操作不需过度实验(undue experimentation)即可达成。 **从经典判决先例出发:解决何种问题、模式结构与算法的揭露** 联邦巡回上诉法院(CAFC)在 1997 年 Genentech, Inc. v. Novo Nordisk A/S 案指出,说明书应揭露包含「特定起始材料(starting material)」和「执行过程的状态或条件」[\[2\]](#1)。此对机器学习发明来说,就是指「要被解决的问题或被使用的模式结构」和「用于优化参数的训练过程和方法」,故说明书应至少揭露适用模式的特性(characteristics)和用于训练该模式的算法,甚且若是超过一种模式或多种算法可以适用该发明,则该些备选模式或算法都应予揭露;另由于「要被解决的问题」可能限制模式或算法的设计,因此该欲解决的目标应也需要明确的指明。...
- 文 / 集佳知识产权代理有限公司 朱静 机器学习(Machine Learning, ML)是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度等多门学科,专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或者技能,重新组织已有的知识结构使之不断改善自身的性能。简单的讲,机器学习是一门人工智能的学科,其主要研究对象是人工智能,特别是如何在经验学习中改善具体算法的性能。 目前,机器学习已经在众多领域得到应用,例如数据挖掘、计算机视觉、自然语言处理、生物特征识别、搜索引擎、证券市场分析、DNA 序列预测以及机器人运用。随着机器学习在各个领域的快速发展,众多企业逐渐投入研发机器学习技术,从而使得几年来涉及机器学习技术的专利越来越多,于此同时,企业对机器学习的专利申请需求也越来越多,因此,如何撰写机器学习技术的专利是目前专利从业人员所关注的重点之一。基于此,笔者根据撰写经验谈一谈涉及机器学习技术的专利申请文件的撰写策略。 机器学习在技术实现时,大致分为模型训练阶段和模型应用阶段,所谓模型训练阶段是指利用机器学习算法对样本数据进行学习以训练模型的阶段,所谓模型应用阶段是指利用训练好的模型对新数据进行预测的阶段。而在实际技术研发过程中,有时会针对模型训练阶段产生相关专利,而有时会针对模型应用阶段产生相关专利,当然,大部分时候是在两个阶段都有相关的改进点,即同时产生相关专利。 基于机器学习技术本身的特点,笔者根据自身撰写经验总结出以下撰写策略: (1)、在实际操作中,先根据交底书明确技术改进点属于哪个阶段,方案仅涉及训练阶段的改进点,还是仅涉及到应用阶段的改进点,还是两者皆有。根据方案的改进点所属的具体阶段部署对应的权项。下面针对不同的情况分别进行说明。 一种情况是,方案仅在模型训练阶段存在改进点,例如,在模型训练阶段涉及到原始数据采集、样本数据挖掘、特征提取、模型内部结构变化、模型参数更新算法以及模型组合训练等一个或者多个方面,方案若在这些方面作了改进,针对这种情况,则仅部署模型的训练方法以及产品等相关权项。 另一种情况是,方案仅在模型应用阶段存在改进点,例如,在模型应用阶段一般会涉及到数据采集、特征提取、模型内部结构变化、模型输出结果应用以及模型组合应用等一个或者多个方面,方案若在这些方面作了改进,则仅部署模型的应用方法以及产品等相关权项。 还有一种情况是,方案既涉及模型训练阶段又涉及模型应用阶段,例如:方案涉及到模型内部结构的改进,则既需要部署模型训练的方法还需要部署模型应用的方法以及相关产品等权项。 (2)、在确定应部署的权项主题之后,再确定具体改进点所属的特定环节,根据特定环节定位出合理的权项范围,而无需站在模型训练过程或者模型应用过程的全局角度进行定位,以避免丧失权利。下面进行举例说明。 一种情况是,有些方案仅仅涉及训练阶段的某一个独立环节的改进,则可以将方案定位到具体的独立环节,而无需站在整个训练过程进行全局定位,这样能够确定出合理的权项范围。 例如:有些方案仅涉及模型训练阶段中样本数据采集方面的改进,则可以将权项范围定位在样本数据采集的范围即可,具体在撰写时,方法权要的步骤描述出如何采集样本数据以完整表征改进点即可,可以跳出交底书中限定的特定模型下的训练场景,基于此,也可以对方案进行场景性扩展,以及训练过程中其他环节的扩展。但在从权中可以通过名词限定或者增加方法步骤的方式进一步地保护样本数据应用于具体模型训练的方案,以保证交底书中提供的最佳场景应用的方案。例如,在从权中采用功能性限定,如所述样本数据用于某某模型训练,或者利用所述样本数据对某某模型进行训练。 