mlx
 mlx copied to clipboard
mlx copied to clipboard
Add extendable filter categories
Is your feature request related to a problem? Please describe. As of now, MLX can't replicate MAX/DAX as fields in the metadata are missing
Describe the solution you'd like Please add the following meta data field to all asset types:
metadataof typeJSON
Describe alternatives you've considered Alternatively, metadata for each asset type is static which would make MLX highly inflexible to adjust to the needs of different organizations
Related work items:
- [x] API: https://github.com/machine-learning-exchange/mlx/pull/183
- [ ] UI: @drewbutlerbb4
- [ ] Katalog: https://github.com/machine-learning-exchange/katalog/pull/16
We already have metadata fields with established structure and meaning for Components, Datasets, Notebooks where the metadata child attributes are annotations, labels, tags.
The precedence here is Kubernetes and the Kubeflow Pipelines' Component spec:
Metadata
name: Human-readable name of the component.
description: Description of the component.
metadata: Standard object's metadata:
annotations: A string key-value map used to add information about the component. Currently, the annotations get translated to Kubernetes annotations when the component task is executed on Kubernetes. Current limitation: the key cannot contain more that one slash ("/"). See more information in the Kubernetes user guide.labels: Deprecated. Useannotations.
https://github.com/kubeflow/pipelines/blob/e21ea18/sdk/python/kfp/components/_structures.py#L349-L371
class MetadataSpec(ModelBase):
def __init__(self,
annotations: Optional[Dict[str, str]] = None,
labels: Optional[Dict[str, str]] = None,
):
super().__init__(locals())
class ComponentSpec(ModelBase):
'''Component specification. Describes the metadata (name, description, annotations and labels), the interface (inputs and outputs) and the implementation of the component.'''
def __init__(
self,
name: Optional[str] = None, #? Move to metadata?
description: Optional[str] = None, #? Move to metadata?
metadata: Optional[MetadataSpec] = None,
inputs: Optional[List[InputSpec]] = None,
outputs: Optional[List[OutputSpec]] = None,
implementation: Optional[ImplementationType] = None,
version: Optional[str] = 'google.com/cloud/pipelines/component/v1',
#tags: Optional[Set[str]] = None,
):
super().__init__(locals())
self._post_init()
I suggest we add that already established metadata attribute and structure to Models.
However, since we are not in control of the Pipelines metadata (Tekton YAML), we cannot easily extend that mechanism to Pipeline assets.
The existing metadata field is stored as longtext in MySQL (as there was some precedence for that in the parameters field of the pipelines table in KFP). We could change that attribute type to JSON to allow for indexing and search.
Following the Kubernetes methodology, i.e. https://kubernetes.io/docs/concepts/overview/working-with-objects/labels/ ...
Labels are key/value pairs that can be attached to Kubernetes objects such as Pods and ReplicaSets. They can be arbitrary, and are useful for attaching identifying information to Kubernetes objects.
Annotations, on the other hand, provide a storage mechanism that resembles labels but are not used internally by k8s: annotations are key/value pairs designed to hold non-identifying information that can be leveraged by tools and libraries. The value of an annotation can be small or large, structured or unstructured, and can include characters not permitted by labels.
Tags are simple string values (as opposed to key/value pairs) stored in an array or list as opposed to a map or dictionary
So for the purposes of categorizing, searching/filtering MAX models and DAX datasets I suggest we use metadata.annotations
These are the filter categories I see for MAX models: https://developer.ibm.com/exchanges/models/all/
Models
- Trainable
- Deployable
Architectures & Deployment models
- Serverless
Model Asset Technologies
- Image Classification
- Audio Classification
- Audio Feature Extraction
- Audio Modeling
- Image Feature Extraction
- Image-to-Image Translation or Transformation
- Image-to-Text Translation
- Language Modeling
- Show more
Products & Services
- Docker
- Keras
- MAX - Model Asset eXchange
- PyTorch
- TensorFlow
Technologies
- Artificial intelligence
- Deep learning
- Machine learning
- Natural language processing
- Speech and empathy
- Visual recognition
These are the filter categories I find for DAX Datasets https://developer.ibm.com/exchanges/data/all/
Data Asset Technologies
- Audio
- Classification
- Computational Argumentation
- Debater
- DevOps
- Document Layout Analysis
- Feature Extraction
- Image
- Show more
Products & Services
- DAX - Data Asset eXchange
Technologies
- Artificial intelligence
Both the MAX and DAX filter categories need to be refined as they seem to be somewhat overlapping or vague. The filter categories for https://huggingface.co/datasets are much more concise, like task, language, size, license,
Hey @ckadner thanks for this elaboration - fully agree with using something existent if possible, from the documentation it seems that https://kubernetes.io/docs/concepts/overview/working-with-objects/labels/ is (semantically) what we need, but to me it seems "value" can only be of type "string", so when using https://kubernetes.io/docs/concepts/overview/working-with-objects/annotations/, it says "Annotations, like labels, are key/value maps:" - but again, not telling us if values are limited to strings
in that case we can't specify one asset belonging to multiple groups unless multiple entries with the same key are permitted which counter-indicates the term "key"
seems that https://kubernetes.io/docs/concepts/overview/working-with-objects/labels/ is (semantically) what we need
Labels are used by Kubernetes for queries, watches, for use in UIs and CLIs. Non-identifying information should be recorded using annotations.