另一种情况是,有些方案仅仅涉及训练阶段中损失函数部分的改进,而此部分也无法作为独立的方案,基于此,可以根据该改进点所处的具体环节,或者与其直接相关的环节,确定权项合理的范围;在机器学习中损失函数部分会涉及构建目标函数以及利用目标函数进行模型参数优化环节,基于此,可以将权项范围定位到这两个环节相结合所组成的范围,而无需站在训练过程全局角度进行定位,也不能定位到函数本身的范围,即不能盲目缩小范围至丧失技术方案本身所需的素材导致不属于保护客体,也不能局限于整个实际方案实现的场景,这样才能够确定出合理的权项范围。 (3)、在实际操作中,大部分涉及机器学习技术的方案会同时涉及到模型训练以及模型应用两个阶段的改进,针对此情况,考虑到实际维权阶段的相关问题,建议先从模型应用角度部署相关权项,再从模型训练角度部署相关权项。这主要是因为,一方面模型应用相比模型训练更容易取证,由于模型训练一般仅在后台完成,而模型应用则有可能由前台完成,供用户使用。因此,模型应用相比模型训练更容易取证。另一方面,模型应用的市场价值也远远大于模型训练的市场价值,例如,有时模型训练可能一次性完成,而一旦模型在训练好之后是会被重复应用,而且很容易被移植应用;在实际应用中,有的企业主要负责模型算法研究进行模型训练,从而为其他多家企业提供训练好的模型,则其他多家企业会同时应用这一模型实现其产品功能。也就是说,模型应用再现的可能性比模型训练再现的可能性要高的多。因此,建议优先考虑构建模型应用的权利要求,再考虑构建模型训练的权利要求。 另外,还考虑到专利申请经费或者维权等各种问题,在实际撰写过程中,也可以将模型训练过程作为模型应用权项的从属权项进行部署。例如,权 1 是一种模型应用方法,而权 2 引用权 1,进一步增加关于如何训练权 1 中的模型的方案。 (4)、在实际操作中,也会遇到有些案件虽然提及到机器学习技术,但其仅是利用了已有的模型进行相应处理,对模型训练以及模型应用均为作改进,因此,针对这种类型的案件,在撰写时,可以不写模型的训练,也无需关注模型的具体网络结构,可以把模型当作能够实现特定数据处理的,具有一定输入输出映射功能的黑盒处理即可,无需浪费过多笔墨,而把重点放在方案的实际改进点。 ...
文章来源:企鹅号 - 华进知识产权 加关注▲ 微信号:华进知识产权 **华进全新专栏:《知产研究所》第 19 期** **作者:李文渊 国内专利事业部** 目前 AI(Artificial Intelligence,人工智能)这个话题可谓非常热门,时不时就能够看到关于 AI 的新闻。AI 好像无所不能,能对话、能开车、能下棋、能送快递还能看病,好像有逐渐取代人类的趋势。说不定将来 AI 还能自动检索专利文献、撰写专利申请文件、答复审通等等,不免有种快要失业的危机感。  机器学习是一种实现 AI 的方法,随着 AI 的蓬勃发展,涉及机器学习的专利申请需求也愈来愈多,文本作者结合工作经验谈一谈涉及机器学习的方案如何申请专利。当然,机器学习本身涉及的知识非常广阔,作者也仅能够了解其中一角,如有纰漏之处还请批评指正。  目前机器学习的实现,主要是用样本数据训练模型,让模型学习到样本数据中蕴含的内在规律,然后用训练好的模型对新数据进行预测。在这个实现过程中,主要分为模型训练和模型应用两大阶段。模型训练可能涉及数据清洗、特征提取、模型内部结构变化、模型参数更新算法以及模型组合训练等阶段。模型应用则可能涉及数据采集、特征提取、模型内部结构变化、模型输出结果应用以及模型组合应用等阶段。可见,**模型训练和模型应用存在交集也存在差异。** 以下主要从整体上说明撰写涉及机器学习的专利申请文件时需要考虑的因素: **1** 明确改进之处。**上述模型训练和模型应用的各个阶段,都可以进行改进。**因此,布局权利要求时,需要考虑哪个或哪些阶段做了改进,改进的阶段具体做了哪些改进,改进的重点在哪里,以及改进之处彼此间的关联,等等。**明确了这些改进之处,就基本可以据此确定权利要求的布局。** **2**...
在现代深度学习算法研究中,通用的骨干网 + 特定任务网络 head 成为一种标准的设计模式。比如 VGG + 检测 Head,或者 inception + 分割 Head。 在移动端部署深度卷积网络,无论什么视觉任务,选择高精度的计算量少和参数少的骨干网是必经之路。这其中谷歌家去年发布的 MobileNetV2 是首选。 在 MobileNetV2 论文发布时隔一年 4 个月后,MobileNetV3 来了! 这必将引起移动端网络升级的狂潮,让我们一起来看看这次又有什么黑科技! 昨天谷歌在 arXiv 上公布的论文《Searching for MobileNetV3》,详细介绍了 MobileNetV3 的设计思想和网络结构。...
上一篇文章对人工智能最基础的东西进行了介绍,接下来对其中的几个重要领域进行更深入的描述。首先是计算机视觉。计算机视觉是机器认知世界的基础,也是最主要的人工智能技术之一。 **一、定义** 【百度百科】计算机视觉是一门研究如何使机器 “看” 的科学,更进一步的说,就是指用摄影机和电脑代替人眼对目标进行识别、跟踪和测量等机器视觉,并进一步做图形处理,使电脑处理成为更适合人眼观察或传送给仪器检测的图像。计算机视觉也可以看作是研究如何使人工系统从图像或多维数据中 “感知” 的科学。 人类认识了解世界的信息中 91% 来自视觉,同样计算机视觉成为机器认知世界的基础,终极目的是使得计算机能够像人一样 “看懂世界”。目前计算机视觉主要应用在人脸识别、图像识别方面(包括静态、动态两类信息)。 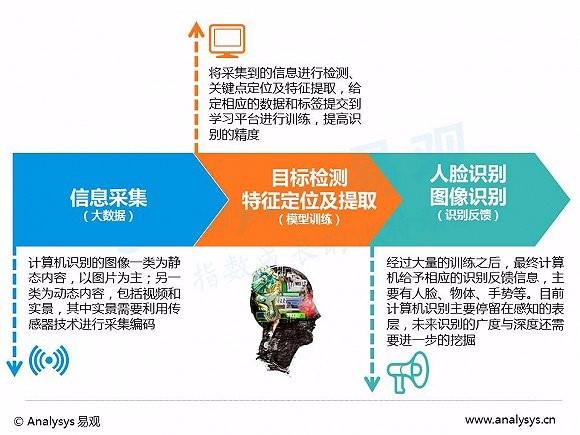 与计算机视觉容易混淆的另一个概念是机器视觉,这两者其实有很大不同。 机器视觉就是用机器代替人眼来做测量和判断。机器视觉系统是通过图像摄取装置将被摄取目标转换成图像信号,传送给专用的图像处理系统,得到被摄目标的形态信息,根据像素分布和亮度、颜色等信息,转变成数字化信号;图像系统对这些信号进行各种运算来抽取目标的特征,进而根据判别的结果来控制现场的设备动作。 从学科分类上,二者都被认为是 Artificial Intelligence 下属科目,不过计算机视觉偏软件,通过算法对图像进行识别分析,而机器视觉软硬件都包括(采集设备,光源,镜头,控制,机构,算法等),指的是系统,更偏实际应用。 **二、计算机视觉的发展历程** 从 2006 年开始,在将近 10 年的时间里,整个计算机视觉界发生了一个比较本质的变化,也是人工智能带来的核心本质的变化——深度学习的出现。深度学习的出现真正改变了计算机视觉之前的定义。那么,这种改变到底是怎样带来的,它对我们解决现在的特定问题会带来什么样的影响呢?要解决这样的问题,先要看一下整个计算机视觉的发展历程。  计算机视觉的发展历史可以追溯到 1966 年,在这一年有一个非常有名的人工智能学家,叫马文 · 明斯基。在...
## 前言 今天,我们来聊一聊知识图谱中的 Neo4J。首先,什么是知识图谱?先摘一段百度百科: > 知识图谱(Knowledge Graph),在图书情报界称为知识域可视化或知识领域映射地图,是显示知识发展进程与结构关系的一系列各种不同的图形,用 可视化技术描述知识资源及其载体,挖掘、分析、 构建、绘制和显示知识及它们之间的相互联系。 知识图谱是通过将应用数学、 图形学、信息可视化技术、 信息科学等学科的理论与方法与计量学引文分析、共现分析等方法结合,并利用可视化的图谱形象地展示学科的核心结构、发展历史、 前沿领域以及整体知识架构达到多学科融合目的的现代理论。它能为学科研究提供切实的、有价值的参考。 简单说来,知识图谱就是通过不同知识的关联性形成一个网状的知识结构,而这个知识结构,恰好就是人工智能 AI 的基石。当前 AI 领域热门的计算机图像、语音识别甚至是 NLP,其实都是 AI 的`感知`能力,真正 AI 的`认知`能力,就要靠知识图谱。 知识图谱目前的应用主要在搜索、智能问答、推荐系统等方面。知识图谱的建设,一般包括数据获取、实体识别和关系抽取、数据存储、图谱应用都几个方面。本文着眼于数据存储这块,给大家一个 Neo4J 的快速教程。 * * * ##...