"Annotations, like labels, are key/value maps:" - but again, not telling us if values are limited to strings
Annotation values are strings. We cannot use numeric, boolean, list or other types. But they can be stringified JSON dictionaries or arrays, string containing comma-separated lists or string-wrapped numbers, etc.
I don't think that would be an issue if we want to use annotations for adding categories for filtering
we can't specify one asset belonging to multiple groups
we can emulate that by using stringified list values like the tags used in TektonHub
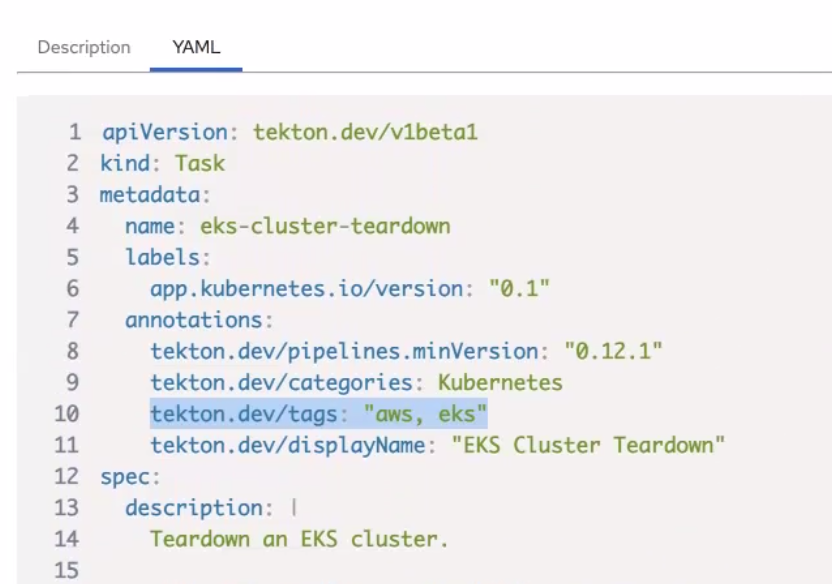
Furthermore, we are not intending to actually use these annotations to annotate Kubernetes resources. So for the purpose of filtering assets within MLX we would not technically have to abide by Kubernetes standards.
As MLX anyway is very tied to Kubernetes/Kubeflow I suggest to go with that solution for now - I think having MLX less tied to Kubenetes/Kubeflow would be a good thing but this is another discussion
The way you've proposed the solution works for our use case and it seems to me that sticking to those standards saves some time on your side as you can re-use existing code/concepts.
@singhan suggested to add a new top-level YAML attribute like categories instead of using metadata.annotations which may not be intuitive to users who are not working with Kubernetes labels and annotations.
Even though the MLX API currently supports the Kubernetes style metadata with labels and annotations, it is not being utilized by the MLX UI except for Notebook. Nor do we use it to annotate Kubernetes resources.
@romeokienzler since the asset YAML is all "metadata" anyway it makes not a lot of sense to create a metadata attribute.
Can we narrow down the focus of this requirement to adding tags or labels for the sake of labeling and filtering assets in the MLX UI.
Would a simple list of tags or labels suffice, i.e.
tags:
- kubernetes
- image-recognition
- sentiment-analysis
- dev-ops
Or do we need key-value pairs like ...
filter_categories:
language: "python"
domain: "image-recognition"
platform: "kubernetes"
@ckadner we need the latter including n:m mapping, either like this:
filter_categories:
language: "python"
language: "bash"
domain: "image-recognition"
platform: "kubernetes"
or like this
filter_categories:
language: ["python","bash"]
domain: "image-recognition"
platform: "kubernetes"
or any other feasible means of achieving this requirement
For assets that tick more than one checkbox in a given category, it would look like either of these:
filter_categories:
language: ["python", "bash"] # flow style
domain: "image-recognition"
platform: "kubernetes"
filter_categories:
language: # block style
- "python" # block style
- "bash" # block style
domain: "image-recognition"
platform: "kubernetes"
@drewbutlerbb4 -- https://hub.tekton.dev/ here has a nice way of pulling out categories into a left-hand side filter menu